Clear Sky Science · sv
Flodutsökning från högupplösta fjärranalysbilder baserat på icke‑uniform provtagning och semisupervised inlärning
Varför det spelar roll att kartlägga floder från rymden
Floder formar våra åkrar, städer och översvämningsslätter, men fältövervakning är dyrt och ojämnt. Dagens jordobservationssatelliter kan fotografera varje krök och sidokanalen i häpnadsväckande detalj, men att omvandla dessa bilder till rena, pålitliga flodkartor är fortfarande en teknisk utmaning. Denna studie presenterar ett nytt sätt att automatiskt spåra floder i högupplösta satellitbilder, med målet att ge mer exakt information för bevattningsplanering, översvämningsvarningar, ekosystemskydd och vattenresurshantering — samtidigt som den minskar mängden manuell märkning som vanligtvis krävs.
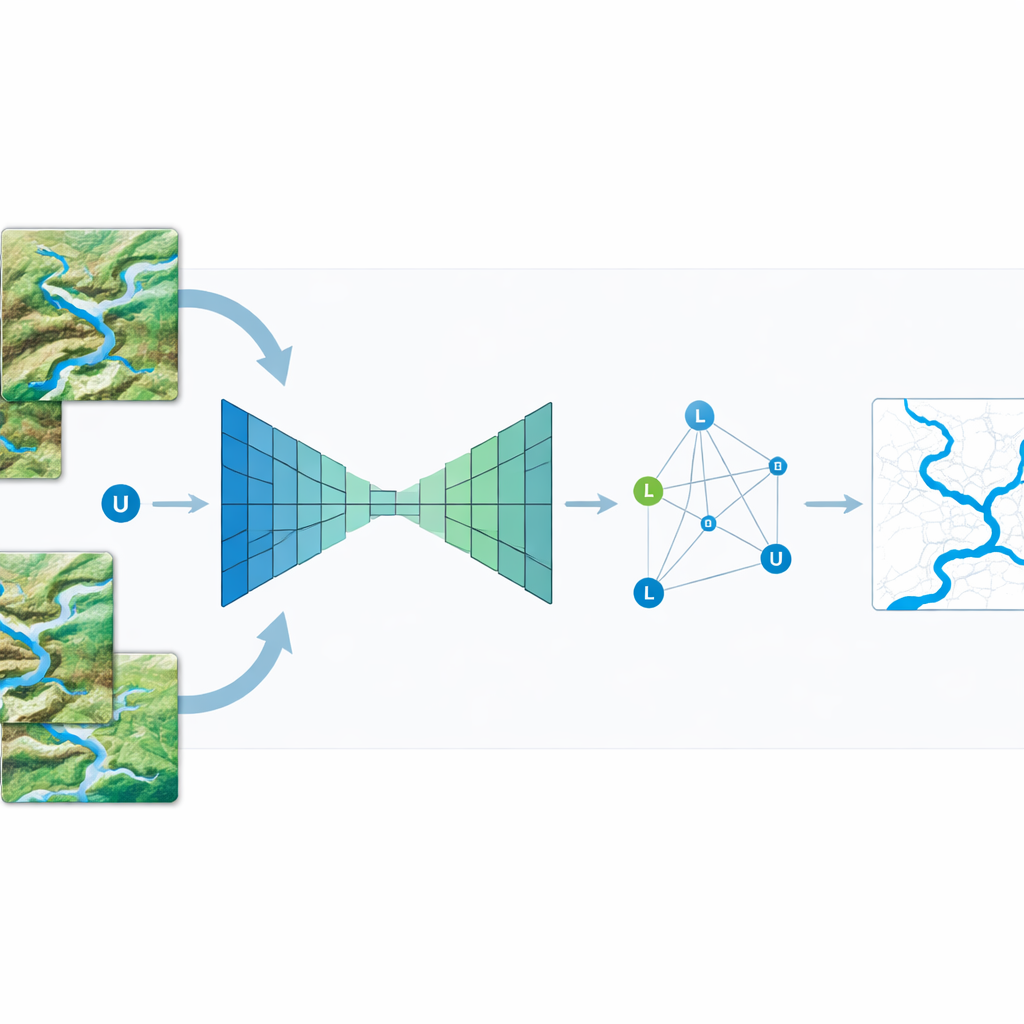
Utmaningen att hitta floder i komplexa bilder
Moderna kartläggningssystem förlitar sig ofta på djuplärning, en teknik där datormodeller lär sig känna igen mönster, såsom vatten kontra land, utifrån många exempelbilder. Dessa system fungerar väl för vida strukturer men har svårt med detaljer. I satellitscener kan flodbanker vara bara några pixlar breda och trassla ihop sig med vägar, skuggor och byggnader som ser liknande ut i färg och ljusstyrka. Standardnäverk med "encoder–decoder" behandlar varje pixel lika när de lär sig, vilket innebär att de lägger ner kraft på stora uniforma områden som fält eller sjöar samtidigt som de inte ger tillräcklig uppmärksamhet åt smala gränser där misstag är mest betydelsefulla. Dessutom är det tidskrävande och kostsamt att skapa precisa träningskartor där en människa ritat upp varje flod, så märkt data är sällsynt.
