Clear Sky Science · sv
Byggandet och förfinade extraktionstekniker för kunskapsgraf baserad på stora språkmodeller
Smartare kartor för komplexa beslut
Moderna beslut inom höginsatsområden—som storskalig drift, infrastrukturhantering eller katastrofinsatser—bygger på förmågan att snabbt skapa överblick av stora mängder splittrad information. Manualer, sensordata, rapporter och simuleringar ger alla delar av bilden, men de är sällan organiserade så att människor eller system enkelt kan använda dem. Denna artikel presenterar ett sätt att omvandla den fragmenterade informationen till levande “kunskapskartor” drivna av stora språkmodeller, så att planerare och analytiker kan ställa bättre frågor och få snabbare, mer tillförlitliga svar.
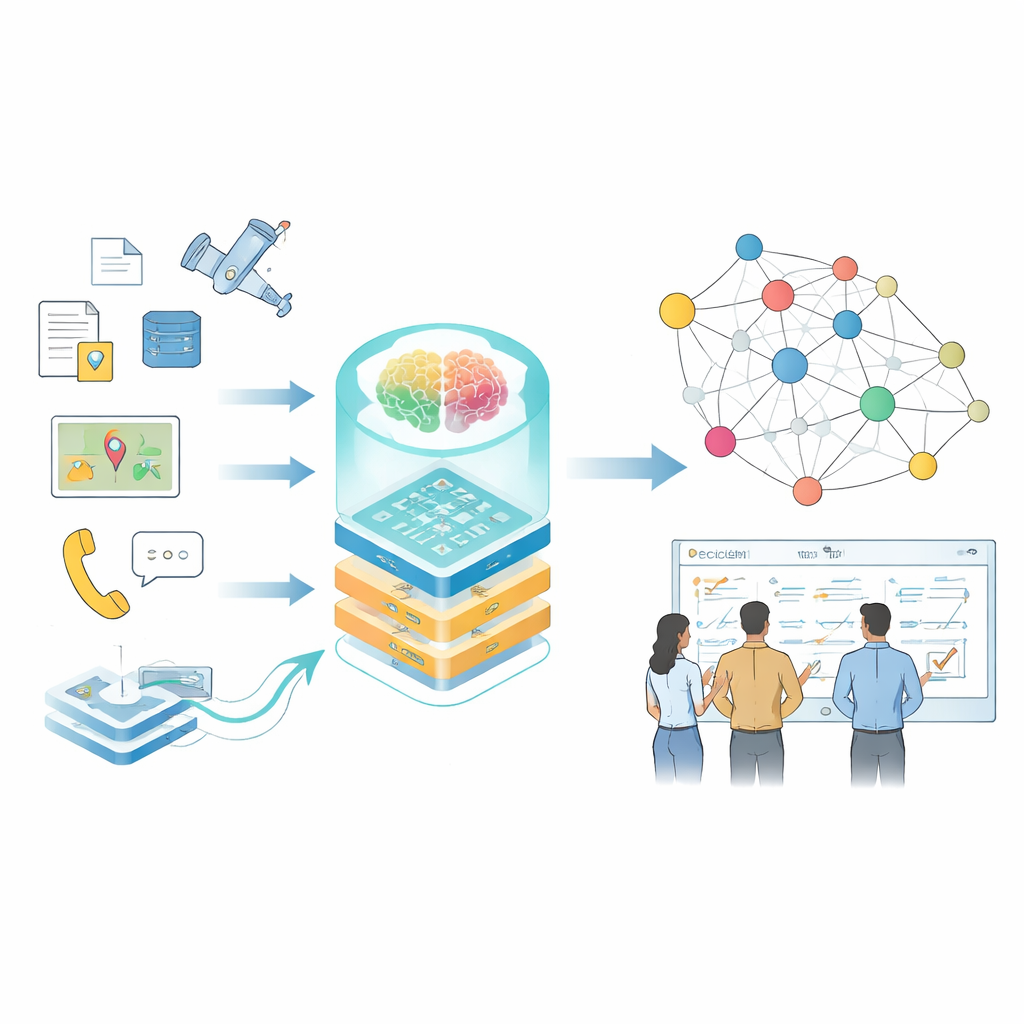
Från spridda fakta till sammanlänkad kunskap
Författarna koncentrerar sig på kunskapsgrafer, ett sätt att representera information som ett nätverk av sammankopplade fakta—vem gjorde vad, med vilket system, under vilka förhållanden. I vardagliga tillämpningar driver sådana grafer redan sökmotorer och rekommendationssystem, men specialiserade domäner ställer hårdare krav: data är känslig, terminologin är tät, format varierar från löpande text till sensorloggar, och förhållanden förändras snabbt. Traditionella verktyg som förlitar sig på handskrivna regler eller små modeller har svårt att stå pall, och allmänna språkmodeller misstolkar ofta tekniska termer eller förbiser subtila relationer som är avgörande för verkliga beslut.
