Clear Sky Science · sv
YOLC med dynamisk gles uppmärksamhet för högfartsdetektion av små mål i bärbara sportbilder
Att se sporten genom spelarens ögon
Föreställ dig att du ser en tennisserve eller en bordtennisduell inte från läktaren utan genom en kamera fäst vid en idrottares huvud. Bollen far över bildfältet som en liten suddig fläck, men tränare och analytiker vill veta exakt vart den tog vägen, hur snabb den var och hur spelarna reagerade. Denna artikel presenterar ett nytt datorvisionssystem kallat YOLC som är utformat för att upptäcka och följa dessa snabba, små objekt i realtid på små, lågströms bärbara enheter.
Varför små, snabba mål är så svåra att fånga
Bärbara kameror har blivit vanliga i idrottsträning och fångar förstapersonsvideo av matcher och övningar. Men ur detta perspektiv upptar avgörande objekt – en fjäderboll, en tennisboll, en sprintares startfot – ofta bara ett fåtal pixlar och rör sig snabbt från bildruta till bildruta. Befintliga detektionssystem är antingen för tunga för lågströmsenheter eller tappar bort objekt när de är små, suddiga eller långt borta. Författarna visar att i verkligt sportmaterial är många mål mindre än 32 × 32 pixlar och rör sig så snabbt mellan rutor att standardmetoder missar dem eller upprepade gånger förlorar deras identitet, vilket bryter banor och undergräver all seriös prestationsanalys.
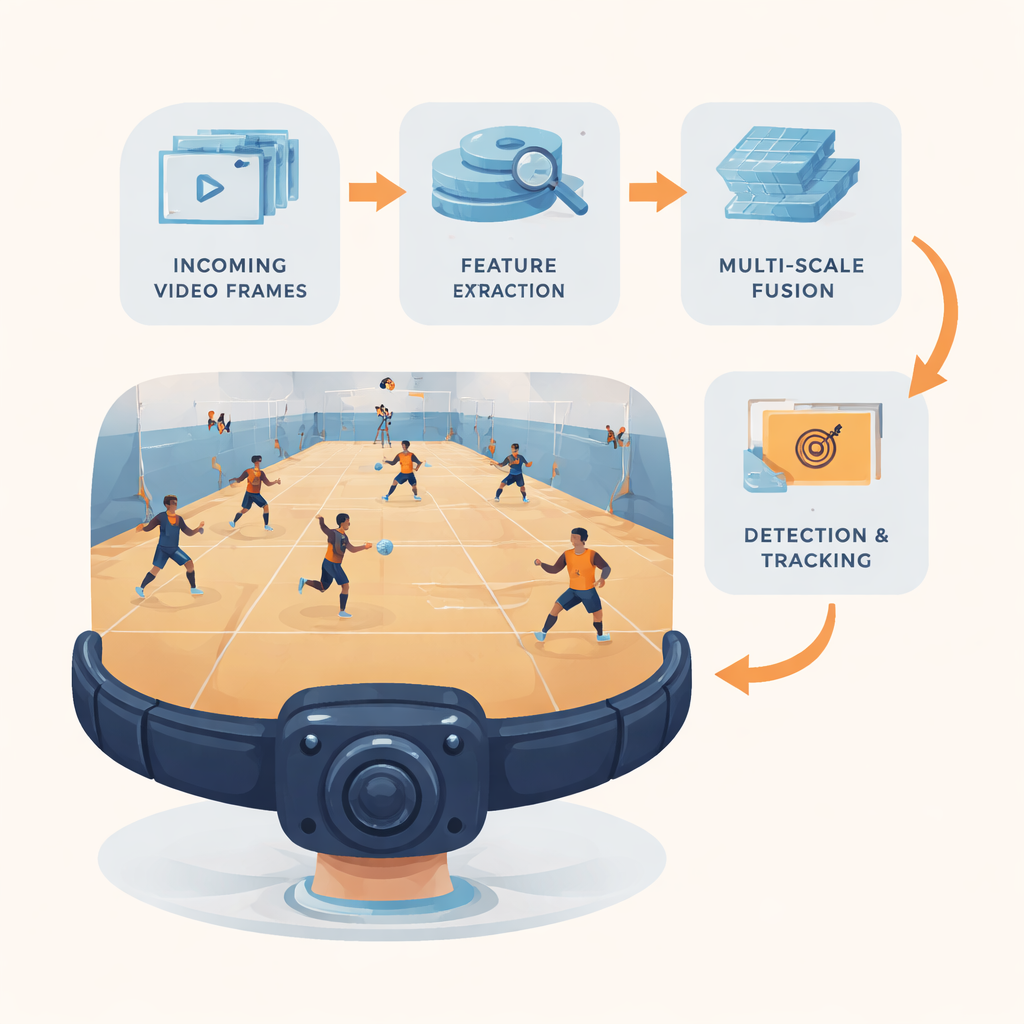
En lättviktsvisionspipeline för bärbara kameror
Forskarna introducerar YOLC (kort för ”You Only Look Clusters”), en komplett pipeline för detektion och spårning anpassad för edge‑hårdvara som en NVIDIA Jetson Nano. I botten ligger en strömlinjeformad feature‑extraktor byggd från en effektiv neuronnätsfamilj känd som MobileNet, omformad för att huvudsakligen använda ”billiga” operationer som minskar både minnes- och beräkningskostnader samtidigt som tillräcklig detalj bevaras för att se små objekt. Videorutor skalas till en balanserad upplösning och tre nivåer av feature‑kartor produceras: en som betonar fina detaljer för små mål, en för medelstora objekt och en med starkare högre nivåsemantik för stora eller avlägsna föremål. Dessa flerskaliga kartor matar resten av systemet, som är noggrant konstruerat för att pressa ut så mycket information som möjligt ur varje beräkning.
