Clear Sky Science · sv
Modellering och tillämpning av komplexa drag vid Alzheimers sjukdomsprognos baserat på multitaskinlärning
Varför denna forskning är viktig för familjer och patienter
Alzheimers sjukdom är en av vår tids mest fruktade diagnoser, men läkare har fortfarande svårt att förutsäga vem som kommer att försämras snabbt, vem som förblir stabil under flera år och vilka tidiga tecken som verkligen är betydelsefulla. Denna studie ställer en enkel men kraftfull fråga: om vi ser flera Alzheimers-relaterade testresultat och hjärnavbildningar tillsammans och kombinerar dem med en persons genetiska information, kan modern artificiell intelligens då lära sig mönster som hjälper oss att förutse sjukdomsförloppet mer exakt?
Många ansikten av samma sjukdom
Alzheimers handlar inte bara om minnesförlust. Patienter skiljer sig åt i hur de presterar på kognitiva tester, hur väl de klarar vardagssysslor och hur deras hjärnavbildningar ser ut. Dessa olika mätningar — såsom vanliga minnes- och kognitionsskalor, frågeformulär om daglig funktion och PET-skanningar som visar hjärnans ämnesomsättning eller amyloidansamling — är kända för att till viss del påverkas av gener. Viktigt är att de också delar vissa av samma genetiska rötter. Traditionella prediktionsmetoder fokuserar oftast på en mätning i taget och går miste om den användbara insikten att dessa drag är relaterade. Författarna menar att modeller, likt en läkare som ser helheten istället för ett enskilt test, bör lära från flera egenskaper samtidigt.
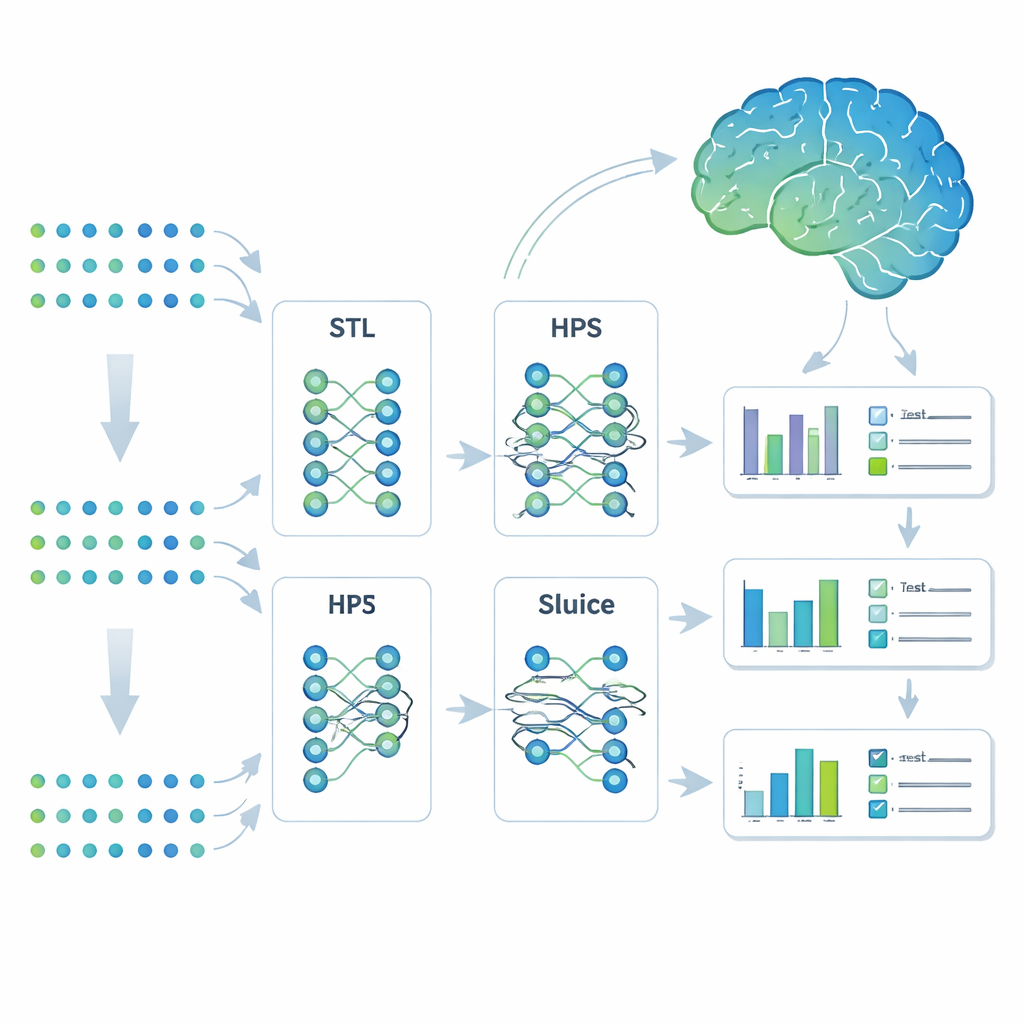
Att lära en modell flera besläktade uppgifter
Forskarna vände sig till en maskininlärningsstrategi kallad multitaskinlärning. Istället för att bygga separata modeller för varje utfall tränade de ett enda system för att förutsäga sju Alzheimers-relaterade drag samtidigt. De jämförde fyra angreppssätt: helt separata modeller (single-task learning), en enkel delad modell som bara skiljs åt i slutet (hard parameter sharing), en mer flexibel förgrening som kan dela uppgifter i undergrupper, och en högst anpassningsbar design kallad Sluice Network som kan finjustera hur mycket information som delas i varje lager i nätverket. Alla fyra modellerna såg samma genetiska ingångar; skillnaden låg i hur de delade det de lärt sig över olika drag.
