Clear Sky Science · sv
En jämförande analys av prestanda hos stora språkmodeller i specialisttentamen för tandvården
Varför smarta chattbotar spelar roll för framtidens tandläkare
Artificiell intelligens förändrar snabbt hur läkare och tandläkare lär sig och arbetar. Ett av de mest synliga verktygen är konversationsbaserade chattbotar drivna av stora språkmodeller — samma typ av teknik som ligger bakom många populära AI-assistenter. Denna studie ställer en enkel men viktig fråga: om tandstudenter använde dessa verktyg för att förbereda sig inför en hårt konkurrensutsatt specialisttentamen i oral- och maxillofacial radiologi, hur väl skulle maskinerna faktiskt klara sig?
Testade AI på ett verkligt prov
För att ta reda på det vände forskarna sig till Dentistry Specialization Entrance Examination (DUS) i Turkiet, som hjälper till att avgöra vem som kan börja avancerade utbildningsprogram. Ur tidigare år av detta nationella prov valde de ut 208 flervalsfrågor som täcker ämnen radiologispecialister måste bemästra, från strålningsfysik och bildtekniker till käktumörer och bihålesjukdomar. De flesta frågorna bestod endast av text, men en mindre del krävde tolkning av radiografiska bilder, vilket speglar diagnostiskt arbete i verkligheten.
Sju chattbotar ställs inför samma utmaning
Teamet ställde sedan varje fråga, på turkiska, till sju allmänt använda AI-chattbotar baserade på olika stora språkmodeller: två versioner av ChatGPT, plus Gemini, Copilot, DeepSeek, Claude och Grok. Varje fråga matades in noggrant och separat för att undvika överföring mellan konversationer. En andra forskare jämförde varje AI-svar med den officiella svarstangenten och markerade rätt eller fel. Slutligen använde författarna standardstatistiska tester för att jämföra modellerna totalt och inom specifika ämnesområden.
Vem fick högst poäng — och var snubblade de
