Clear Sky Science · sv
Effektiv beräkning och konstruktion av högpresterande dubbelprecision Vedic-multiplikatorarkitektur
Varför snabbare beräkningar spelar roll
Varje gång du strömmar en video, använder navigering på telefonen eller låter ett AI-system analysera medicinska bilder, utför specialiserad hårdvara i tysthet miljarder små beräkningar per sekund. En stor andel av dessa operationer är multiplikationer av flyttal—standardformatet för att representera reella värden som 3,14159. Denna artikel utforskar ett smartare sätt att bygga en av dessa kärnkomponenter: en högfrekvent, energieffektiv multiplikator som använder idéer från den forntida vediska matematiken för att stärka modern digital hårdvara.
Från forntida mattetrick till moderna kretsar
Flyttalsaritmetik ligger till grund för digital signalbehandling, bildbehandling, kommunikation och acceleratörer för djupinlärning. Standardmultiplikatorer måste hantera breda binära ord—64 bitar för dubbel precision—och göra det snabbt utan att slösa kretsarea eller energi. Traditionella tillvägagångssätt, såsom Booth, Karatsuba och array-multiplikatorer, balanserar avvägningar mellan hastighet, hårdvarustorlek och designkomplexitet. Vedic-matematiken, ett system av 16 klassiska aritmetiska regler utvecklade i Indien, innehåller en multiplikationsmetod kallad Urdhva Tiryakbhyam, eller "vertikalt och korsvis." Den bildar partiella produkter på ett mycket parallellt sätt, vilket kan minska antalet mellanliggande steg och den hårdvara som krävs. Forskare har nyligen anpassat dessa idéer till digitala kretsar, men befintliga konstruktioner bär fortfarande med sig overhead när de används för dubbelprecisions flyttalsoperationer.
Vad som är speciellt med denna nya multiplikator
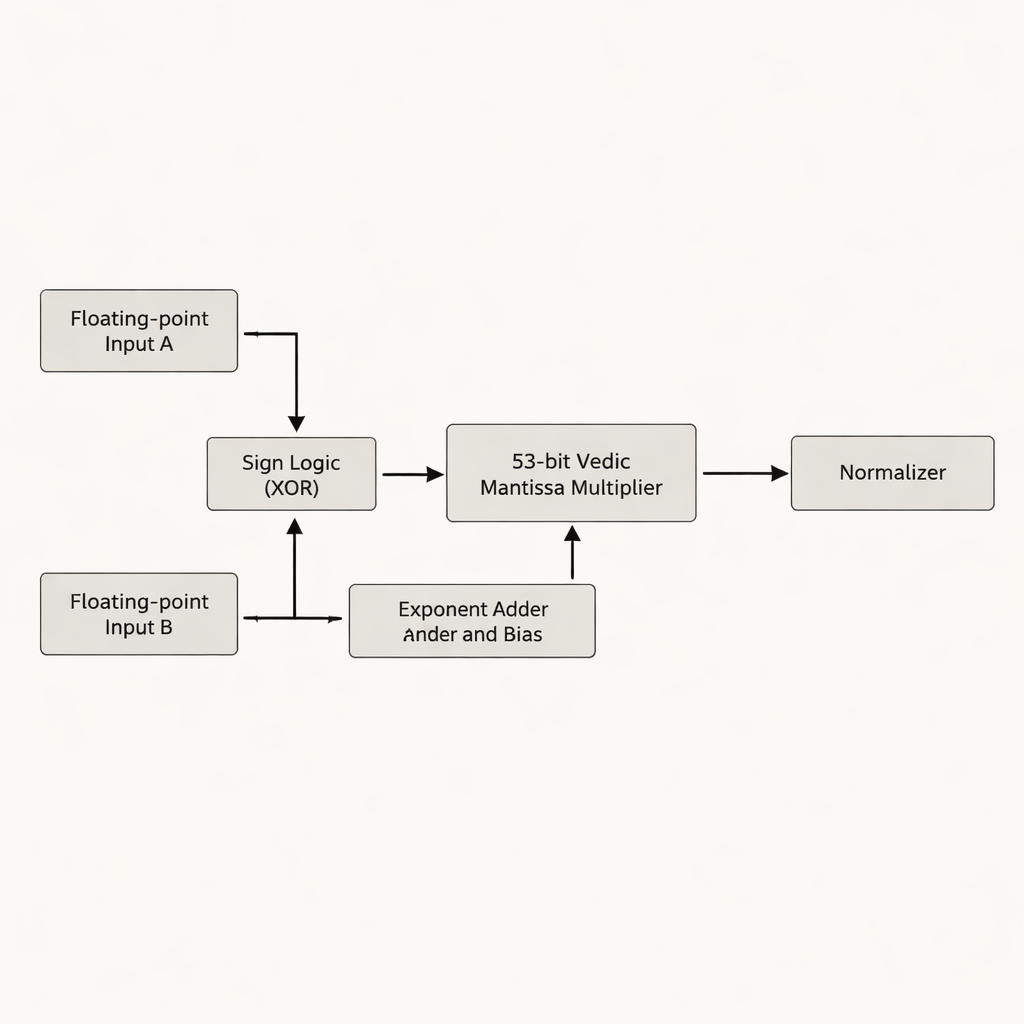
Författarna föreslår en dubbelprecision flyttalsmultiplikator som fokuserar på mantissan—den del av ett flyttal som innehåller de flesta signifikanta siffrorna. Istället för att fylla ut den 52-bitars mantissan till 54 bitar, som många tidigare konstruktioner gör, arbetar de med den verkliga 53-bitars effektiva mantissan och undviker bortkastade "vita" bitar som kräver extra lagring och ledningar på en kiselbit. Kärnan i designen är en 53-bitars Vedic-multiplikator baserad på Urdhva Tiryakbhyam, ordnad i en hierarki av mindre byggstenar: 3-bitarsenheter bildar 6-bitarsenheter, som bygger 12-bitars, 13-bitars, 26-bitars och 52-bitars enheter, och slutligen kombineras i den sista 53-bitarsfasen. Arkitekturen delar upp arbetet i tre huvudfaser—signumbestämning, exponentaddition och biasing, samt mantissamultiplikation följt av normalisering—i enlighet med IEEE-754-standarden, samtidigt som överflödig krets minskas.
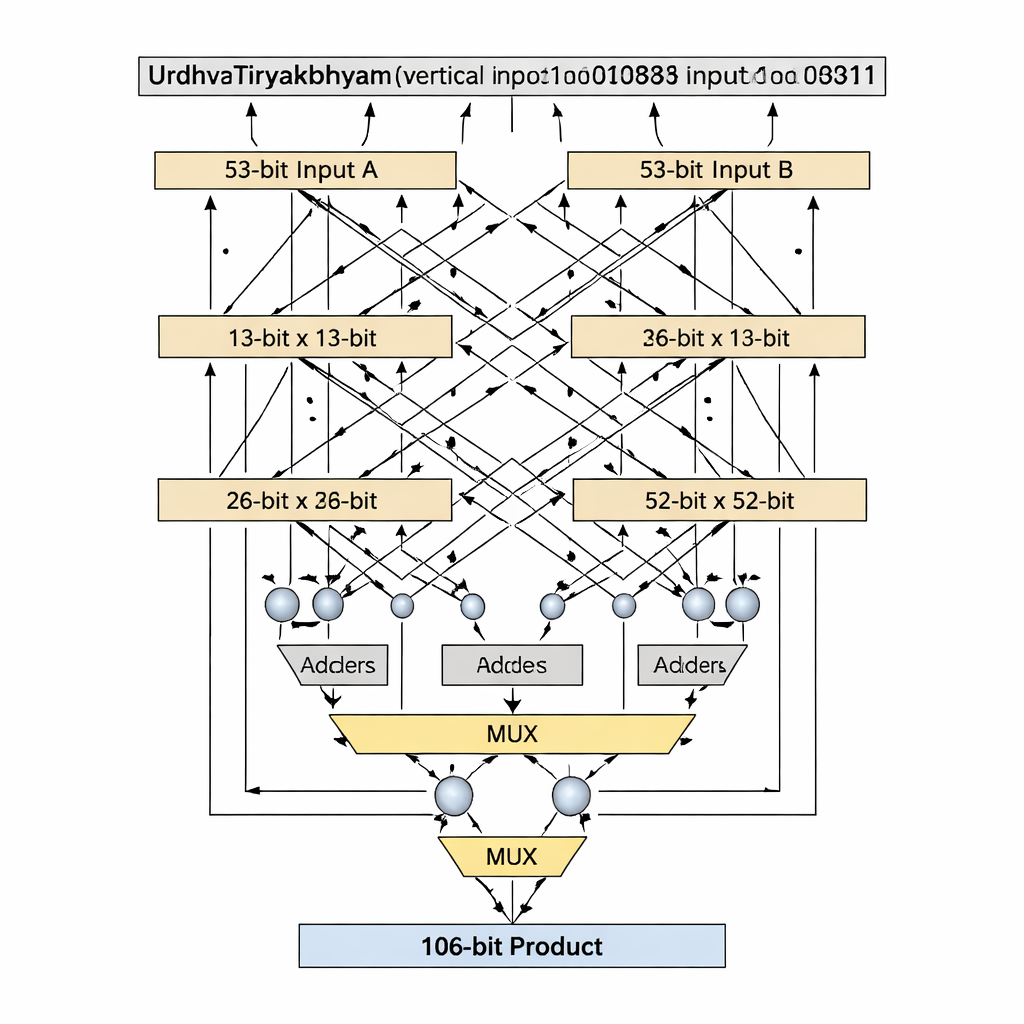
Primtalsstorlekar som byggstenar för renare hårdvara
En viktig innovation är hur designen hanterar bitbredder som är primtal, såsom 13 och 53, vilka inte går jämnt upp i lika stora block. Standard Vedic-dekompositioner antar jämnt delade ingångar, men det blir klumpigt eller slösaktigt för primtalslängder. Författarna introducerar en "prim-bit"-algoritm som smart återanvänder en mindre (n−1)-bitars Vedic-multiplikator tillsammans med adders, multiplexrar och en enda extra logikgrind för att efterlikna en n-bitars multiplikator utan utfyllnad. För 13-bitarssteget delas ingångarna i 1-bitars och 12-bitars sektioner; partiella produkter skapas med en 12-bitars Vedic-multiplikator, konditionell selektion (via multiplexrar) baserat på de mest signifikanta bitarna och ett litet antal adders. Samma mönster skalar upp till 53 bitar med en 52-bitarskärna. Denna skräddarsydda dekomposition förkortar kritiska vägen—den längsta logikkedjan en signal måste passera—samtidigt som antalet logikelement hålls lågt.
Mätta vinster i hastighet, storlek och effekt
Designen beskrevs i Verilog hårdvarubeskrivningsspråk och implementerades på en Xilinx Zynq fältprogrammerbar grind-array (FPGA) med Vivado-verktyg. För 13-, 26-, 52-, 53- och 64-bitars Vedic-multiplikatorer visar den föreslagna 53-bitarsenheten en fördelaktig balans mellan fördröjning, logikanvändning (lookup-tabeller och I/O-stift) och uppskattad effekt. Jämfört med tidigare dubbelprecisionsmultiplikatorer baserade på Booth, Karatsuba och andra Vedic-arrangemang