Ett smartare sätt att fokusera på flodkanter
Författarna angriper dessa problem med en teknik som kallas icke‑uniform provtagning. Istället för att mata nätverket med alla pixlar med lika vikt väljer de medvetet fler punkter i "högfrekventa" regioner — platser där färg eller ljusstyrka ändras snabbt, såsom kanten mellan vatten och land — och färre punkter i släta områden. Grov information från de djupare lagren i nätverket, som ser helheten, kombineras med fina detaljer från de grundare lagren, som fångar skarpa kanter. Bilineär interpolering, ett enkelt sätt att medelvärdesbilda värden i två riktningar, används för att blanda dessa grova och fina signaler så att varje utvald punkt återspeglar både lokala detaljer och bredare kontext. Genom att upprepade gånger förfina bara dessa noggrant utvalda punkter kan modellen skärpa flodkonturer utan den höga kostnaden av att analysera varje pixel i full upplösning.
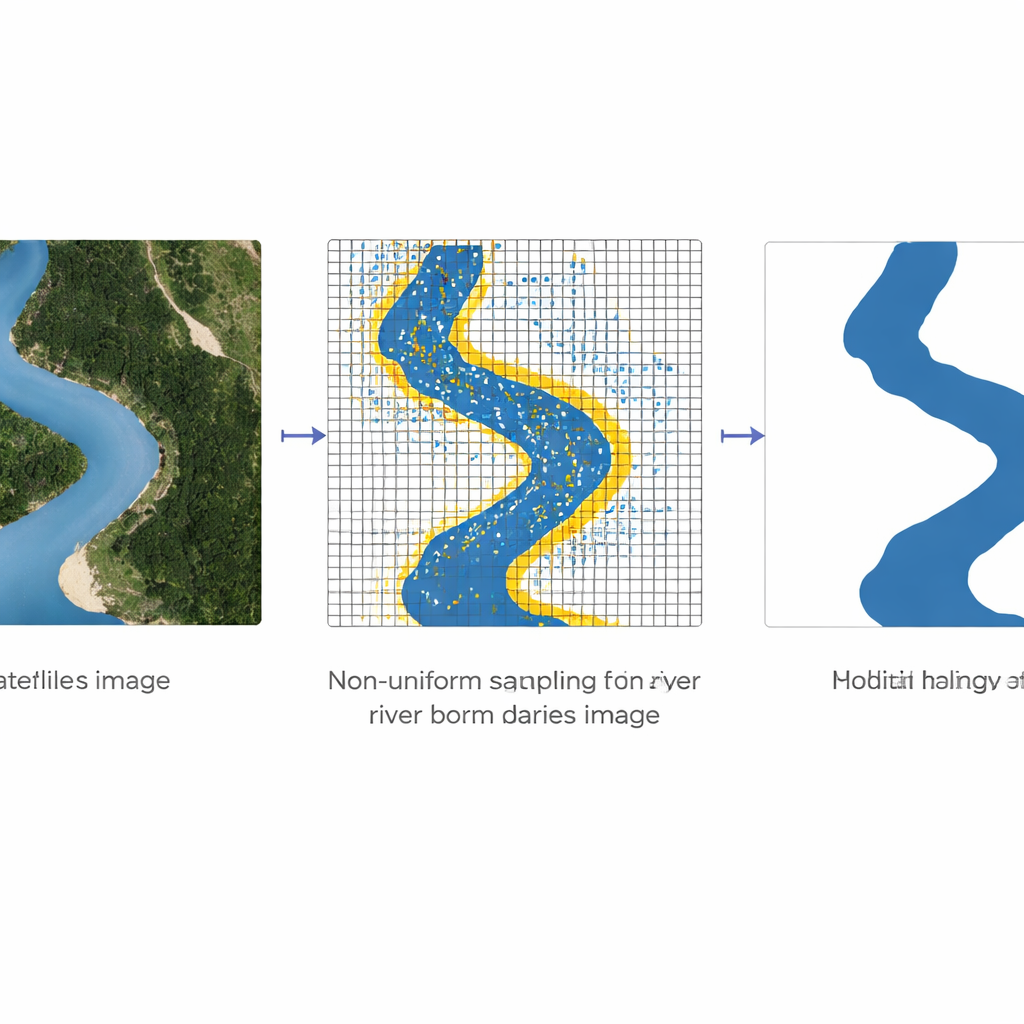
Att lära av omärkta bilder också
För att ytterligare förbättra prestandan lägger studien till semisupervised inlärning, vilket gör att systemet kan dra nytta av många omärkta satellitbilder. Metoden behandlar varje bildruta — märkt eller omärkt — som en nod i en graf och kopplar liknande rutor till varandra. Information från de få rutor med kända flodetiketter sprids sedan över grafen och förskjuter försiktigt förutsägelserna för omärkta rutor mot att bli mer konsekventa med sina närmaste grannar. I praktiken innebär detta att modellen kan "låna" struktur från de omärkta bilderna, lära sig var floder tenderar att förekomma och hur de relaterar till omgivande landskap, även när ingen människa ritat flodlinjer i just de scenerna.
Hur mycket bättre fungerar det?
