Clear Sky Science · sv
DNS-fingeravtryck baserat på användaraktivitet
Varför dina webbbesök lämnar ett dolt spår
Varje gång du surfar skickar din dator tyst en fråga till en särskild slags adressbok, kallad Domain Name System (DNS), om hur den når varje webbplats. De frågorna försvinner inte bara. Över dagar och veckor bildar de ett mönster av vilka typer av sidor du besöker, när och hur ofta. Denna artikel visar att dessa mönster är tillräckligt distinkta för att fungera som ett beteendemässigt fingeravtryck, vilket gör det möjligt för kraftfulla algoritmer att skilja användare åt — även om deras synliga IP-adress ändras — vilket skapar både möjligheter för säkerhet och allvarliga frågor kring integritet.
Internetets telefonkatalog och dina vanor
DNS finns för att översätta lättlästa webbadresser, som www.google.com, till de numeriska IP-adresser som datorer använder för att kommunicera. De flesta tänker aldrig på det, men varje sökning, videoström, e-postkontroll eller appuppdatering utlöser en eller flera DNS-förfrågningar. Dessa förfrågningar hanteras vanligtvis av lokala eller publika DNS-servrar och loggas som enkla poster: vilken IP-adress som frågade om vilken domän och när. Samla tillräckligt många av dessa poster och du får en detaljerad bild av vilka slags onlinetjänster en användare förlitar sig på, från affärsverktyg och molnlagring till sociala nätverk och strömningstjänster. Medan tidigare forskning använt dessa spår för att upptäcka skadlig kod eller identifiera enhetstyper, ställer denna studie en mer direkt fråga: kan de exakt lokalisera enskilda användare eller maskiner enbart utifrån deras återkommande DNS-beteende?
Att förvandla dagliga klick till ett beteendefingeravtryck
Författarna bygger på en stor, offentligt tillgänglig DNS-datamängd som samlats in från en lokal internetleverantör under tre månader. Varje dag aggregerar de DNS-aktivitet för varje aktiv IP-adress till en kompakt sammanfattning: antal förfrågningar totalt, hur många olika domäner som kontaktades och, avgörande, hur dessa domäner fördelar sig över 75 innehållskategorier som till exempel ”Allmän affärsverksamhet”, ”Programvara / Hårdvara” eller ”Sociala nätverk”. De behåller bara IP-adresser som förekommer minst 80 procent av dagarna, för att säkra tillräcklig historik per användare, och tar försiktigt bort redundanta eller nästan tomma funktioner. De använder också statistiska verktyg för att upptäcka starkt korrelerade fält, filtrera bort extrema avvikare i förfrågningsvolym och komprimerar därefter datan med principal component analysis så att den mesta användbara variationen bevaras i betydligt färre dimensioner. Genom att visualisera den rengjorda datan med en teknik kallad t‑SNE finner de att många IP-adresser bildar täta, välseparerade kluster — ett tidigt tecken på att automatisk klassificering kan vara genomförbar.
Att sätta maskininlärningsmodeller på prov
Med detta bearbetade datamaterial i handen behandlar teamet användaridentifiering som ett massivt klassificeringsproblem: givet en dags DNS-statistik, avgör vilken av 1 727 IP-adresser den tillhör. De jämför en rad modeller, från klassiska metoder som Naive Bayes och Random Forests till mer avancerade verktyg som XGBoost och djupa neurala nätverk. Varje modell tränas och valideras på olika versioner av datan (rå, omskalad, standardiserad eller dimensionsreducerad) och utvärderas efter hur ofta den korrekt tilldelar rätt klass, tillsammans med mått på precision och recall. Traditionella modeller presterar hyfsat — Random Forests når omkring 73 procents noggrannhet, och XGBoost överstiger 81 procent samtidigt som den korrekt särskiljer mer än 99 procent av alla klasser. Men de verkligt framstående är de neurala nätverken, särskilt ett anpassat konvolutionellt neuralt nätverk (CNN) som behandlar funktionsvektorn som en endimensionell bild av dagligt beteende.
