Clear Sky Science · sv
Språkövergripande SMS-spamdetektion med GAN-baserad augmentering för obalanserade dataset
Varför dina textmeddelanden fortfarande behöver skydd
De flesta av oss litar på att oönskade meddelanden tyst hamnar i en skräppostmapp, men bakom kulisserna är det ett mycket svårt problem. Verkligt spam är sällsynt jämfört med vardagliga meddelanden, och det dyker i allt större utsträckning upp på flera språk samtidigt. Denna artikel presenterar ett nytt sätt att upptäcka farligt SMS‑spam genom att kombinera kraftfulla språkmodeller med en smart ”falsk data”-generator, så att filter kan lära sig från betydligt fler exempel på skadliga meddelanden utan att äventyra din integritet.
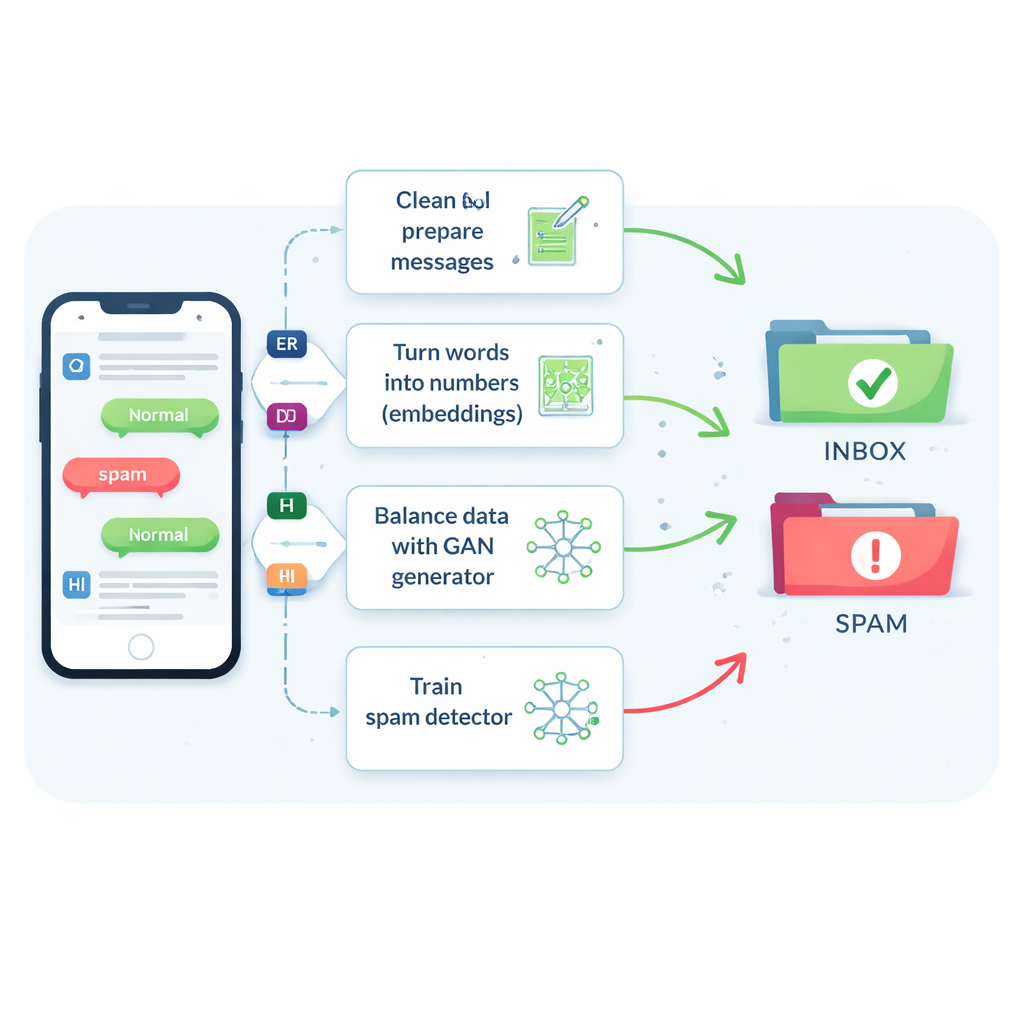
Problemet med sällsynt och formskiftande spam
Spam‑sms utgör bara ungefär ett av sju meddelanden, men att missa även en liten andel kan utsätta människor för bedrägerier, skadlig kod och identitetsstöld. Traditionella filter har svårt eftersom SMS är korta, fylla med slang och förkortningar, och kommer i realtid med liten extra kontext. Som en följd lutar många system mot att bedöma meddelanden som säkra, vilket gör användarna nöjda men låter fler skadliga meddelanden slinka igenom. Äldre knep som helt enkelt duplicerar spam eller skapar nya genom att justera ord kan hjälpa lite, men de förvirrar ofta filtret eller skapar orealistiska exempel som inte stämmer med vad kriminella faktiskt skickar.
