Clear Sky Science · sv
Korrigering av brusiga etiketter via jämförande destillation: en domänanpassningsmetod
Varför rörig data blir ett växande problem
Modern artificiell intelligens är beroende av data, men dessa data är ofta felaktiga, ofullständiga eller ojämnt märkta. När etiketter är brusiga—till exempel en bild på en katt som är taggad som en hund—kan inlärningssystem bli vilseledda och tappa i både noggrannhet och tillförlitlighet. Denna artikel tar sig an det verkliga problemet: hur man tränar bildigenkänningssystem som fortfarande fungerar väl även när träningsetiketterna är felaktiga och bilderna kommer från olika miljöer, såsom nätbutiker kontra bilder tagna i verkligheten.
Lära sig över olika världar
I praktiken lär sig AI‑modeller ofta från en ”källvärld” där etiketter är noggrant kontrollerade, men måste prestera i en ”målvärld” där etiketter är knappa och felbenägna. Till exempel är kontorsföremål fotograferade i en studio prydliga och korrekt märkta, medan webbkamera‑ eller vardagsbilder av samma föremål är röriga och ojämnt taggade. Traditionella metoder för domänanpassning försöker överbrygga denna klyfta genom att anpassa de övergripande statistiska egenskaperna mellan världarna. De förutsätter dock ofta att måletiketter, när de finns, är korrekta—en riskfylld antagelse som fallerar i praktiska tillämpningar med crowd‑sourcade taggar, sensorer av låg kvalitet eller automatisk annotering.
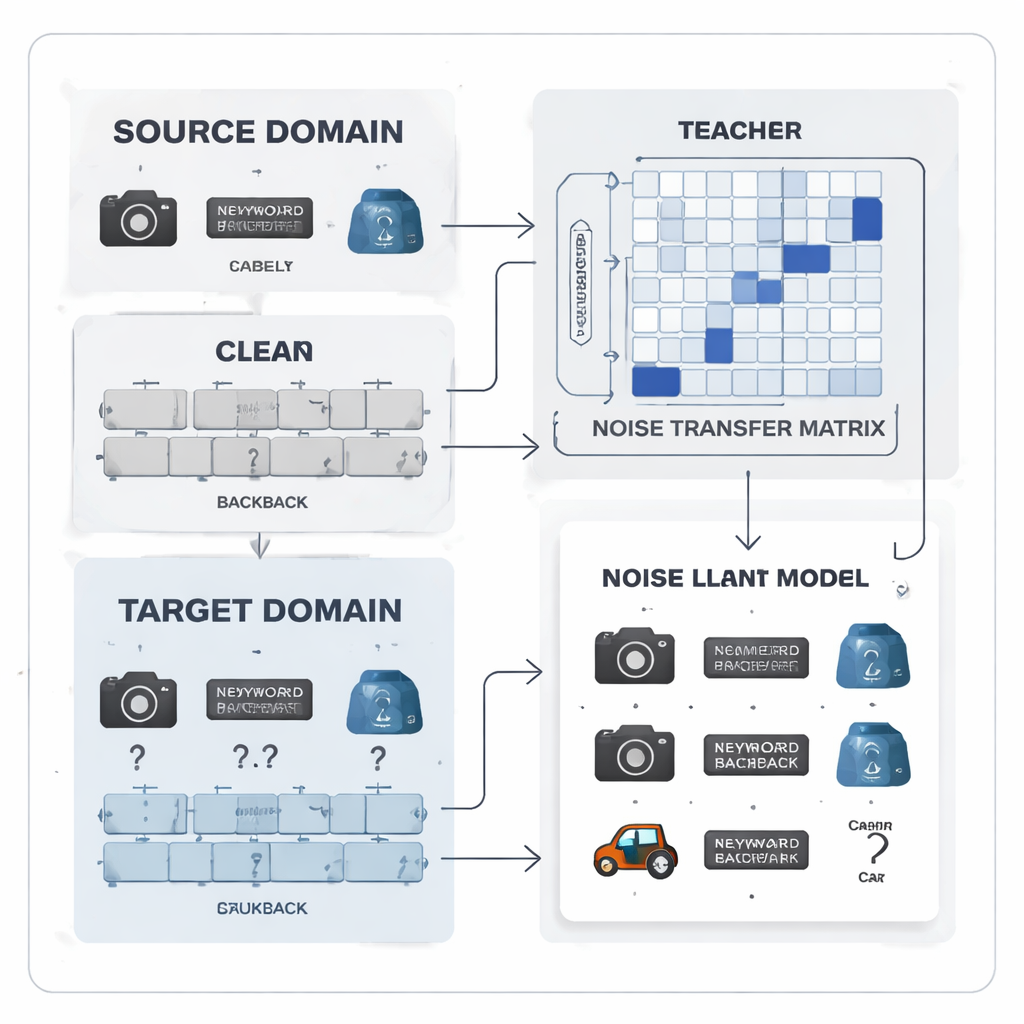
Göra etikettsmisstag till ett inlärningsbart mönster
Författarna föreslår att betrakta etikettsbrus inte som slumpartat kaos utan som ett inlärningsbart mönster. De introducerar en ”brusöverföringsmatris”, en tabell som fångar hur sannolikt det är att varje verklig klass felmärks som en annan. Istället för att uppskatta denna matris från ett fåtal perfekta ”ankarexempel”—vilket är orealistiskt när etiketter är brusiga och klasser obalanserade—lärs matrisen direkt under träningen. För att komma igång bygger metoden kategoriprototyper, genomsnittliga