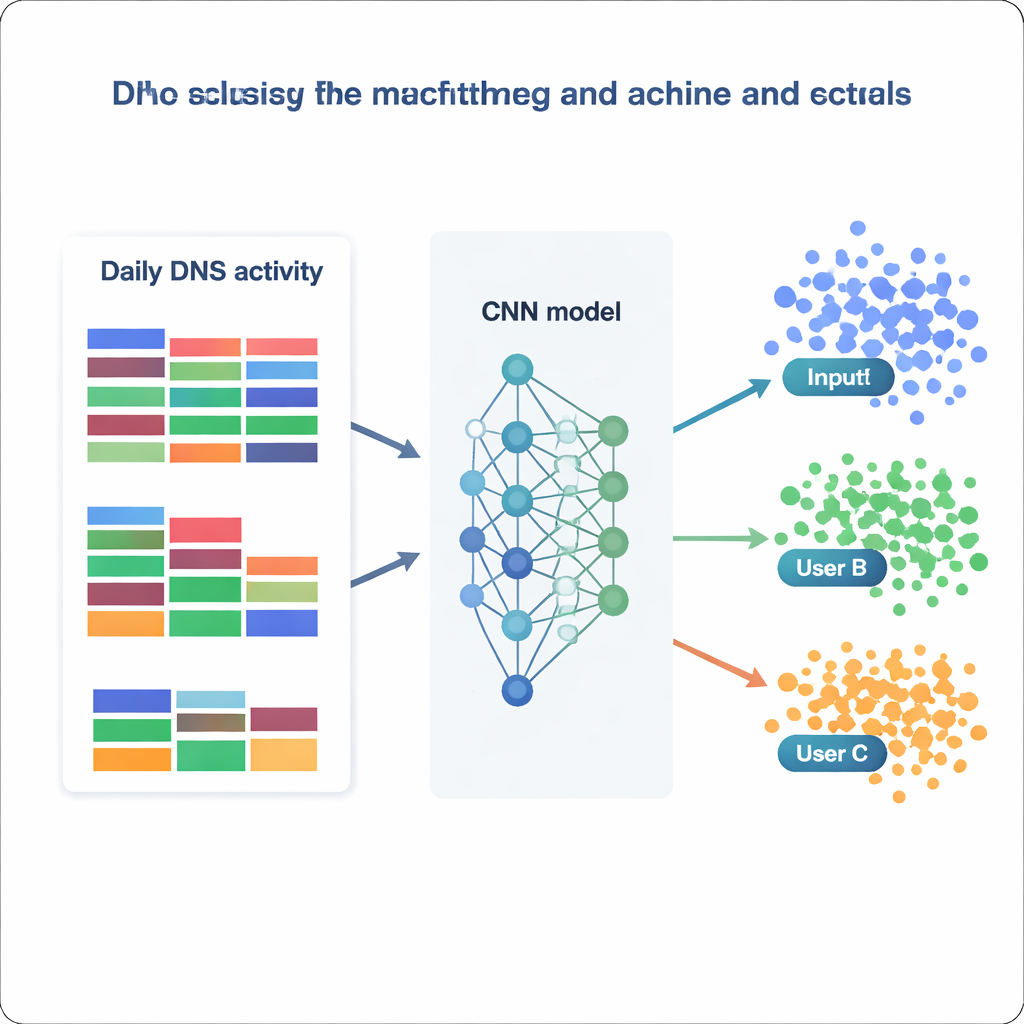
Hur väl kan en modell veta "vem" du är?
Det bästa CNN:et, tränat på normaliserad data, identifierar korrekt käll-IP på nästan 87 procent av de hållna dagarna och förutser framgångsrikt 1 694 av de 1 727 distinkta IP-adresserna. I praktiska termer innebär detta att de flesta användare — eller små grupper som döljer sig bakom en delad IP — uppvisar stabila, igenkännbara DNS-mönster över tid. Genom att undersöka vilka funktioner modellerna förlitar sig mest på finner författarna två kompletterande strategier. Vissa modeller lutar tungt mot mycket vanliga kategorier, såsom allmän affärsverksamhet eller programvarutjänster, och fångar breda vanor. Andra, som XGBoost, får extra styrka från sällsynta men avslöjande kategorier kopplade till säkerhet, politik eller nischintressen. Tillsammans visar dessa resultat att även enkla, aggregerade statistiker — utan att titta på hela listan av domännamn — kan koda in tillräcklig struktur för att återskapa användares identitet med slående tillförlitlighet.
Löften, begränsningar och integritetsrisker
För brottsbekämpning och nätverksförsvar kan DNS-fingeravtryck bli ett värdefullt verktyg för att spåra återfallsförbrytare, upptäcka komprometterade maskiner eller identifiera botnät som använder ändrade IP-adresser för att undvika blockering. Samtidigt framhäver studien tydliga begränsningar: DNS-fingeravtryck är mest stabila när en publik IP är knuten till en enskild användare, vilket är mer realistiskt i moderna IPv6-nätverk än i dagens IPv4-värld där många användare delar en adress via NAT. Frekventa byten av DNS-servrar eller publik Wi‑Fi försvagar också signalen. Viktigast av allt understryker arbetet en integritetsrisk som är svår för vanliga användare att uppfatta. Eftersom DNS-loggning i stor utsträckning är osynlig och passiv kan beteendespårning ske utan att cookies installeras eller påträngande skript används. Författarna publicerar sin datamängd och sina modeller öppet och argumenterar för att transparent forskning behövs så att samhället kan väga säkerhetsfördelarna med DNS-baserad fingeravtryckning mot dess potential för tyst övervakning och besluta vilka skydd och policyer som bör styra denna kraftfulla nya form av onlineidentifiering.
Citering: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Nyckelord: DNS-fingeravtryck, spårning av användare, internetsäkerhet, nätverkssäkerhet, maskininlärning