Bland alla chattbotar utmärkte sig ChatGPT 4.0 och svarade rätt på ungefär 91 procent av frågorna. Copilot och Gemini följde tätt efter med noggrannhet i mitten till övre 80-talet, medan ChatGPT 4.5, DeepSeek, Claude och Grok hamnade något efter. När forskarna granskade ämnesområden gjorde modellerna särskilt bra ifrån sig inom oral patologi och spottkörtelsjukdomar, där noggrannheten närmade sig eller översteg 90 procent. I kontrast var radiografisk anatomi och förkalkningar i mjukvävnad märkbart svårare, vilket drog ner poängen över systemen och antyder områden där AI fortfarande kämpar med detaljrik precision.
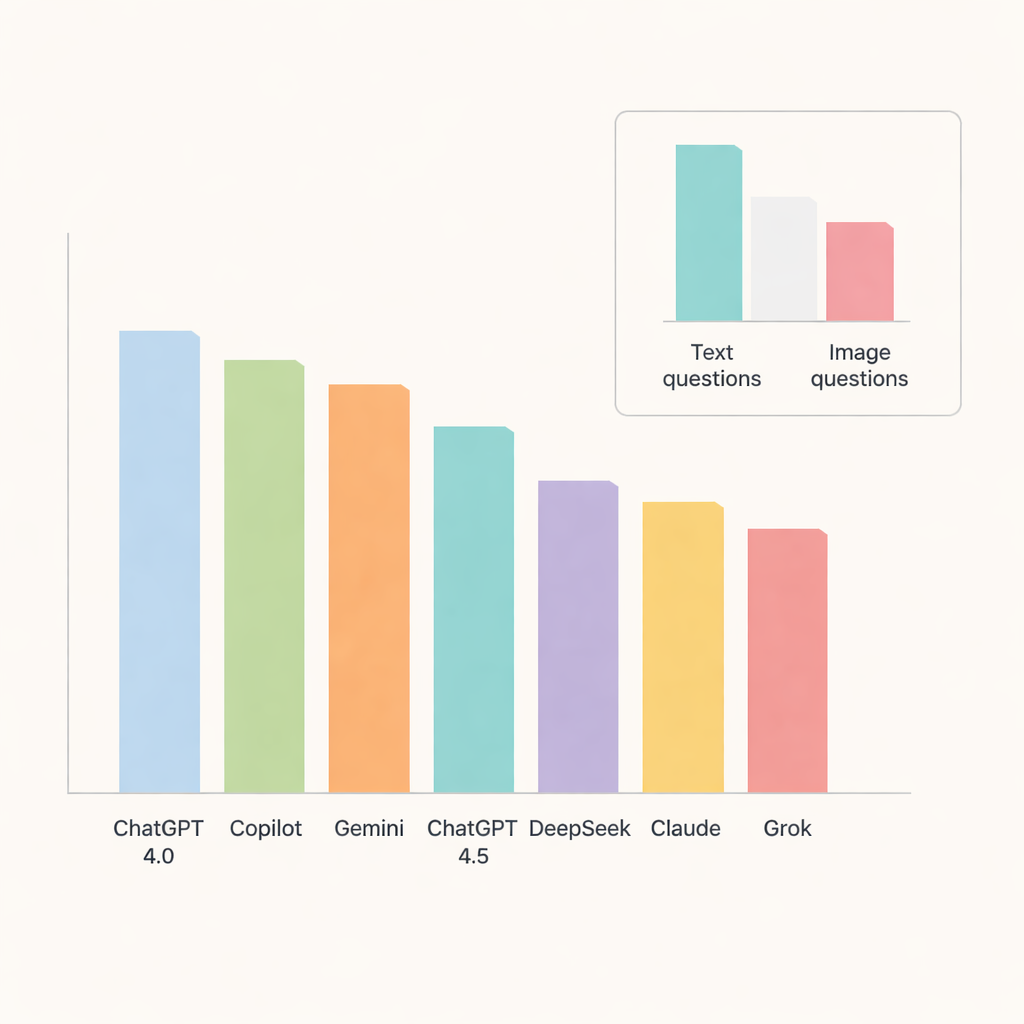
Bilder är fortfarande svårare än ord
Ett viktigt test var om chattbotarna kunde hantera bilder lika bra som text. Här blev deras begränsningar tydliga. Noggrannheten sjönk kraftigt på bildbaserade frågor, även för de bäst presterande modellerna. ChatGPT 4.0, Gemini och Copilot ledde i denna kategori men svarade ändå bara rätt på ungefär två tredjedelar av de visuella frågorna. DeepSeek klarade sig sämst på bilder, med knappt över en tredjedel rätt. För de flesta modeller var skillnaden mellan text- och bildprestanda tillräckligt stor för att vara statistiskt signifikant, vilket understryker att tolkning av medicinska bilder fortfarande är en svår uppgift för dagens allmänna AI.
Vad detta innebär för studenter och patienter
Studien landar i att moderna chattbotar kan vara kraftfulla hjälpmedel i tandvårdsutbildning, särskilt för att repetera fakta och öva tentamensliknande frågor i radiologi. Dock gör även de starkaste systemen tillräckligt många misstag — särskilt i visuellt krävande eller mycket specifika ämnen — för att de inte säkert kan ersätta expertbedömning. För studenter och kliniker är dessa verktyg bäst att betrakta som smarta studiepartners eller beslutsstöd, inte som fristående auktoriteter. Använda med lämplig försiktighet och tillsyn kan de påskynda lärande och öka tillgången till högkvalitativa förklaringar, samtidigt som det slutliga ansvaret för diagnos och behandling förblir hos utbildade yrkespersoner.
Citering: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Nyckelord: tandvårdsutbildning, artificiell intelligens, stora språkmodeller, oral- och maxillofacial radiologi, medicinska prov