Forskarna testade sitt tillvägagångssätt på en stor kinesisk satellitdatamängd (Gaofen‑2) och på den globala OpenEarthMap‑samlingen. När de införde icke‑uniform provtagning i tre vanligt använda flodkartläggningsnätverk — Unet, Linknet och DeeplabV3 — blev samtliga mer precisa och konvergerade snabbare under träningen. Mätt med standardmått som pixelnoggrannhet och intersection‑over‑union förbättrades floddetektering med ungefär en till tre procentenheter bara genom smartare provtagning. När de sedan lade till semisupervised inlärning och matade in alla tillgängliga omärkta bilder ökade noggrannheten med cirka fem procentenheter och överlappningsmåttet med mer än nio enheter. Metoden jämförde sig också väl med ledande semisupervised tekniker såsom Mean Teacher och Cross Pseudo Supervision, samtidigt som den använde mindre beräkning än en stark DeeplabV3‑baseline.
Vad detta betyder för verklig flodkartläggning
För icke‑specialister är slutsatsen enkel: författarna har byggt ett system som kan spåra floder i satellitbilder mer rent och effektivt genom att koncentrera sin uppmärksamhet på flodbanker och genom att lära sig inte bara från noggrant märkta exempel utan också från den stora massan omärkta bilder. Detta minskar det manuella arbete som krävs av experter och ger flodkartor med färre avbrott, skarpare kanter och färre förväxlingar med vägar eller skuggor. Även om metoden utvecklats för floder kan samma idé — smart provtagning plus semisupervised inlärning — hjälpa till att automatiskt kartlägga andra smala objekt som vägar och kanaler, vilket gör storskalig miljöövervakning mer exakt och mer kostnadseffektiv.
Citering: Wang, K., Han, L. & Li, L. River extraction from high-resolution remote sensing images based on non-uniform sampling and semi-supervised learning. Sci Rep 16, 6816 (2026). https://doi.org/10.1038/s41598-026-38167-6
Nyckelord: flodkartläggning, fjärranalys, djuplärning, semisupervised inlärning, satellitbilder