funktionsavtryck för varje klass extraherade av en stark förtränad modell. Likheten mellan dessa prototyper används för att initiera matrisen så att förväxlingsbara kategorier, som liknande kontorsverktyg, tidigt kopplas starkare samman och ger systemet en initial förmåga att korrigera etiketter.
Lärar‑elev‑samarbete för renare signaler
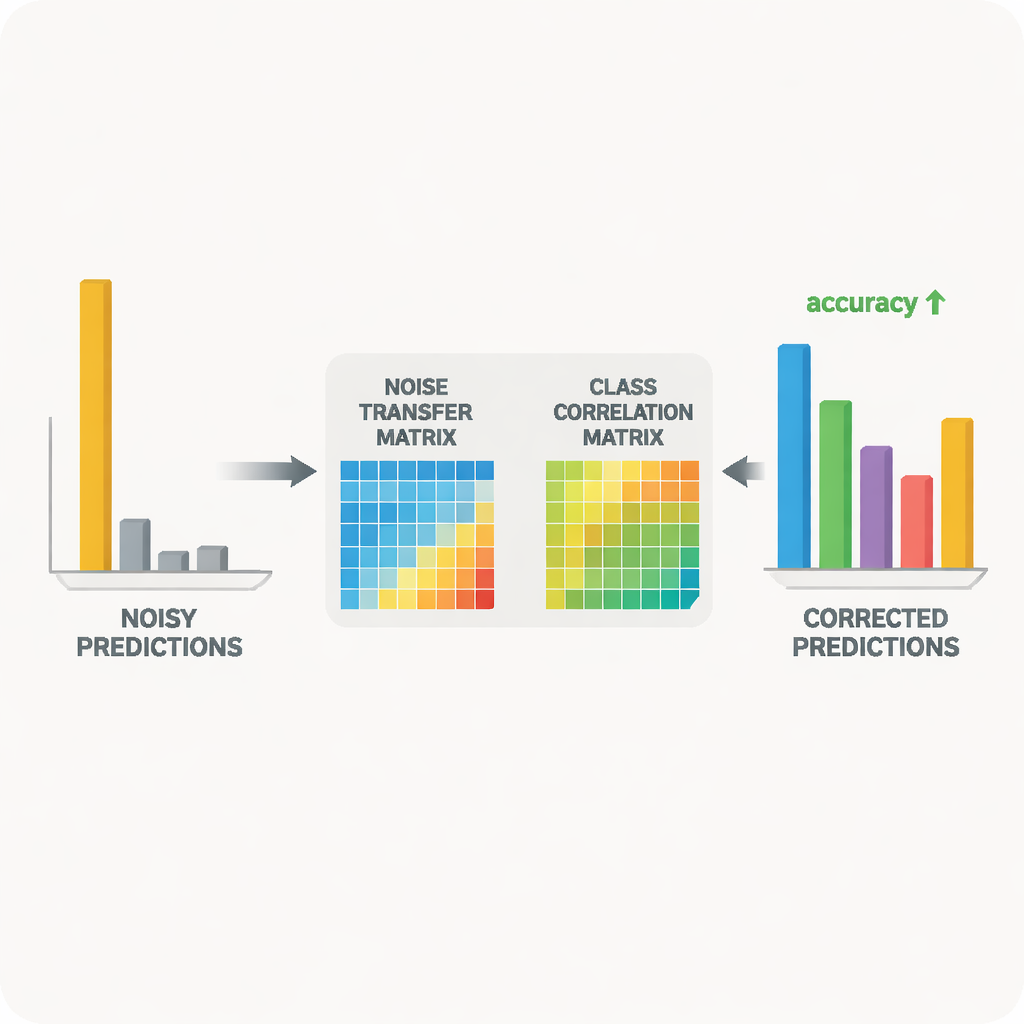
I hjärtat av systemet finns ett lärar‑elev‑par av neurala nätverk. Läraren bygger på en stor självövervakad visuellt modell som har lärt sig rika visuella representationer från massiv omärkt data. Eleven är ett lättare nätverk som måste prestera väl på den brusiga måldata. Läraren producerar mjuka prediktionspoäng som avslöjar hur olika klasser förhåller sig; från dessa poäng konstruerar metoden en klasskorrelationsmatris som sammanfattar vilka etiketter som tenderar att samförekomma. Denna matris fungerar som en vägvisare som styr brusöverföringsmatrisen mot mer realistiska korrigeringar. Samtidigt tränas eleven att efterlikna lärarens beteende genom en process känd som destillation, medan kontrastiv inlärning uppmuntrar båda nätverken att ge liknande interna representationer för olika augmenterade vyer av samma bild och avvikande representationer för olika objekt.
Hålla korrigeringarna stabila och undvika överdriven säkerhet
Att låta brusöverföringsmatrisen förändras fritt kan göra den instabil eller alltför känslig för avvikare. För att förhindra detta använder författarna ett matematiskt trick baserat på singulärvärdesuppdelning, som delar upp matrisen i grundläggande sträckningsriktningar. Genom att bestraffa den övergripande ”volymen” som antyds av dessa riktningar avskräcker metoden extrema deformationer som skulle förstärka brus. Ett annat problem uppstår när modellen blir för säker på sig själv och tilldelar nästan all sannolikhet till en enda klass; vid sådana skarpa prediktioner blir det svårt att rätta felmärkningar. För att hantera detta lägger metoden till en form av entropiregularisering, baserad på Tsallis‑entropi, som håller prediktionssannolikheterna mjukare. Detta gör det lättare för brusöverföringsmatrisen att delvis omfördela sannolikhetsmassa från en felaktig klass till mer sannolika alternativ.
