Clear Sky Science · sv
Generera gränsfall för slumpmässighetstestare med intelligent optimering och evolutionära algoritmer
Varför nästan-slumpmässigt spelar roll för vardaglig säkerhet
Varje gång du handlar på nätet, låser upp din telefon eller skickar ett privat meddelande rullas osynliga matematiska tärningar för att hålla dina data säkra. Dessa tärningar tar formen av långa strängar av förmodat slumpmässiga bitar som används som kryptografiska nycklar. Om de bitarna är ens en aning mindre slumpmässiga än de borde vara kan ihärdiga angripare ibland hitta mönster att utnyttja. Denna artikel utforskar ett nytt sätt att tillverka ”nästan-slumpmässiga” testsekvenser — data som ser extremt slumpmässiga ut men döljer små fel — så att ingenjörer kan utsätta de enheter som skyddar våra digitala liv för verkligt krävande tester.
När slumptal inte är tillräckligt slumpmässiga
Moderna säkerhetssystem förlitar sig på två typer av slumptalsgeneratorer. Sanna (fysiska) slumptalsgeneratorer drar nytta av oförutsägbara fysiska effekter, såsom elektroniskt brus eller kvantfluktuationer, medan pseudoslumpmässiga generatorer använder algoritmer som omvandlar korta, slumpmässiga frön till långa sekvenser. I praktiken beror kvaliteten hos båda slutligen på den fysiska källan till oförutsägbarhet, kallad entropikälla. Tyvärr är verkliga entropikällor sköra: temperaturförändringar, åldrande av hårdvara eller konstruktionsfel kan tyst minska deras slumpmässighet. För att upptäcka sådana problem definierar standardiseringsorgan som NIST batterier av statistiska tester som kontrollerar om utdata ser tillräckligt slumpmässiga ut. Enheter börjar i allt högre grad inbygga ”real-tid slumpmässighetstestare” som övervakar sin egen output medan de körs. Ändå har det saknats bra sätt att generera realistiska, svårupptäckta feltyper för att testa om dessa inbyggda kontroller verkligen fungerar.
Designa sekvenser som knappt misslyckas i slumpmässighetstester
Ur en testares synvinkel är triviala fel — som att utdata är alla nollor — lätta att upptäcka. Den verkliga utmaningen är att hitta gränsfall: sekvenser som nästan är omöjliga att skilja från ideal slumpmässighet men som precis misslyckas i ett eller flera statistiska test. Författarna fokuserar på fem klassiska tester som tittar på olika aspekter av bitmönster, inklusive hur ofta nollor och ettor förekommer, hur bitpar beter sig, hur vissa korta mönster distribueras, hur bitar korrelerar med förskjutna kopior av sig själva och hur längderna på löp av identiska bitar är ordnade. De definierar en ”gränszon” för varje test: ett smalt intervall där data endast marginellt överskrider de vanliga acceptanstersklerna. Att producera en lång sekvens som hamnar inom alla dessa smala zoner samtidigt är extremt osannolikt av en slump, eftersom testerna interagerar på komplicerade, icke‑linjära sätt. Här kommer optimering och AI in i bilden.
