Clear Sky Science · sv
Tillämpning av svärmbaserade djupa neurala nätverk och ensemblemodeller för rekonstruktion av data för specifik konduktans
Varför det är viktigt att fylla igen datagap
Kustvatten är frontlinjen där mänsklig verksamhet möter havet. Forskare följer hur salt dessa vatten är med ett mått som kallas specifik konduktans, vilket hjälper till att avslöja utsläpp av föroreningar, förändringar i sötvattenflöden och långsiktiga miljöförskjutningar. Men sensorer går sönder, stormar slår ut strömmen och instrument har begränsningar. Resultatet blir frustrerande luckor i viktiga tidsserier—precis när förvaltare och forskare mest behöver kontinuerlig data. Denna studie ställer en praktisk fråga: kan modern artificiell intelligens pålitligt “laga” dessa brutna register så att kustnära beslut bygger på kompletta, trovärdiga uppgifter?
Att se Golfen andas
Forskarna fokuserade på Mexikanska golfen, ett av världens största marina ekosystem och en region utsatt för starkt industriellt och jordbruksrelaterat tryck. De använde mätningar från fem U.S. Geological Survey-stationer nära Pascagoula River och Mullet Lake, där varje station registrerade vattnets salthalt (genom specifik konduktans), temperatur och vattennivå var 15:e minut. En station, kallad E, hade omkring 5 % av sina specifik‑konduktansdata saknade—exakt den typ av problem som verkliga övervakningsnätverk möter. Data från de fyra närliggande stationerna fungerade som ett slags miljösäkerhetsnät: även när station E blev blind fortsatte de andra att observera. Den centrala idén var att lära datorer hur alla fem stationer “andas” tillsammans så att luckor på en plats kan härledas från fullständiga register på de andra.
Att sätta smarta algoritmer på prov
För att tackla detta satte teamet samman en uppställning av tio olika modellmetoder. I ena änden fanns välkända verktyg som multipel linjär regression, som försöker dra raklinjiga samband mellan indata och utdata. I mitten fanns mer flexibla modeller som klassiska neurala nätverk, fuzzy‑logiksystem och ett specialiserat långt korttidsminne‑nätverk (LSTM) som ofta används för tidsseriedata. De använde också en självorganiserande metod kallad group method of data handling (GMDH) och en icke‑linjär variant (NGMDH) som kan bygga flerskiktade formler automatiskt. Slutligen tog de in träd‑baserade metoder: en ensam beslutsträdmodell (CART) och två ”ensemble”‑metoder—Random Forest och XGBoost—som kombinerar många träd för att fatta ett slutgiltigt beslut, ungefär som en panel av experter som röstar om ett svar.
Svärmdriven djupinlärning
Att träna djupa neurala nätverk är beryktat knepigt: deras många rattar och reglage kan lätt fastna i dåliga konfigurationer. För att förbättra dem kopplade författarna LSTM och NGMDH med en nyare optimeringsmetod inspirerad av virvlande vatten, kallad turbulent flow of water‑based optimization (TFWO). I detta upplägg föreställs varje möjlig uppsättning modellparametrar som en ”partikel” som rör sig i ett virvelmönster genom lösningsrymden. Över många cykler puttas partiklarna mot regioner som ger mindre prediktionsfel. Denna svärm‑stil sökning gjorde båda neurala nätverkstyperna märkbart mer precisa än deras standardversioner och minskade deras genomsnittliga fel med ungefär 6–11 procent. Ändå blev även dessa förbättrade djupa modeller i slutändan slagna av de träd‑baserade metoderna.