Testa idéer i simulerade genom
Innan de litade på någon modell på verkliga patienter byggde teamet detaljerade simuleringar med verkliga genetiska mönster hämtade från Alzheimer’s Disease Neuroimaging Initiative (ADNI) men med utfall som de kunde kontrollera helt. De skapade scenarier där alla drag delade samma genetiska orsaker, där drag bildade överlappande grupper och där varje drag hade skilda orsaker. De varierade också hur starka de genetiska signalerna var och hur mycket brus de lade till, för att efterlikna den stökiga verkligheten i mänskliga data. I nästan alla förhållanden gav Sluice Network de mest korrekta prognoserna och förblev stabil även när dragen bara var svagt relaterade. Enklare delade modeller fungerade väl när dragen hade många genetiska gemensamma faktorer men sviktade när den delningen var låg, medan helt separata modeller var stabila men generellt mindre precisa.
Verkliga data och kraften i att gruppera gener
Författarna tillämpade sedan dessa modeller på verkliga ADNI-data från 463 individer, med nästan 3 800 genetiska markörer hämtade från 56 gener som tidigare kopplats till Alzheimer’s. Här lade de till en biologiskt inspirerad twist: istället för att mata in tusentals individuella genetiska markörer, grupperade de först markörer per gen och lät nätverket lära sig en kompakt ”sammanfattnings”-signal för varje gen innan de förutsade de sju utfallen. Denna aggregering på gen-nivå förbättrade prestandan för de flesta modeller och särskilt för Sluice Network, som ungefär fördubblade sin genomsnittliga korrelation med de verkliga utfallen. Förbättringarna var tydligast för PET-avbildningsmått och vissa kognitiva samt funktionella skalor, vilket tyder på att subtila genetiska effekter blir mer påtagliga när de kombineras på gen-nivå istället för att behandlas som isolerade markörer.