Att lära maskiner förstå meddelandets betydelse
Författarna börjar med att jämföra åtta olika inlärningsalgoritmer, från välkända verktyg som supportvektormaskiner och beslutsstammar till mer avancerade neurala nätverk som läser text som en sekvens, såsom LSTM‑nätverk. De testar också fem sätt att omvandla ord till siffror som en dator kan använda. Enkla räkningar av hur ofta varje ord förekommer (kända som bag-of-words eller TF–IDF) är snabba men blinda för mening. Nyare ”inbäddningar” som Word2Vec och GloVe placerar ord med liknande betydelser nära varandra i ett numeriskt rum. Mest avancerade är transformerbaserade modeller som BERT, som justerar ett ords representation beroende på den omgivande meningen, vilket hjälper systemet att skilja till exempel en vänlig påminnelse från ett övertygande bedrägeri.
Använda smart “falskt” spam för att åtgärda ett snedvridet dataset
Den centrala nyheten är hur studien tar itu med bristen på spamexempel. Istället för att generera hela falska meningar tränar teamet en typ av neuralt nätverk som kallas Generative Adversarial Network (GAN) direkt på de numeriska inbäddningarna av spammeldelanden. En del av GAN:en, generatorn, lär sig skapa syntetiska spamliknande punkter i detta högdimensionella rum, medan en annan del, diskriminatorn, lär sig skilja dem från verkliga. Genom denna rivalitet producerar generatorn realistiska nya spaminbäddningar som utökar träningsmängden. En kvalitetskontroll baserad på likhet säkerställer att endast syntetiska exempel som liknar äkta spam behålls, vilket minskar risken för nonsensdata som kan vilseleda klassificeraren.
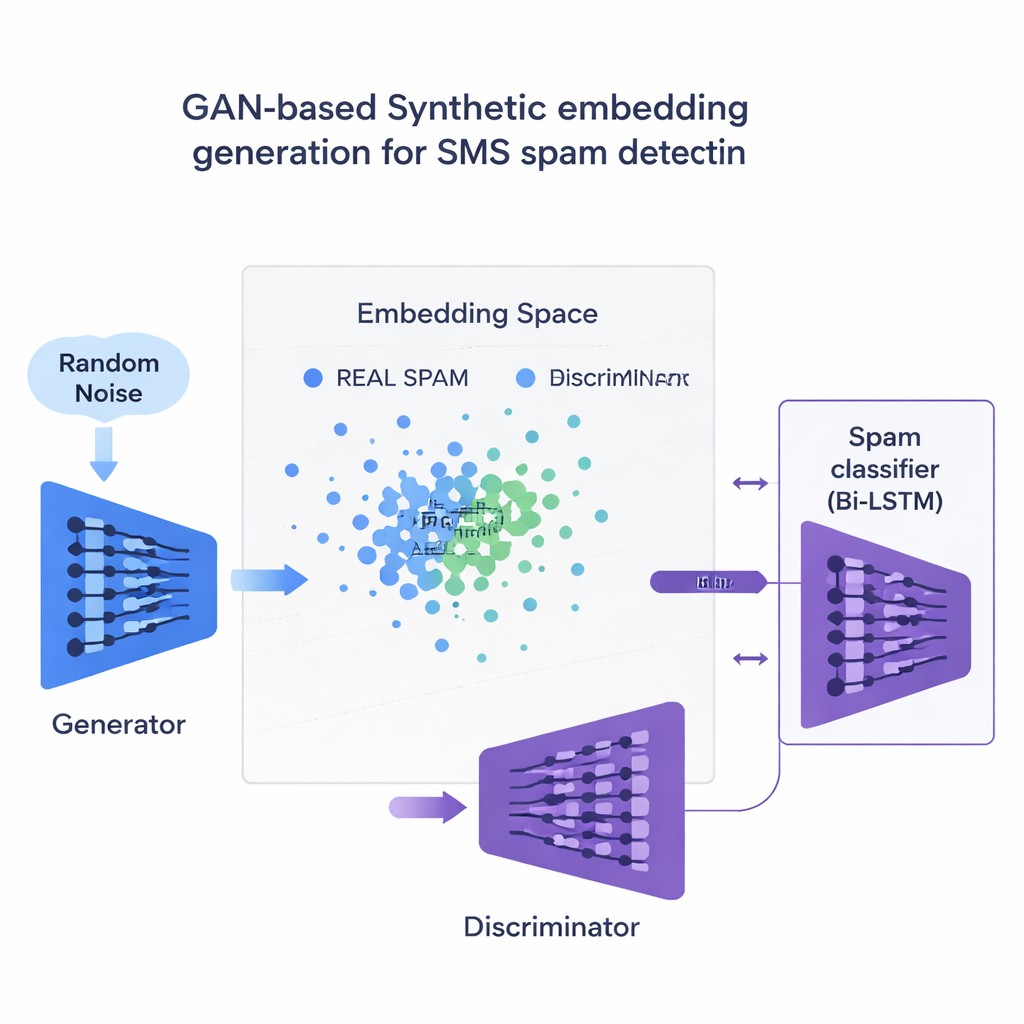
Resultat över språk och enheter