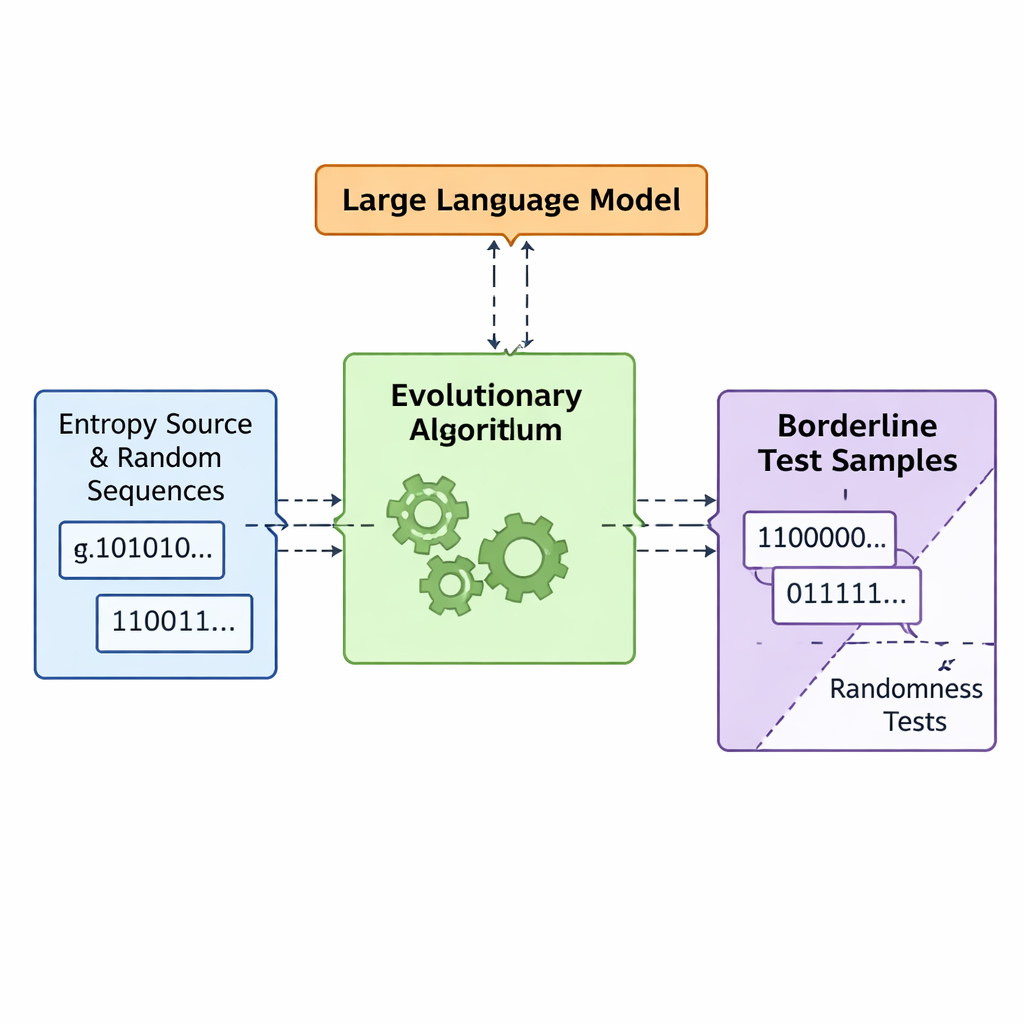
Låt evolution och språkmodeller samskapa dålig slumpmässighet
Teamet introducerar en ram kallad APAM‑IGLLM som behandlar sekvensgenerering som ett högdimensionellt optimeringsproblem. Varje kandidatsekvens är en bitsträng och dess ”fitness” mäter hur nära den kommer gränszonerna för de fem testerna. En genetisk algoritm muterar och kombinerar upprepade gånger dessa sekvenser och behåller dem som rör sig närmare målregionen. Ovanpå detta agerar en stor språkmodell (LLM) som en slags strategitränare. Vid varje generation undersöker den sammanfattande statistik för populationen och kortsiktig historik, och föreslår sedan hur interna rattar — vikter och skalningsfaktorer som avgör hur starkt varje test påverkar fitness — ska justeras. Detta skapar en återkopplingsslinga: den genetiska algoritmen utforskar rymden av möjliga sekvenser medan LLM:en styr sökningen så att alla fem testpoäng konvergerar mot den lilla korsningen där sekvenser precis är icke‑slumpmässiga.
