Clear Sky Science · sv
MSRCTNet: ett nytt flerskaligt kapsel‑tripletnätverk för effektiv borttagning av redundanta bildrutor i trådlösa kapselendoskopivideor
Svälja en kamera, drunkna i bilder
Föreställ dig att diagnostisera mag‑tarmsjukdomar genom att svälja en vitaminstor kamera som tyst fotograferar hela din matsmältningskanal. Trådlös kapselendoskopi gör detta redan möjligt, men varje undersökning ger cirka 55 000 bilder, där de flesta ser nästan likadana ut. Läkare måste sålla igenom denna visuella ström för att upptäcka små fläckar av blödning, inflammation eller tumörer. Studion bakom MSRCTNet ställer en enkel men avgörande fråga: kan ett intelligent system säkert kasta bort likartade bildrutor så att läkare bara ser det som verkligen betyder något?
Varför för många bilder kan vara ett problem
Konventionell endoskopi kräver ett flexibelt rör som förs in genom munnen eller ändtarmen — ett ingrepp många patienter upplever som obehagligt och som inte alltid når hela tunntarmen. Kapselendoskopi löser detta genom att låta en pillerkamera driva genom tarmen och ta bilder varje sekund. Nackdelen är överbelastning: bara omkring 1 % av bildrutorna innehåller tydligt användbar information, medan resten oftast upprepar samma veck av vävnad. Att granska sådana mängder är långsamt och tröttande, vilket ökar risken att en utmattad kliniker missar en subtil lesion. Tidigare datormetoder försökte hjälpa genom att klustra liknande rutor, komprimera data eller förlita sig på enkla färg‑ och texturindikatorer, men de misslyckades ofta när belysningen förändrades, tarmen rörde sig på komplexa sätt eller sällsynta avvikelser förekom i bara ett fåtal exempel.
En smartare metod för att upptäcka upprepning
