Clear Sky Science · sv
Riskkänsliga tvilling-distributionella kritiker med en lambda-lågkonfidensgräns för förstärkningsinlärning med kontinuerlig kontroll
Lära robotar att vara försiktiga
Många av dagens mest imponerande robotar och spelprogram bygger på förstärkningsinlärning, en trial-and-error-träningsprocess där mjukvaruagenter lär sig genom att samla belöningar. Men dessa agenter jagar ofta högsta möjliga poäng samtidigt som de ignorerar hur riskfyllda deras beslut är, vilket leder till instabil inlärning och ibland krascher. Den här artikeln presenterar en metod kallad TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound) som lär sådana agenter att inte bara sikta högt utan också att hålla sig pålitligt säkra medan de lär sig.
Varför stabilitet spelar roll i lärande maskiner
Standardalgoritmer för kontinuerlig kontroll, som de välkända TD3 och Soft Actor–Critic (SAC), har gjort det möjligt för robotar att springa, hoppa och balansera i komplexa simuleringar. Dessa metoder bedömer dock vanligen varje handling med ett enda tal: en uppskattning av hur mycket belöning den kommer att ge i längden. Den enkla poängen kan vara missvisande när inlärningsprocessen är brusig, vilket får systemet att överskatta hur bra vissa handlingar egentligen är. Resultatet blir en inlärningskurva som kan se stark ut i genomsnitt men svänger kraftigt mellan körningar, vilket är problematiskt om samma algoritm ska styra fysiska maskiner eller säkerhetskritiska system.
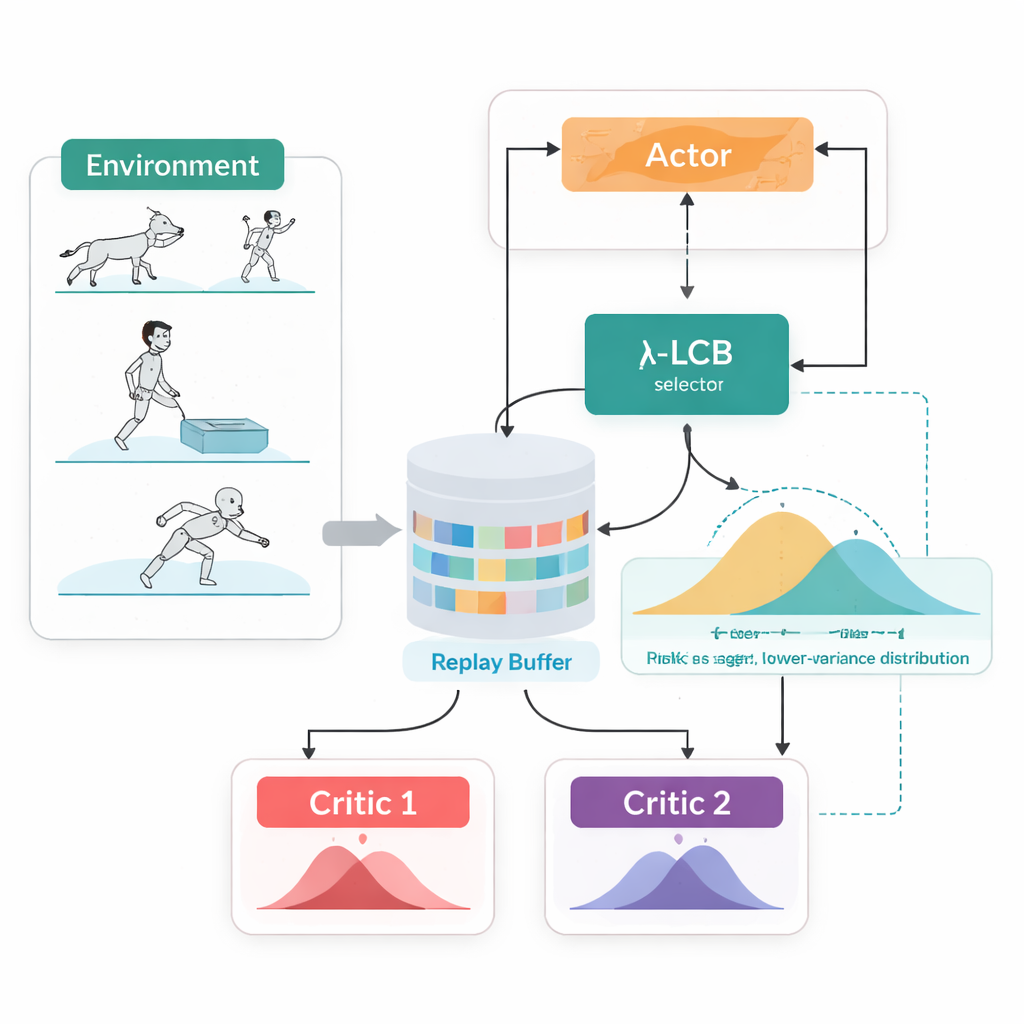
Titta på hela framtider, inte bara enstaka siffror
TDC-λ tar itu med detta problem genom att ändra hur agenten värderar sin framtid. Istället för att förutsäga bara en förväntad belöning för varje handling, lär den sig två separata "kritiker" som vardera ger en hel fördelningsfunktion över möjliga framtida utfall. Från dessa fördelningar beräknar algoritmen inte bara medelutfallet utan också hur utspridda möjligheterna är. Denna spridning speglar