Clear Sky Science · sv
Integrering av förenklad Swin-T med modifierad EFS-Net för uppmärksamhetsstyrd segmentering av undervattensrör i komplexa undervattensmiljöer
Varför det är viktigt att bevaka havsbotten
Dold under vågorna transporterar omfattande nätverk av rör olja, gas och kraftkablar som det moderna samhället är beroende av. Om dessa undervattensledningar spricker, korroderar eller förskjuts kan det leda till kostsamma avstängningar och allvarlig förorening. Idag utförs mycket av inspektionsarbetet av människor som granskar timmar av grumlig video från undervattensrobotar. Denna artikel presenterar ett nytt artificiellt intelligens (AI)-system som automatiskt kan identifiera rör i svåra undervattensbilder, även när de är svaga, täckta av ”sjösnö” eller delvis begravda i sand. Det är ett steg mot pålitlig, automatiserad inspektion som kan göra offshore-energi och infrastruktur säkrare och billigare att underhålla.

Se klart i en grumlig värld
Undervattensbilder är ökända för att vara svåra för datorer att tolka. Ljuset avtar snabbt med djupet, färgerna skiftar mot grönt och blått, och flytande partiklar skapar dis och snöliknande prickar. Klassiska bildtekniker som förlitar sig på skarpa kanter och tydlig kontrast brukar misslyckas när röret är täckt av sand, skymt av växtlighet eller suddigt av dimma. Djupinlärning har förbättrat situationen, och flera populära neurala nätverk kan redan upptäcka rör i specifika datamängder. Men dessa system är ofta specialiserade för en viss vattentyp eller kamerauppsättning. När de möter en ny miljö — annan vattenkvalitet, belysning eller bakgrund — sjunker deras noggrannhet kraftigt. Den centrala utmaningen är att bygga en modell som är både noggrann och anpassningsbar, samtidigt som den är tillräckligt effektiv för att köras i verkliga inspektionssystem.
En två-hjärnor-ansats för undervattensbilder
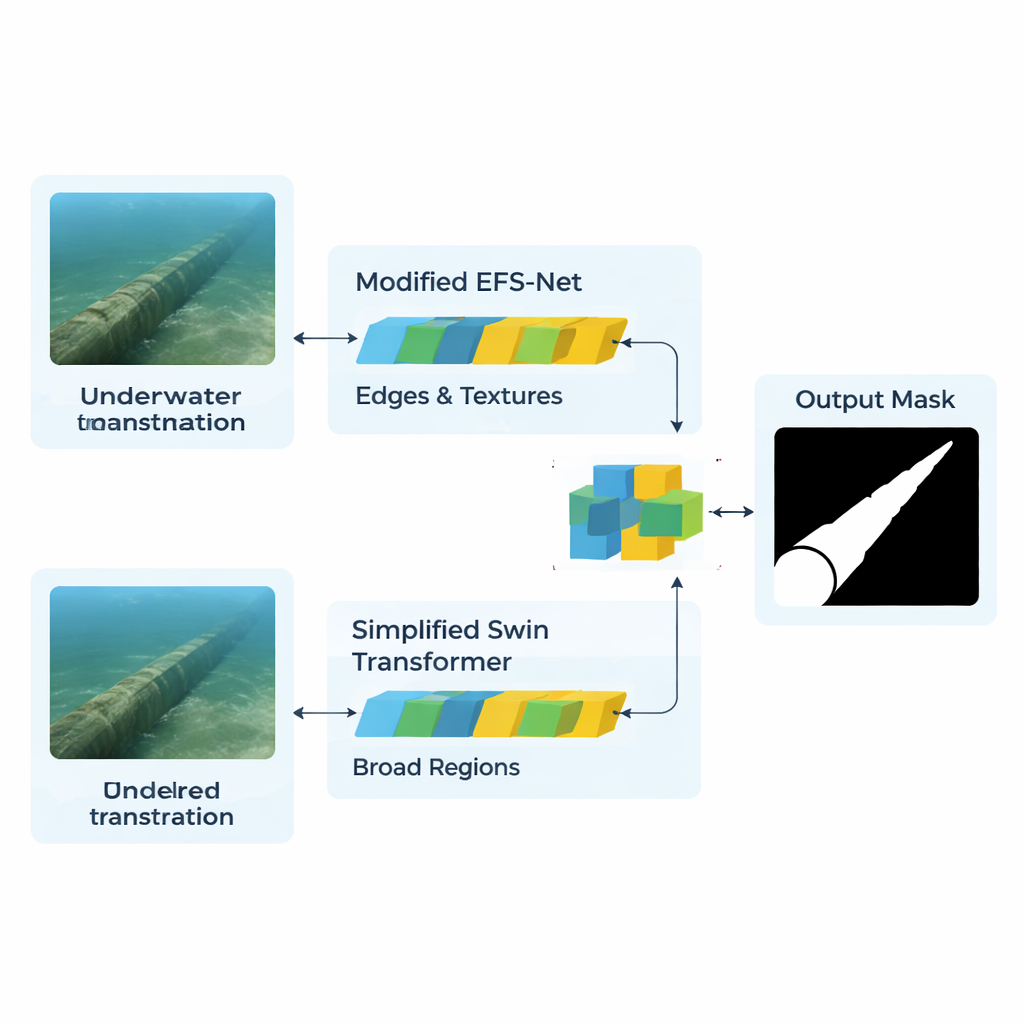
Författarna angriper detta genom att bygga en hybrid-AI-arkitektur som kombinerar två mycket olika ”sätt att se”. En gren, baserad på en strömlinjeformad version av Swin Transformer, fungerar som en vidvinkelobservatör. Den skannar hela bilden för att förstå storskaliga mönster, exempelvis rörens övergripande förlopp över havsbotten. Den andra grenen, anpassad från en modell kallad EFS-Net och driven av en EfficientNet-ryggrad, beter sig som ett förstoringsglas. Den koncentrerar sig på fina detaljer — kanter, texturer och tunna strukturer som visar var röret börjar och var sand eller växtlighet slutar. Båda grenarna bearbetar samma storleksanpassade bilder och omvandlar dem till interna featurekartor som beskriver vad nätverket tolkar som meningsfulla strukturer i varje region av bilden.
Låta uppmärksamheten avgöra vad som är viktigt