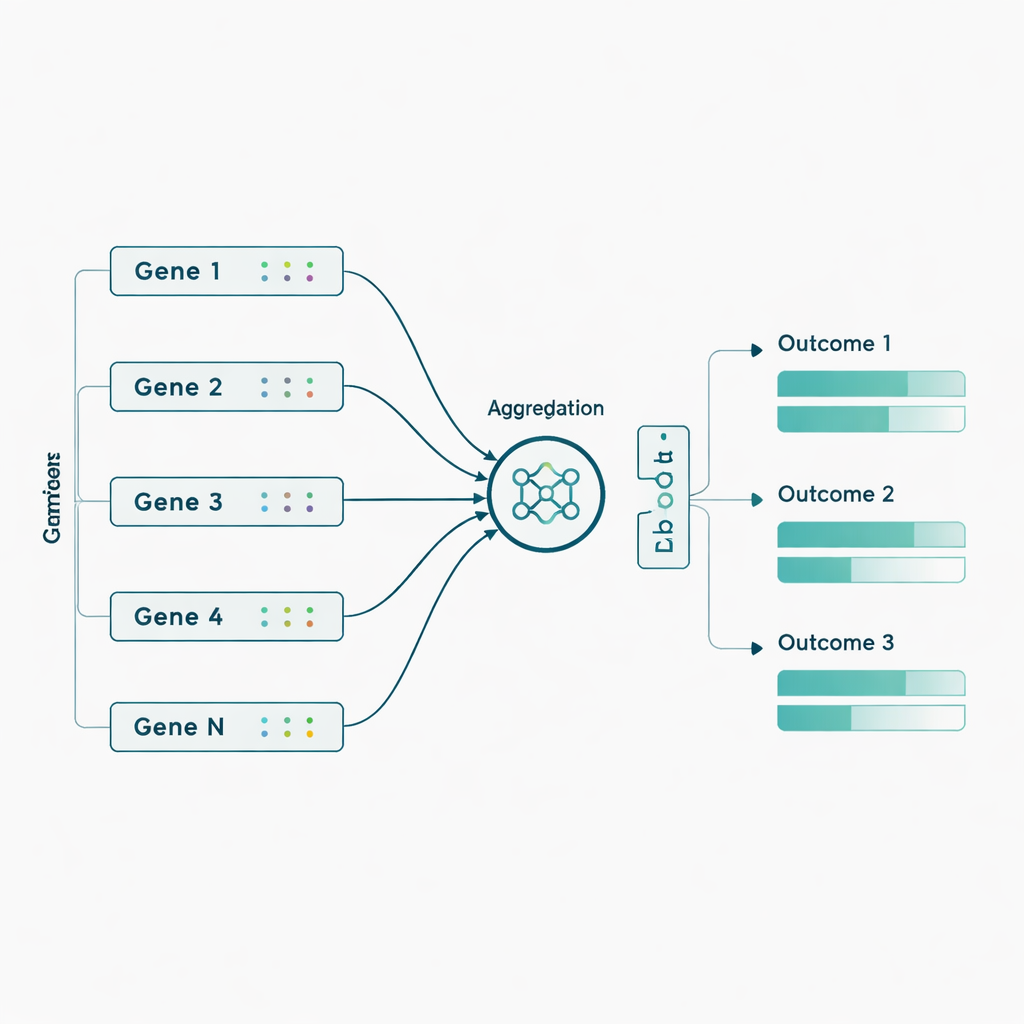
Vad detta betyder för framtida prognoser och vård
För en icke-specialist är budskapet att smartare, mer flexibla AI-modeller kan pressa fram mer insikt ur samma genetiska och kliniska data genom att lära av flera besläktade utfall samtidigt och genom att respektera hur biologin är organiserad i gener. Även om de nuvarande vinsterna är måttliga och långt ifrån ett kliniskt test, pekar angreppssättet mot mer tillförlitliga verktyg för att uppskatta en persons riskprofil, följa trolig sjukdomsutveckling och kanske anpassa övervakning eller interventioner. I komplexa sjukdomar som Alzheimer’s, där många små genetiska effekter samspelar, kan metoder som delar information över drag och aggregerar svaga signaler ge en klarare, mer informativ bild än traditionella enstaka mått.
Citering: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Nyckelord: Alzheimers sjukdomsgenetik, multitaskinlärning, djupinlärningsprognos, neuroavbildningsbiomarkörer, aggregering på gen-nivå