minskar den nya arkitekturen betydligt värsta-fall-fördröjningen och mängden FPGA-resurser som krävs, utan att lägga till komplexitet i omkringliggande flyttalskretsar. Eftersom mantissamultiplikationen är snabbare och logikdjupet grundare minskar switching-aktiviteten, vilket pekar mot en bättre effekt–fördröjningsprodukt även om direkta effektjämförelser över teknologier är svåra att göra.
Påverkan på AI och signalbehandling
För att testa designen i en verklig arbetsbelastning integrerade författarna sin Vedic dubbelprecisionsmultiplikator i konvolutionsmotorn i ett konvolutionsneuronätverk, där multiplicera-och-ackumulera-operationer dominerar körtiden. Att ersätta konventionella IEEE-754- och tidigare Vedic-multiplikatorer med den nya designen minskade konvolutionsfördröjningen, reducerade effektförbrukningen och sänkte inferenstiden, samtidigt som samma klassificeringsnoggrannhet bibehölls. Liknande fördelar förväntas i andra beräkningsintensiva uppgifter, såsom digital filtrering, kantdetektion och medicinska bildbehandlingspipelines, där snabbare multiplikatorer direkt ökar genomströmningen och kan tillåta enheter att gå svalare eller köras på mindre batterier.
Vad det betyder för vardagsteknik
Enkelt uttryckt visar artikeln att ett smart multiplikationskoncept från vedisk matematik som omsorgsfullt anpassas till moderna binära format kan ge en multiplikator som är mindre, snabbare och mer energieffektiv än standardlösningar. Denna förbättrade byggsten kan integreras i processorer, signalbehandlingschip och AI-acceleratorer, vilket leder till snabbare dataanalys, mer responsiva enheter och potentiellt lägre energiförbrukning i system från smartphones till medicinska skannrar. Författarna skisserar också framtida riktningar, inklusive reversibel logik för ännu lägre energianvändning och integration i större processorenheter, vilket antyder att detta äktenskap mellan forntida aritmetik och modern hårdvara bara har börjat.
Citering: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Nyckelord: Vedic-multiplikator, flyttalsaritmetik, FPGA-design, digital signalbehandling, konvolutionsneuronätverk