Att bara stapla utdata från de två grenarna skulle skapa ett trassel av redundant information. Istället använder modellen en uppmärksamhetsmekanism för att avgöra, pixel för pixel, vilka detaljer som är värda att fokusera på. En trehuvad cross-attention-modul jämför funktionerna från detaljfokuserade grenen med funktionerna från kontextfokuserade grenen. I praktiken ställer detaljgrenen riktade frågor — ”Är denna kant en del av ett rör?” — medan kontextgrenen levererar globala ledtrådar — ”Får en linje på denna plats och i denna riktning rimma som en del av ett rör?” Ett ytterligare förfiningssteg, kallat CBAM, förstärker signalen från sannolika rörregioner och dämpar bakgrundsbrus såsom stenar, alger eller upphängda partiklar. En dekodernätverk bygger sedan gradvis upp en mask i full storlek som markerar varje pixel som rör eller inte.
Test av systemet
För att bedöma om denna design fungerar i praktiken satte forskarna ihop en stor och krävande datamängd kallad HOMOMO. Den innehåller mer än 120 000 färgbilder av verkliga havsbottenrör tagna längs 1,2 kilometer rör under varierande och ofta fientliga förhållanden: svagt ljus, sjödimmor, flytande ”snö”, sanddrift och kraftig växtlighet. De tränade sin modell på en del av denna samling och jämförde den sedan med välanvända system som UNet, DeepLab, SwinUNet, TransUNet, Mask2Former och flera versioner av YOLO-objektdetektorn. På HOMOMO segmenterade deras hybridmodell korrekt rörpixlar med ett medelvärde för intersection-over-union på cirka 98 %, avsevärt högre än den bästa konkurrerande metoden. Lika viktigt är att när modellen testades — utan omträning — på två mycket olika bildkällor, en syntetisk Roboflow-datamängd och verklig YouTube-video, presterade den fortfarande starkt, vilket visar att den kan hantera nya kameror och vattenförhållanden.
Vad detta betyder för verkliga havet
För icke-specialister innebär slutsatsen att detta AI-system pålitligt kan avgränsa undervattensrör i videobilder som är för brusiga och ojämna för konventionella metoder. Genom att kombinera en global scenöverblick med ett skarpt öga för kanter och texturer, och genom att använda uppmärksamhet för att förena dessa perspektiv, uppnår modellen hög noggrannhet utan att kräva massiv datorkraft. I praktiska termer kan ett sådant verktyg hjälpa autonoma robotar att kontinuerligt övervaka långa sträckor av undervattensinfrastruktur och flagga möjlig skada eller begravning för mänsklig granskning. Även om den fortfarande har svårigheter med extremt tunna rör eller rör som är helt dolda, utgör angreppssättet ett viktigt steg mot säkrare, mer automatiserad inspektion av den dolda rörläggning som stöder moderna energi- och kommunikationsnätverk.
Citering: Hosseini, N., Mohanna, F. & Moghimi, M.K. Integrating simplified Swin-T with modified EFS-Net for attention-guided underwater pipelines segmentation in complex underwater environments. Sci Rep 16, 6987 (2026). https://doi.org/10.1038/s41598-026-38081-x
Nyckelord: undervattensledningar, bildsegmentering, djupinlärning, marin inspektion, transformernätverk