Låta nätverket bara titta där det spelar roll
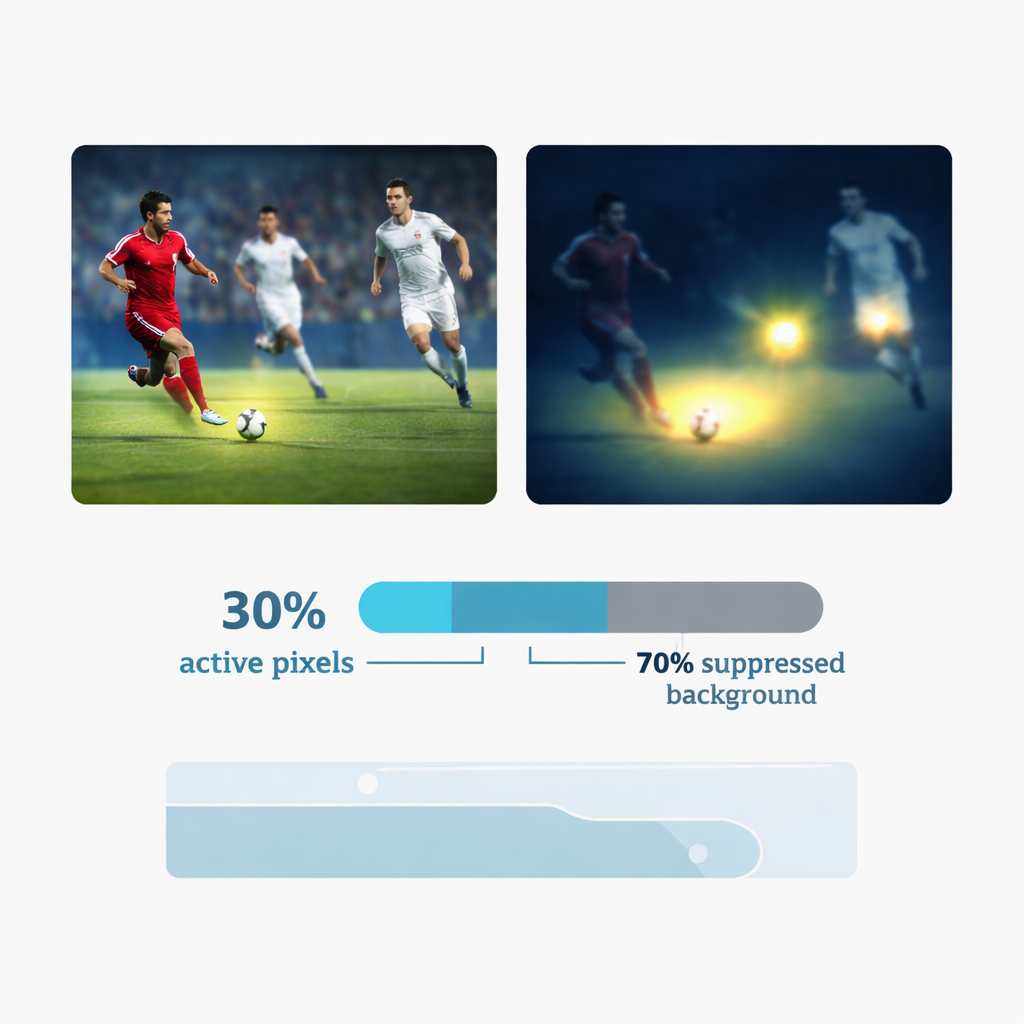
En central innovation är en mekanism för ”dynamisk gles uppmärksamhet” som efterliknar hur en människa kan kasta en blick endast på de mest informativa delarna av en scen. Istället för att bearbeta varje pixel lika mäter YOLC hur mycket bilden förändras lokalt – till exempel vid kanter, hörn eller konturen av en rörlig boll – och bygger en karta över var texturen är mest uttalad. Sedan behålls endast cirka de 30 procenten med högst respons för vidare bearbetning, vilket effektivt stänger av brusiga bakgrundsregioner som väggar, läktare eller himmel. En specialtrick vid träning gör att modellen förblir fullt träningsbar trots denna hårda avskärning. Denna selektiva fokus förbättrar inte bara noggrannheten genom att ignorera störningar, utan minskar också drastiskt mängden arbete nätverket måste utföra — en avgörande fördel på batteridrivna wearables.
Från skarpa drag till stabila spår
Efter att ha fokuserat på nyckelregioner kombinerar YOLC information över skalor med hjälp av en bidirektionell feature‑pyramid som skickar signaler både från grovt till fint och från fint till grovt. Styrkan i dessa kopplingar vägleds av samma uppmärksamhetskarta, så viktiga små objekt förstärks i varje steg. I det slutliga detektionssteget hjälper en extra enhet med ”koordinatuppmärksamhet” systemet att bättre förstå var objekten befinner sig i bilden genom att länka signaler längs horisontella och vertikala riktningar. För att omvandla ruta‑för‑ruta‑detektioner till mjuka spår över tid lägger metoden till en lättvikts optisk flödes‑modul — ett verktyg som uppskattar hur pixlar flyttar sig mellan på varandra följande rutor — samt ett tvåstegs matchningsschema som först parar högkonfidensdetektioner med befintliga spår och sedan försiktigt återanvänder lägre‑konfidens‑rutor som passar den förväntade rörelsen. Tillsammans minskar dessa komponenter identitetsbyten och luckor, även när objekt korsar varandras banor eller tillfälligt döljs.