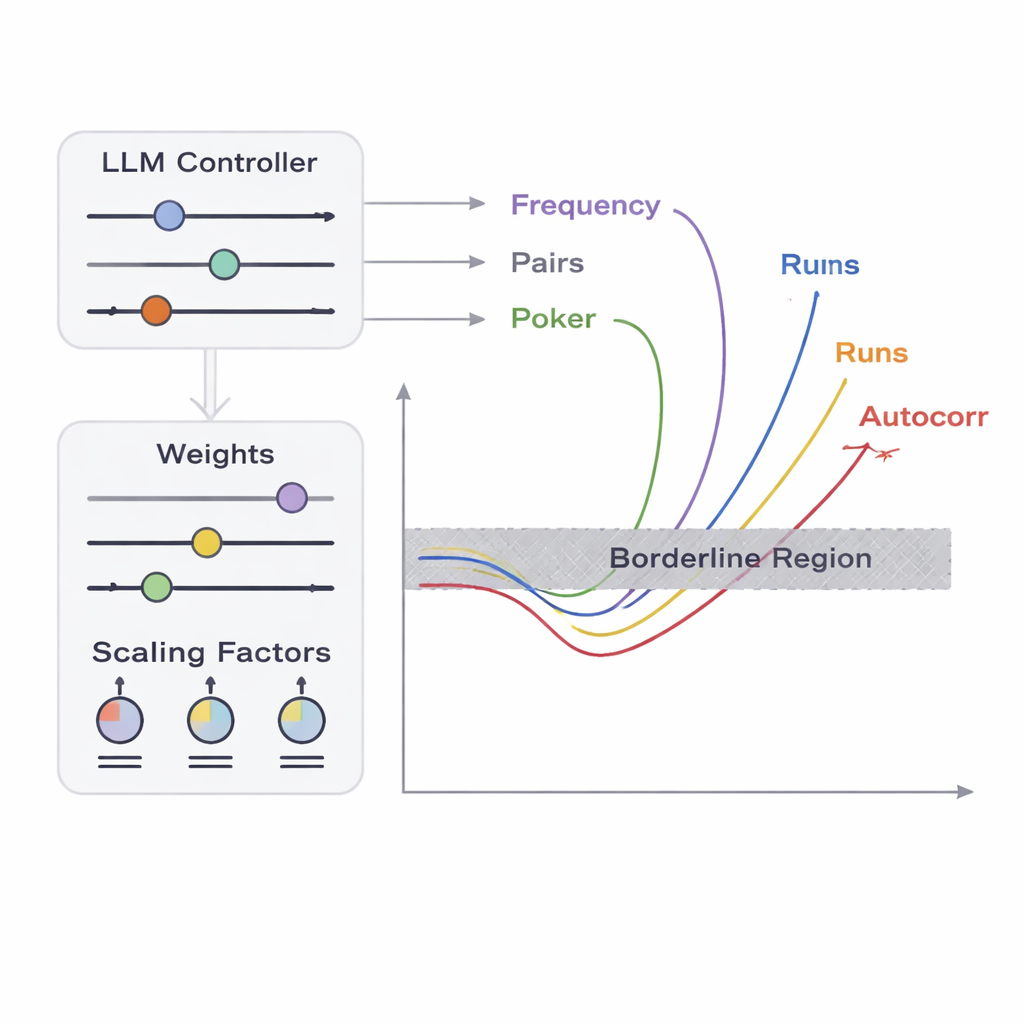
Hur nära perfekt slumpmässighet kan felaktig data se ut?
För att se om deras artificiella fel ser realistiska ut jämför författarna sina genererade sekvenser med mycket använda riktmärken. De beräknar både Shannon‑entropi och min‑entropi, mått på hur oförutsägbar varje byte framstår, och hittar värden runt 7,6–8 bitar per byte — mycket nära det teoretiska maximumet 8 och liknande kommersiella hårdvarukällor för slumpmässighet och NIST:s egen offentliga slumpmässighetsbeacon. De kör också hela NIST SP 800‑22 statistiska testrutinen och observerar att deras gränssekvenser passerar och misslyckas i nästan samma mönster som genuina högkvalitativa slumpmässiga data. Med andra ord, för standardverktyg ser dessa prov i stort sett normala ut, även om de medvetet konstruerats för att ligga nära flera felskärr. Det gör dem till idealiska ”adversariala” indata för att kontrollera hur robusta inbyggda slumpmässighetstestare verkligen är.
Vad detta betyder för verklig säkerhet
Ur en lekmans perspektiv erbjuder detta arbete ett nytt sätt att säkerhetskontrollera den slumptalsmaskinvara som ligger till grund för kryptering. Istället för att bara testa enheter med uppenbart trasig eller uppenbart frisk slumpmässighet kan ingenjörer nu bombardera dem med noggrant utformade, nästan‑goda sekvenser som efterliknar subtila hårdvarufel eller miljödrift. Om en realtids‑slumpmässighetstestare missar dessa gränsfall signalerar det en potentiell blindfläck som bör åtgärdas innan enheten tas i bruk inom bank, säker kommunikation eller blockkedjesystem. Genom att använda evolutionär sökning vägledd av en språkmodell tillhandahåller författarna ett praktiskt verktyg för att generera sådana krävande testdata, vilket hjälper till att föra de dolda grunderna för digital säkerhet mot högre tillförlitlighet.
Citering: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Nyckelord: slumptalsgeneratorer, entropikällor, evolutionära algoritmer, stora språkmodeller, kryptografisk testning