Ensemblerna tar ledningen
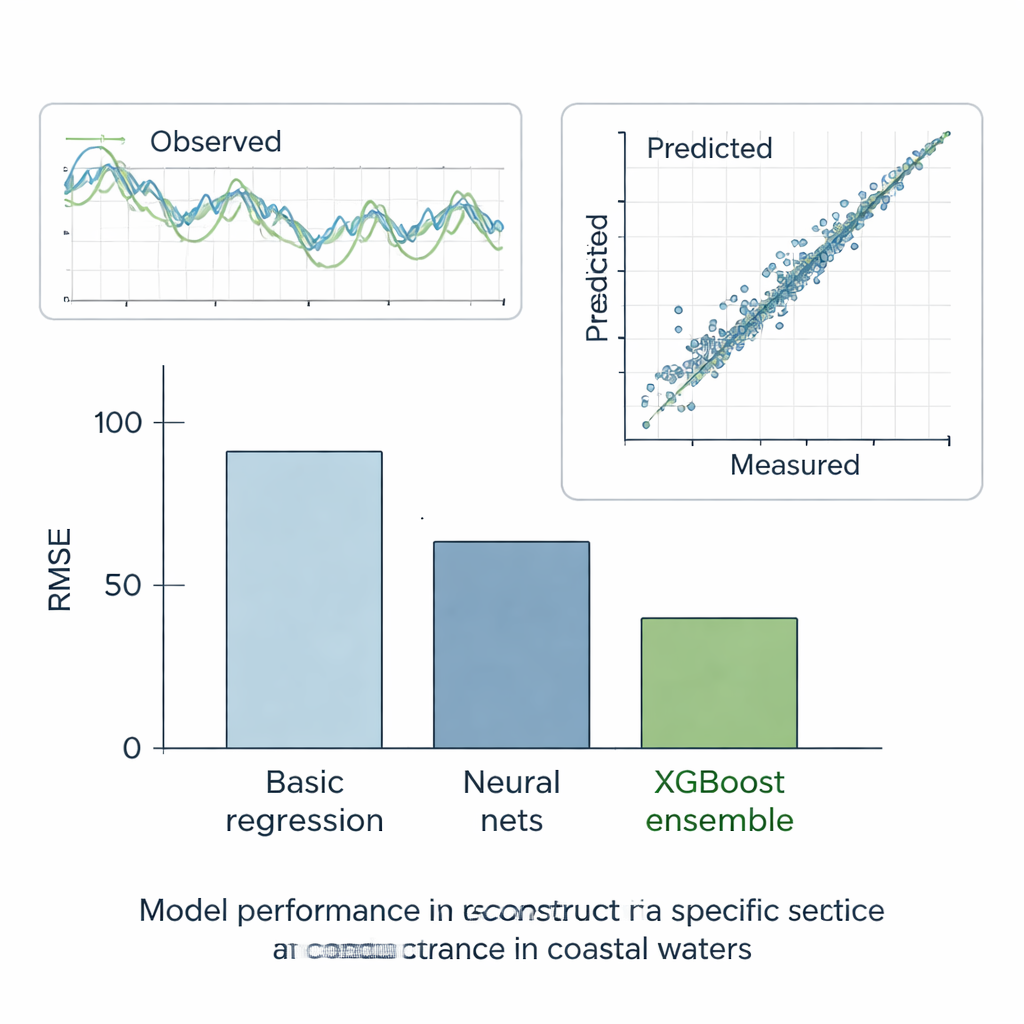
Författarna testade alla metoder noggrant i sex scenarier. I fem ”tänk‑om”‑fall gömde de delar av i övrigt kompletta register och kontrollerade hur väl varje modell kunde rekonstruera de saknade värdena. I det sista, verkliga fallet bad de modellerna fylla de faktiska luckorna vid station E med hjälp av grannstationernas data. I dessa tester presterade den enklaste raklinjiga metoden sämst, medan standardiserade maskininlärningsmodeller gjorde mycket bättre ifrån sig och minskade felet med ungefär hälften. Beslutsträd, som automatiskt delar upp data i mer homogena grupper, förbättrade resultaten ytterligare. Men den tydliga vinnaren var XGBoost‑ensemblen: genom att bygga hundratals träd där varje träd korrigerar föregångarnas misstag uppnådde den extremt lågt fel och en nästan perfekt överensstämmelse mellan predicerad och mätt specifik konduktans. Dess rekonstruktioner följde observerade tidsserier noggrant och återgav den övergripande statistiska beteendet i vattenkvalitetsregistren.
Vad detta betyder för kuster och bortom
För icke‑specialister är huvudbudskapet tydligt: noggrant utformad AI kan på ett pålitligt sätt fylla i saknade delar av kustnära vattenkvalitetsregister, särskilt när närliggande stationer finns tillgängliga för kontext. Även om avancerade neurala nätverk är kraftfulla visar denna studie att träd‑baserade ensemblemetoder som XGBoost kan vara ännu mer precisa och i praktiken vara det bästa valet för att reparera miljödatamängder. Med robusta verktyg för att fylla igen luckor kan forskare bättre följa subtila förändringar i kustens salthalt, identifiera föroreningshändelser och stödja förvaltningsbeslut utan att störas av oundvikliga sensoravbrott. Samma strategier kan anpassas till många andra tekniska och miljömässiga problem där dataströmmarna är rika, brusiga och ibland ofullständiga.
Citering: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Nyckelord: kustvattenkvalitet, specifik konduktans, maskininlärning, rekonstruktion av saknade data, XGBoost