MSRCTNet (Multi‑Scale Capsule Triplet Network) är ett djuplärandesystem utformat för att fungera som ett intelligent filter för kapselvideor. Istället för att behandla varje bild som en platt vy undersöker systemet mönster i flera skalor samtidigt — finare texturer i tarmludden och bredare former i tarmväggen — samtidigt som en uppmärksamhetsmekanism betonar de mest informativa detaljerna. Dessa berikade egenskaper förs sedan in i ett kapselliknande lager som bevarar hur delar av bilden förhåller sig till varandra i rummet, såsom orientering och arrangemang av veck eller lesioner. Slutligen jämför en specialiserad likhetsmodul tripletter av bildrutor — en referensbild, en som bör vara lik och en som bör vara olik — för att lära en representation där verkligt redundanta rutor klustrar tätt ihop och distinkta rutor står isär.
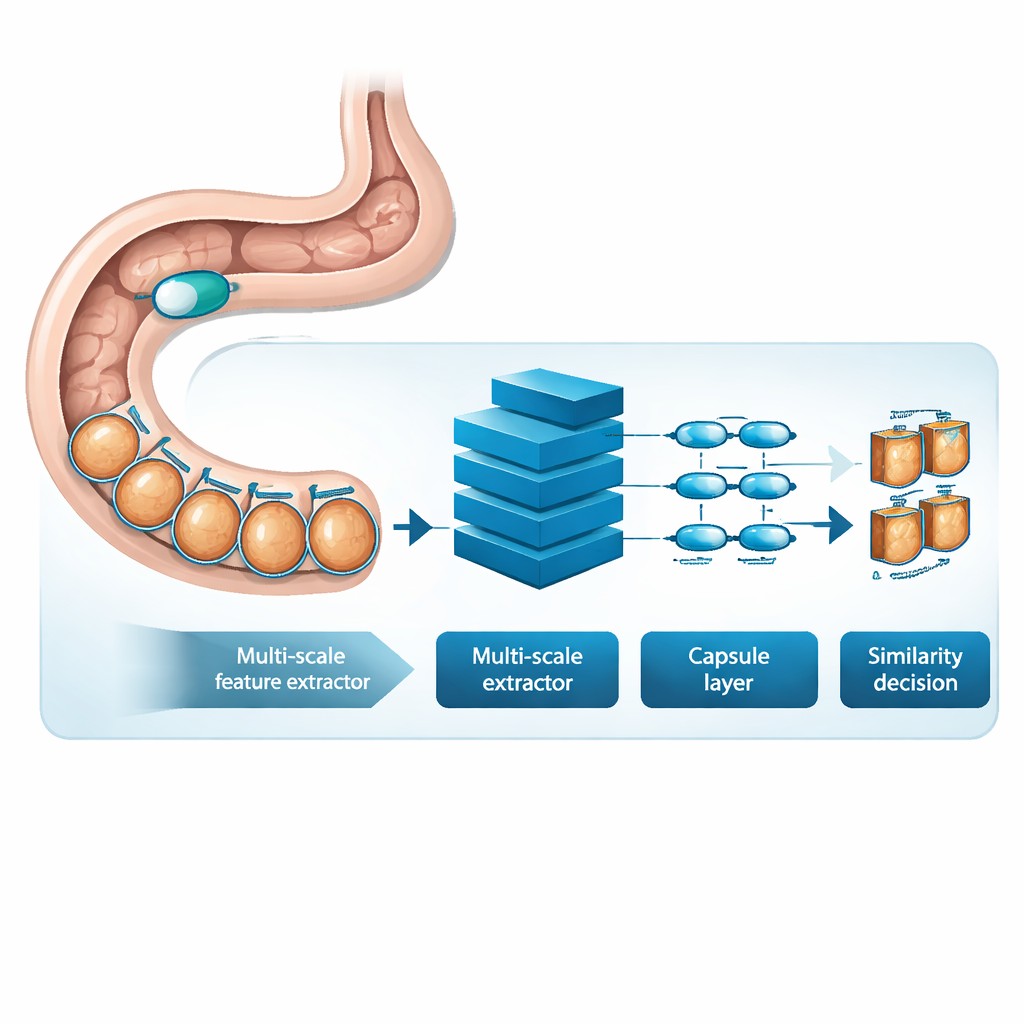
Lärande från riktiga patientundersökningar
För att testa MSRCTNet samlade forskarna en stor dataset med 257 362 bilder från 60 kapselundersökningar utförda på ett sjukhus i Kina. Bilderna inkluderade normal vävnad, områden dolda av bubblor och tydliga avvikelser som blödning och inflammation, alla märkta av erfarna kliniker. Systemet tränades att bedöma om par av rutor var liknande eller inte, med en kombination av två inlärningsmål: ett som drar ihop rutor från samma kategori och skjuter isär dem från olika kategorier, och ett annat som lär nätverket att direkt avgöra om ett par är likt. När modellen väl var tränad granskar den en video tre rutor i taget och bestämmer vilka av grannrutorna som verkligen är redundanta. Genom att tillämpa enkla regler på dessa likhetsbeslut kasserar den upprepade vyer samtidigt som representativa nyckelrutor behålls.
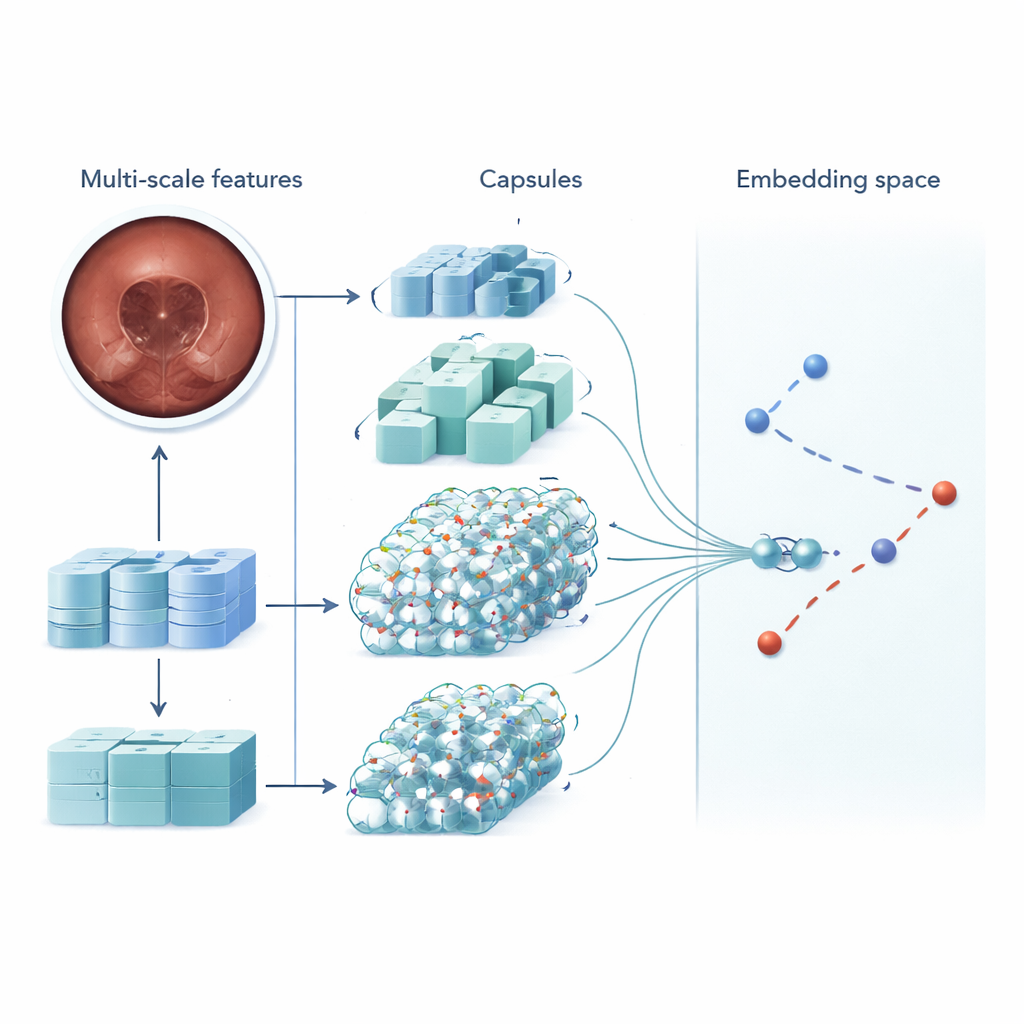
Hastighet, noggrannhet och färre missade problem