Bevisa idén på verkliga bildsamlingar
Forskarna testade sin metod på två välanvända benchmarks för tvärdomäns objektigenkänning: Office‑31 och Office‑Home, som innehåller bilder av vardagliga kontorsföremål i flera stilar såsom produktbilder, clip art och verkliga snapshots. I en rad ”träna på en stil, testa på en annan”‑uppgifter matchade eller överträffade deras metod ledande algoritmer, särskilt i de svåraste fallen där skiftet mellan domäner är störst. Detaljerade studier visade att varje komponent—volymkontrollen för brusmatrisen, vägledningen från klasskorrelationen och entropiutjämningen—gav mätbara förbättringar. Visualiseringar av den inlärda matrisen och av funktionsrummet bekräftade att felmärkta exempel successivt drogs mot sina korrekta kategorier och att käll‑ och målbildsfördelningarna blev bättre anpassade under träningen.
Vad detta innebär för vardagliga AI‑system
För en icke‑specialist är huvudbudskapet att detta arbete gör AI‑modeller mer förlåtande för mänskliga och maskinella fel i datamärkning, särskilt när modellerna måste flytta från rena laboratorieförhållanden till rörigare verkliga miljöer. Genom att explicit lära sig hur etiketter tenderar att gå fel och använda en kraftfull lärarmodell för att vägleda korrigeringar kan metoden rensa upp brusiga träningssignaler och ge mer precisa, robusta klassificerare. Även om tillvägagångssättet kräver extra beräkning pekar det mot en framtid där stora, ofullkomliga datamängder som samlats in ”i det vilda” kan utnyttjas säkrare och effektivare, vilket minskar vårt beroende av tidsödande manuell annotering.
Citering: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Nyckelord: brusiga etiketter, domänanpassning, kunskapsdestillation, bildklassificering, semi‑övervakad inlärning