Lära stora språkmodeller ett nytt specialistområde
För att möta detta finjusterar studien en kraftfull basmodell på en noggrant utformad domänspecifik dataset. Datasetsen bygger på kommando‑kommunikationer, utrustningsmanualer, simulerade scenarier och sakkunnig litteratur. Innan något av detta material når modellen avkänslas det kraftigt: konkreta koordinater blir relativa positioner, enhetsnamn omvandlas till generiska koder, och känslig logik maskas delvis samtidigt som övergripande mönster bevaras. Data lagras i ett strukturerat format som beskriver den bredare situationen, de specifika uppgifterna (såsom planering, hotrankning eller frågor och svar) och länkarna mellan dem. Denna struktur låter modellen lära sig inte bara isolerade fakta utan också hur olika uppgifter delar kontext.
Adaptationslager för olika uppgifter
I stället för att omträna varje parameter i språkmodellen—en kostsam och riskfylld process—använder författarna en teknik kallad low‑rank adaptation, organiserad i flera lager som var och en fokuserar på olika aspekter av problemet. Ett lager fångar grundläggande terminologi och begrepp, ett annat inbäddar operativa regler och begränsningar, och ett tredje specialiserar sig på att anpassa modellen till särskilda uppgifter, såsom planering eller hotbedömning. En separat styrkomponent, ”routing”-nätverket, granskar varje indata och bestämmer vilken kombination av dessa lätta adaptrar modellen bör använda. Denna design gör att systemet effektivt kan växla mellan uppgifter samtidigt som både allmän språkförmåga och domänspecifik expertis bevaras.
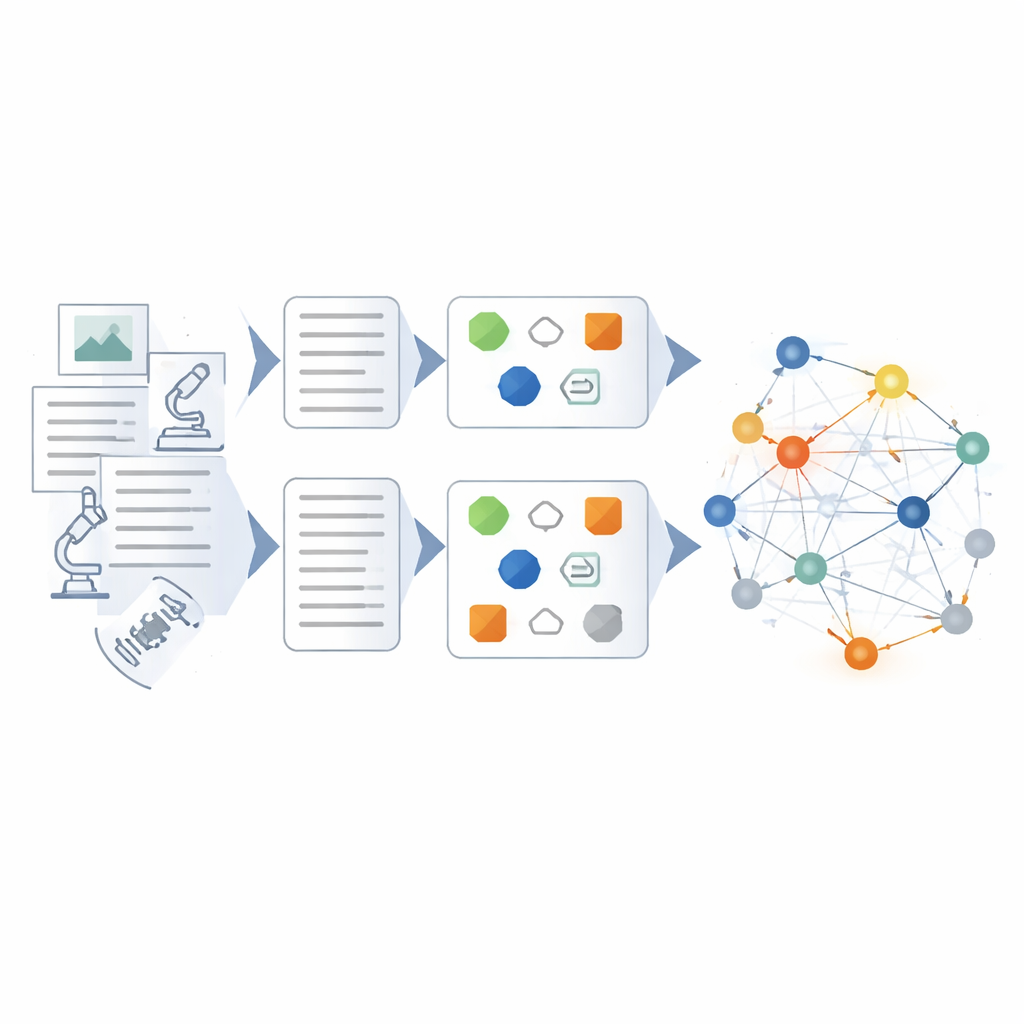
Bygga och kontrollera kunskapsnätet
Ovanpå den finjusterade modellen utformar författarna en hybridpipeline för att konstruera själva kunskapsgrafen. Först rengörs och standardiseras rådata så att termer och format blir konsekventa. Därefter extraherar regelbaserade metoder och expertutformade mallar uppenbara entiteter och händelser. Den finjusterade språkmodellen tar över för att hantera mer komplexa