På testdata hanterade MSRCTNet korrekt ramredundans i omkring 96 % av fallen, med en falsklarmfrekvens under 3 % och en missad‑ruta‑frekvens under 0,2 %. I praktiken motsvarar detta för en 50 000‑ruters undersökning att färre än 100 potentiellt relevanta rutor missas — tillräckligt få för att omgivande bilder fortfarande ge kontext vid sex rutor per sekund. Jämfört med flera tidigare tekniker baserade på klustring, rörelseanalys eller enklare neurala nätverk var MSRCTNet både mer exakt och mer robust när data var obalanserade, det vill säga när normala bilder vida översteg sällsynta lesioner. Systemet kördes också snabbt: ungefär 0,02 sekunder per ruta, eller omkring 15 minuter för att krympa en hel undersökning till cirka 2 500 nyckelrutor — en volym som är mycket mer hanterbar för manuell granskning.
Vad detta betyder för patienter och läkare
För patienter förändrar framsteget som beskrivs i denna artikel inte kapseln de sväljer, men det kan göra deras undersökning mer effektiv. Genom att automatiskt rensa bort nästan identiska bilder utan handjusterade trösklar eller sköra heuristiker låter MSRCTNet kliniker fokusera sin uppmärksamhet på en kort, informationsrik sammanfattning av resan genom tarmen. Metoden bevarar kliniskt viktiga fynd samtidigt som den minskar trötthet och tid vid granskningsstationen, vilket potentiellt gör icke‑invasiva kapselundersökningar mer attraktiva och allmänt använda. I praktiken förvandlar metoden en ström av bilder till ett omsorgsfullt kurerat höjdpunktsklipp och för AI‑löftet ett steg närmare vardaglig vård av mag‑tarmsjukdomar.
Citering: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Nyckelord: trådlös kapselendoskopi, sammanfattning av medicinska videor, djuplärande, borttagning av redundanta bildrutor, gastrointestinal avbildning