Forskarna testar 120 olika kombinationer av modeller, inbäddningar och metoder för databalansering, både på ett engelskt SMS‑dataset och på en flerspråkig version översatt till franska, tyska och hindi. Överlag överträffar kontextuella inbäddningar som BERT äldre ord‑räknemetoder. Den bästa uppsättningen — en bidirektionell LSTM matad med BERT‑inbäddningar och tränad med GAN‑genererade spamexempel — når ett F1‑värde kring 97,6 % på engelska meddelanden och 94,4 % på det flerspråkiga setet, och slår därmed befintliga toppresultat. Avgörande är att den gör detta samtidigt som falsklarm hålls extremt låga, ett viktigt krav så att engångslösenord och bankaviseringar inte av misstag göms från användarna. Studien jämför också denna GAN‑strategi med mer vanliga balanseringsverktyg som SMOTE och ADASYN, och finner att GAN ger renare, mer realistiska träningsdata och något bättre total prestanda.
Vad detta betyder för vardagsanvändare
För icke‑specialister är slutsatsen att spamfilter börjar förstå innebörden och kontexten i dina meddelanden, inte bara enskilda ord, och kan ”läras” med noggrant utformad syntetisk data istället för att behöva se fler av dina riktiga texter. Genom att arbeta direkt i det rum där meddelandets betydelse kodas ger den föreslagna metoden säkerhetssystemen en rikare bild av hur spam ser ut på många språk, utan att översvämma dem med klumpiga förfalskningar. Det gör det mer sannolikt att farliga meddelanden fångas och äkta levereras, vilket erbjuder ett starkare, mer anpassningsbart skydd för mobilanvändare i takt med att bedragare ändrar sina taktiker.
Citering: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Nyckelord: SMS-spamdetektion, GAN-dataaugmentering, BERT-textinbäddningar, multilingual cybersäkerhet, mobil nätfiske