uppgifter: förkorta röriga rapporter till koncisa sammanfattningar, identifiera nyckelaktörer och utrustning samt härleda relationer som orsak‑och‑verkan‑kedjor eller samordning mellan enheter. Varje extraherat faktum poängsätts ur flera perspektiv—hur väl det passar kända mönster, hur starkt det kopplar till andra fakta och om det stämmer överens med flerstegs slutledningsvägar genom grafen. Endast högkonfidentsresultat läggs till, medan lågkonfidensposter flaggas för granskning.
Bevisade förbättringar i noggrannhet och tillförlitlighet
Teamet utvärderar sin metod på tre kärnuppgifter som speglar verkliga behov: besvara komplexa frågor om regler och utrustning, föreslå handlingsplaner för givna situationer och rangordna olika hotscenarier efter allvarlighetsgrad. Över dessa uppgifter presterar den anpassade modellen konsekvent bättre än väletablerade generella system, inklusive ledande modeller som tränats mer generiskt. Den svarar rätt på fler frågor, producerar mer realistiska planer och rangordnar hot mer precist. Den resulterande kunskapsgrafen är både stor och tätt sammankopplad, med över 90 procent av de lagrade fakta som klarar strikta konfidenskontroller och hjälper planerare att snabbare nå välgrundade beslut.
Varför detta spelar roll framöver
För en allmän läsare är huvudbudskapet att språkmodeller kan omvandlas från välformulerade talare till noggranna, specialiserade analytiker—om de tränas på rätt data, begränsas av tydliga regler och kontinuerligt kontrolleras för kvalitet. Detta arbete visar hur man gör det i en känslig, snabbt föränderlig domän samtidigt som privat information skyddas. Ramverket organiserar inte bara spridd kunskap till ett användbart nätverk, utan håller även det nätet uppdaterat och förtroendeingivande, och erbjuder en ritning för framtida beslutsstödsystem inom alla områden där rätt komplexa avgöranden verkligen är avgörande.
Citering: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Nyckelord: kunskapsgraf, stor språkmodell, beslutsstöd, domänanpassning, dataavkänslning