osäkerhet eller risk. Med en enkel regel, sammanfattad som en lågkonfidensgräns, föredrar TDC-λ den kritiker som förutspår ett säkrare utfall: en som kan vara något mindre optimistisk men stöds av mer konsekvent bevisning. En enda inställning, riskparametern λ, justerar smidigt hur försiktig detta val är — från att bete sig som en konventionell TD3-lik metod när λ är noll till att bli mer konservativ ju större λ är.
En träningsslinga, två sätt att agera
En annan praktisk egenskap hos TDC-λ är att den stödjer både deterministiska och stokastiska sätt att välja handlingar inom samma ramverk. Under träning kan användaren välja en klassisk deterministisk policy eller en tanh-squashad Gaussisk policy som sampler handlingar för att främja utforskning. Oavsett val tränas de dubbla distributionella kritikerna på samma sätt, och utvärdering använder alltid den deterministiska medelhandlingen. Denna design tar tillvara på tidigare fynd att deterministiskt beteende vid testtid ofta presterar lika bra eller bättre än sampling, samtidigt som den tillåter rika, utforskningsvänliga policies under inlärning.
Sätta metoden på prov
Författarna utvärderade TDC-λ på fem populära MuJoCo-benchmarkuppgifter där simulerade robotar som HalfCheetah, Hopper, Ant, Walker2d och Humanoid måste lära sig röra sig effektivt. I dessa uppgifter matchade eller förbättrade den nya metoden slutprestandan jämfört med starka referenser inklusive TD3, DDPG, SAC och en avancerad flow-baserad metod kallad MEOW, samtidigt som den konsekvent visade lägre variation över upprepade körningar. I svårare, högre-dimensionella uppgifter som Humanoid gav något högre λ‑värden — vilket innebär mer försiktiga måluppskattningar — de bästa långsiktiga avkastningarna och de snävaste prestandabanden. Ytterligare experiment i andra simulatorer (PyBullet och NVIDIA Isaac) och diagnostik som spårar variationen i inlärningssignalen förstärkte fyndet att TDC-λ gör inlärningen mer stabil utan att sakta ner den.
