Clear Sky Science · sv
En lättviktsarkitektur för konvolutionellt neuralt nätverk för våldsdetektion i videosekvenser
Att bevaka folkmassor så att människor inte behöver göra det
Från konserter och sportarenor till tunnelbanestationer och köpcentrum — kameror övervakar nu nästan varje trångt utrymme. Ändå granskas de flesta videoströmmar fortfarande av trötta mänskliga ögon som lätt kan missa de första tecknen på slagsmål eller en stampnad. Denna artikel undersöker hur en slank, snabb form av artificiell intelligens kan skanna livevideo efter våldsamt beteende i realtid, även på billig hårdvara, och hjälpa säkerhetspersonal att reagera snabbt innan situationer urartar.
Varför det är så svårt att upptäcka våld i video
Vid en första anblick låter det enkelt att be en dator skilja "slagsmål" från "ingen fara": upptäck bara personer som slår varandra. I verkligheten är problemet rörigt. Belysningen kan vara dålig eller förändras plötsligt, folkmassor kan skymma sikten och kameror sitter i många olika vinklar. En fullpackad rockkonsert ser kaotisk ut även när inget farligt händer, medan en boxningsmatch ser våldsam ut men är helt normal inne i ringen. Traditionella visionssystem tittade på handgjorda rörelsemönster och kanter bild för bild, och även om de fungerade i labbet var de ofta för långsamma eller för inexakta för upptagna, verkliga övervakningsnätverk.
En smidigare hjärna för kameraflöden
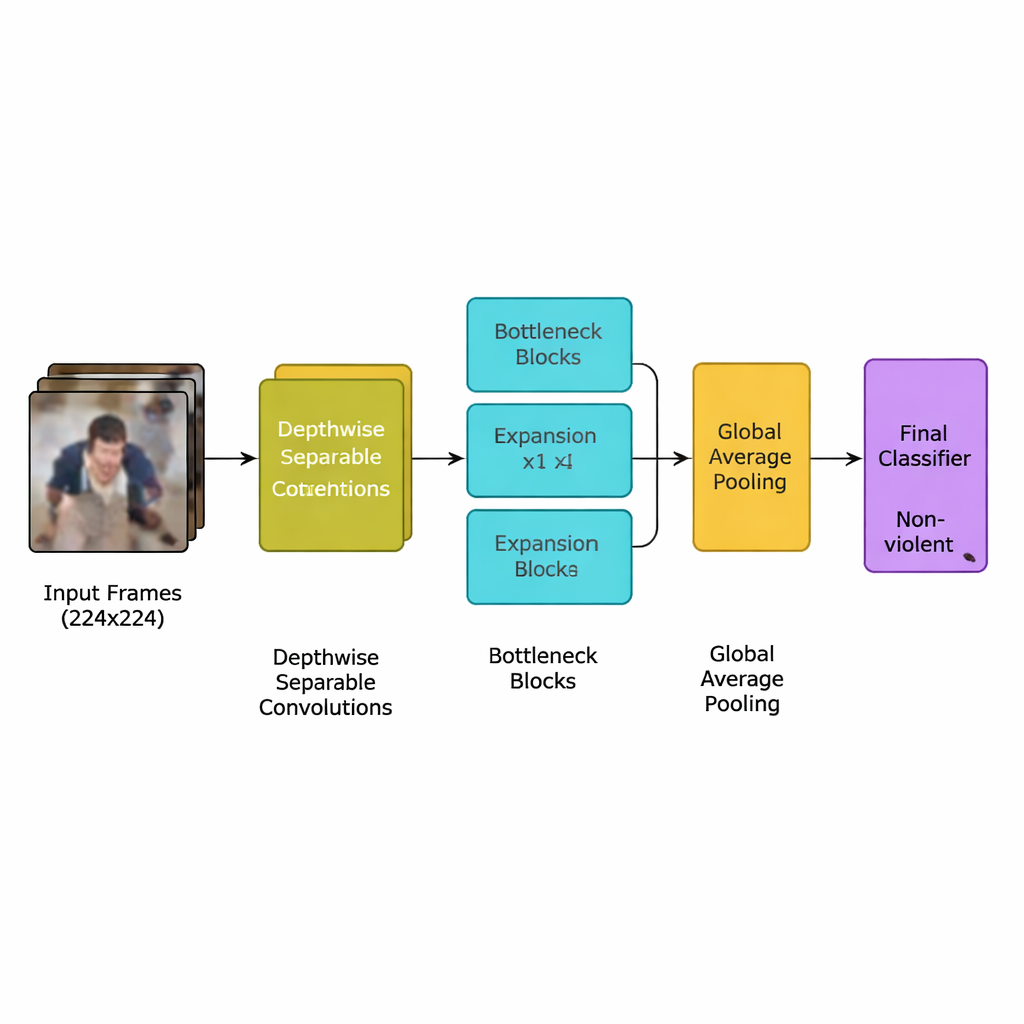
Författarna presenterar en ny djupinlärningsmodell speciellt utformad för denna uppgift: ett lättvikts konvolutionellt neuralt nätverk (CNN) härlett från en effektiv modellfamilj känd som MobileNetV2. Istället för att använda många tunga lager som kräver kraftfulla grafikprocessorer förlitar sig nätverket på depthwise separable‑konvolutioner — små, riktade beräkningar som drastiskt minskar antalet operationer. Det använder även så kallade "inverted bottleneck"‑block, som kortvarigt expanderar och sedan komprimerar information för att behålla viktiga rörelseledtrådar samtidigt som redundans tas bort. Utöver detta lägger teamet till en uppmärksamhetsmekanism kallad squeeze‑and‑excitation, som hjälper nätverket att fokusera på de rums‑ och tidsmönster i rörelse som är mest typiska för våldsamma incidenter, samtidigt som störande bakgrundsdetaljer ignoreras.
Från råvideo till våldsvarningar