Prestanda i verkliga förhållanden
Teamet testade YOLC på en specialbyggd sportdataset som inkluderar badminton, basket, tennis, sprint och bordtennis, allt inspelat med en huvudmonterad kamera i verkliga träningsmiljöer. På detta utmanande material körs systemet i 53,5 bildrutor per sekund med endast 1,78 miljoner parametrar, betydligt mindre än många populära objektigenkännare. Det uppnår en detektionspoäng (mAP@0.5) på 75,3 procent och ett återkallande för små objekt över 80 procent, och överträffar flera välkända lättviktiga modeller. I spårningsbenchmarkar bibehåller YOLC längre, mer pålitliga banor och minskar drastiskt identitetsbyten. Det visar sig också robust under rörelseoskärpa och kameraskakningar och halverar ungefär falsklarmfrekvensen jämfört med konkurrerande metoder.
Vad detta betyder för sport och bortom
För tränare, analytiker och utrustningstillverkare är budskapet tydligt: korrekt, realtidsförståelse av snabba sportaktioner behöver inte förlita sig på klumpiga servrar eller felfri tv‑kvalitet. Genom att noggrant avgöra var och när beräkningar ska göras förvandlar YOLC brusiga förstapersonsvideor från bärbara kameror till detaljerade register över hur små, snabba objekt rör sig och interagerar med idrottare. Det kan möjliggöra rikare återkoppling i träning, säkrare övervakning i högintensiva sporter och, mer generellt, smartare visionssystem på alla små enheter som måste se tydligt under hårda hårdvarubegränsningar.
Citering: Chen, H., Song, Y., Liu, W. et al. YOLC with dynamic sparse attention for high-speed small target detection in wearable sports images. Sci Rep 16, 6858 (2026). https://doi.org/10.1038/s41598-026-38079-5
Nyckelord: bärbar sportvision, detektion av små objekt, spårning i realtid, edge-AI, uppmärksamhetsmekanismer