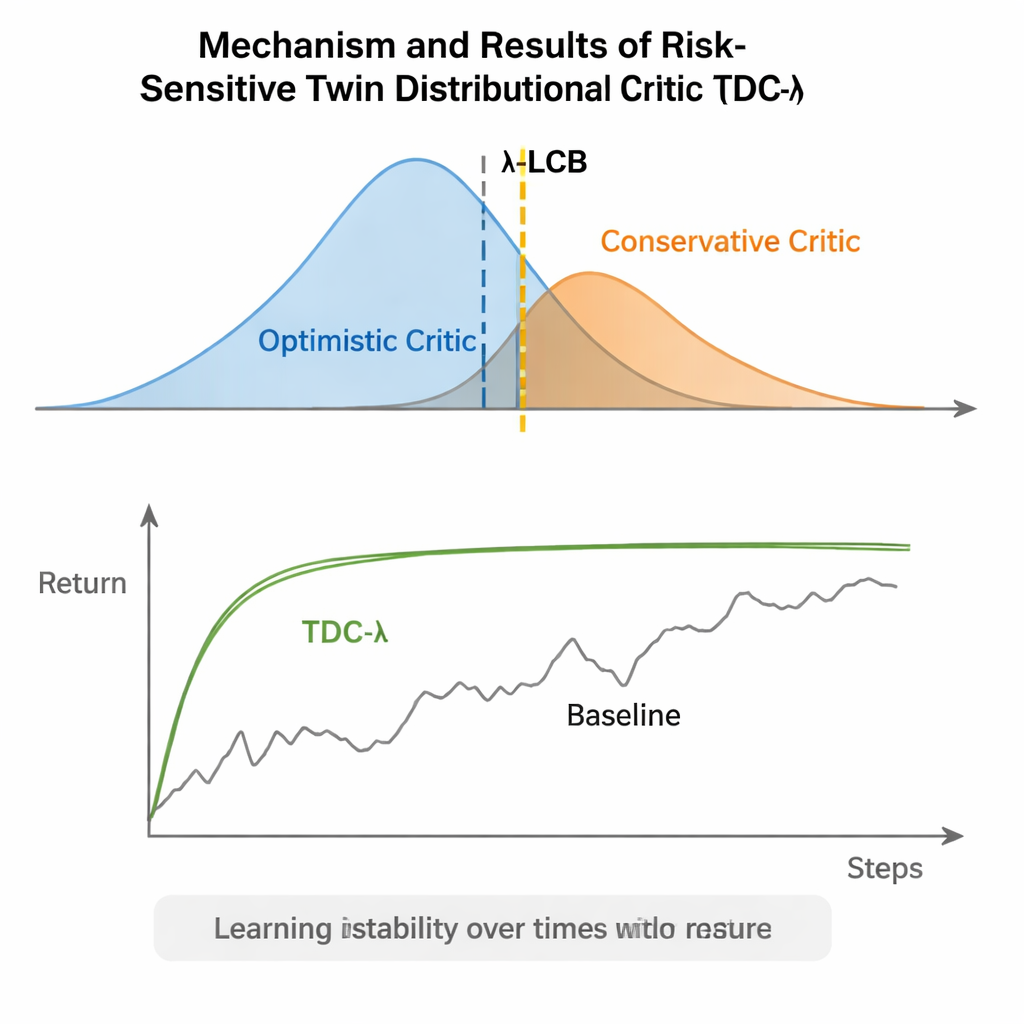
En enkel ratt för säkrare inlärning
I vardagliga termer ger TDC-λ förstärkningsinlärningssystem en "säkerhetsmarginal" när de beslutar hur mycket de ska lita på sin egen optimism. Genom att lära fulla fördelningar av möjliga utfall och sedan luta sig mot den säkrare kritikern med hjälp av λ-ratten minskar algoritmen vilda svängningar i träningen samtidigt som hög slutprestanda bevaras. För praktiker erbjuder detta ett praktiskt sätt att bygga mer tillförlitliga styrsystem för robotar och andra system med kontinuerlig kontroll: börja med ett måttligt konservativt λ och justera det utifrån hur volatil inlärningsprocessen verkar vara. Det bredare budskapet är att en noggrann utformning av vad agenten lär sig från — dess träningsmål — kan ge mycket av den robusthet som ofta tillskrivs mer komplexa arkitekturer, vilket gör avancerad förstärkningsinlärning både stadigare och mer tillgänglig.
Citering: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Nyckelord: förstärkningsinlärning, kontinuerlig kontroll, riskkänslig inlärning, distributionella kritiker, robotik