Hela systemet följer en tydlig pipeline. Först bryts videoströmmar ner i bildrutor och bara var femte ruta behålls för att ta bort närapå‑duplikat samtidigt som plötsliga rörelser som ofta signalerar ett slagsmål bevaras. Bildrutorna skalas till standarden 224×224 pixlar, mjukt suddas för att minska bakgrundsbrus och speglas eller roteras slumpmässigt under träning så att modellen lär sig hantera olika kameravyer. Dessa förberedda bilder matas in i lättvikts‑CNN:en, som gradvis omvandlar råa pixlar till högre nivåers mönster av folkbeteende. Efter ett slutligt pooling‑steg som sammanfattar varje ruta ger en liten klassificerare ett enkelt beslut: våldsamt eller icke‑våldsamt. Eftersom modellen använder bara omkring 1,94 miljoner parametrar — mindre än sina MobileNet‑ och MobileNetV2‑föregångare — kan den köras i realtid på blygsamma enheter placerade nära kamerorna istället för i ett avlägset datacenter.
Sätta systemet på prov
För att ta reda på om denna kompakta design kunde konkurrera med större nätverk tränade och utvärderade forskarna modellen på två allmänt använda benchmarks. Real‑Life Violence Situations Dataset innehåller 2 000 korta klipp hämtade från YouTube som visar både vardagsscener och verkliga slagsmål i varierande miljöer. Hockey Fight Dataset erbjuder 1 000 klipp från professionella hockeymatcher, fördelade mellan vanlig spel och slagsmål på isen. På dessa datasätt märkte den föreslagna modellen korrekt ungefär 97 procent av klippen i verkliga scenarier och 94 procent i hockeyklipp, vilket matchar eller överträffar större CNN:er som InceptionV3 och VGG‑19 samtidigt som den använder betydligt färre beräkningar. Korsprovning mellan de två datasätten — träna på det ena och testa på det andra — visade att systemet fortfarande presterade rimligt väl, vilket tyder på att det fångar generella rörelsemönster snarare än att memorera en enskild miljö.
Vad detta betyder för vardagssäkerhet
För icke‑experter är huvudslutsatsen att det nu är möjligt att bygga kamerasystem som automatiskt flaggar sannolikt våld snabbt och billigt, utan behov av jättelika servrar eller konstant mänsklig uppmärksamhet. Studien visar att ett omsorgsfullt beskuret och finjusterat neuralt nätverk kan övervaka många strömmar samtidigt, skicka larm när det upptäcker farligt beteende och fortfarande köras på låg‑effekt hårdvara lämplig för kollektivtrafiknav, skolor, sjukhus och stadsgator. Trots att utmaningar återstår — såsom att hantera mycket mörka scener, kraftig trängsel eller att lägga till ljudelement — pekar arbetet mot en framtid där smarta kameror fungerar som outtröttliga tidiga varningssensorer och hjälper säkerhetsteam att skydda människor mer effektivt samtidigt som bördan på mänskliga observatörer minskar.
Citering: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Nyckelord: våldsdetektion, videoövervakning, lättvikts‑CNN, MobileNetV2, allmän säkerhet