Clear Sky Science · sv
Ansiktssuperupplösning i verkliga förhållanden baserad på generativa adversariella och ansiktsanpassningsnätverk
Skarpare ansikten från suddiga foton
Alla som försökt zooma in på ett ansikte i en gammal övervakningsvideo eller en pytteliten bild från sociala medier känner igen frustrationen: ju mer du förstorar, desto mer förvandlas ansiktet till en blockig suddighet. Denna artikel presenterar en ny artificiell intelligensmetod som kan omvandla sådana lågkvalitativa verkliga ansiktsbilder till mycket klarare bilder, på ett sätt som bättre bevarar en persons identitet och uttryck. Det har uppenbara tillämpningar för övervakningskameror, fotoforensik och även vardagliga fotoförbättringsappar.
Varför suddiga ansikten är så svåra att åtgärda
Att få en liten, fuzzy ansiktsbild att se skarp ut handlar inte bara om att "lägga till pixlar." Traditionella metoder förlitade sig på handgjorda regler eller enkla mönster, och nyare djupinlärningstekniker lärde sig ofta från artificiellt degraderade bilder: ta ett rent högupplöst ansikte, sudda och krymp det, och lär sedan ett nätverk att vända processen. Problemet är att verkliga bilder—som från övervakningskameror eller komprimerad video—degraderas på röriga och oförutsägbara sätt. Sudd, brus och kompressionsartefakter matchar sällan de prydliga syntetiska exempel som används i träningen, så modeller som ser bra ut i labbet misslyckas ofta på verkligt material. Värre är att de kan producera ansikten som ser rimliga ut men inte längre liknar den ursprungliga personen.
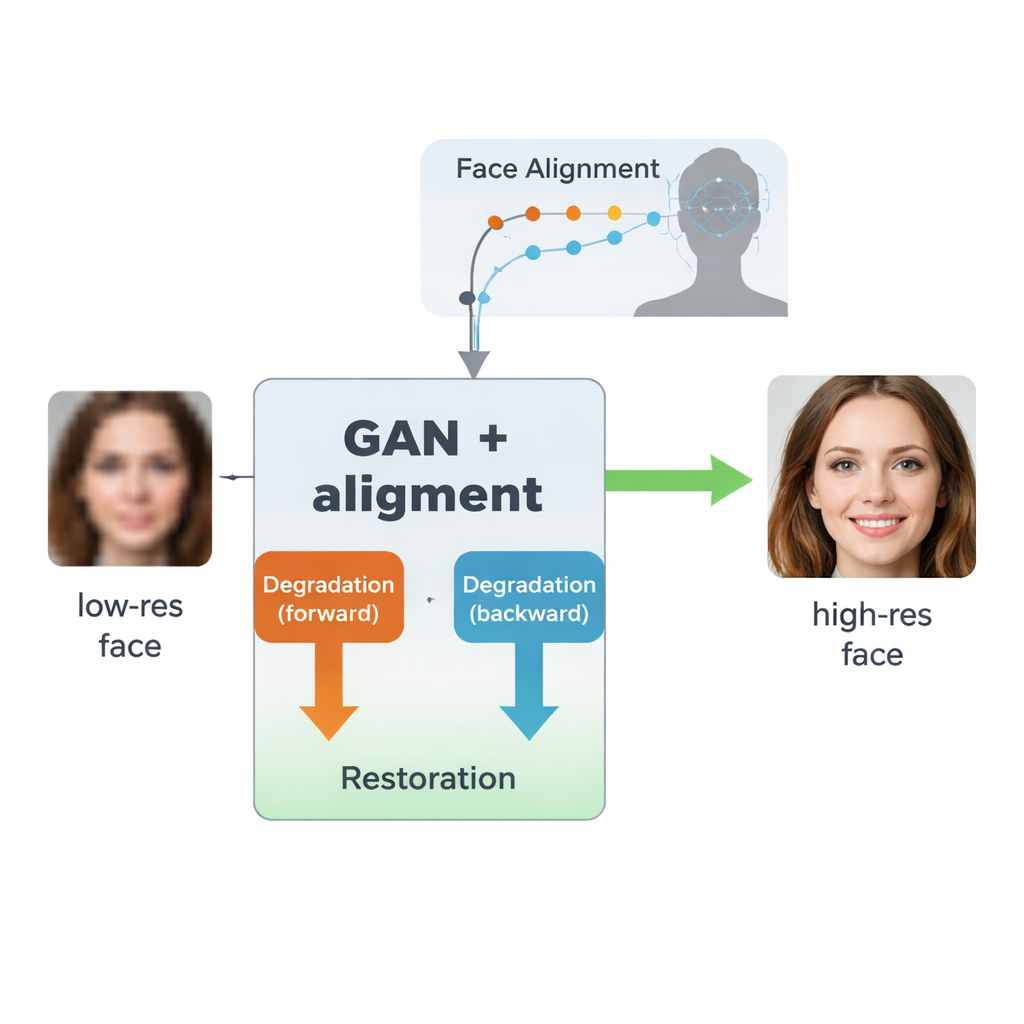
En tvåvägs lärandeslinga för bilder från verkliga förhållanden
Författarna bygger vidare på en typ av AI kallad generativt adversariellt nätverk (GAN), som lär sig skapa realistiska bilder genom att låta två neurala nätverk tävla mot varandra: ett genererar bilder, det andra bedömer hur verkliga de ser ut. Deras design, inspirerad av en tidigare modell kallad SCGAN, använder en "semi-cykel"-struktur med två kompletterande slingor. I framåtslingan degraderas verkliga högupplösta ansikten av en gren för att producera syntetiska lågupplösta versioner, som sedan återställs av en gemensam restaureringsgren. I bakåtslingan förbättras verkligt lågkvalitativa bilder av samma restaureringsgren och degraderas sedan igen av en annan gren för att likna verkliga lågupplösta bilder. Genom att tvinga fram konsekvens i båda riktningarna—degradera sedan återställa, eller återställa sedan degradera—lär sig systemet en realistisk modell av hur ansikten försämras i praktiken och hur man vänder den processen utan att någonsin behöva perfekt matchade par av låg- och högkvalitativa verkliga bilder.
Att lära nätverket hur ett ansikte verkligen ser ut
En viktig nyhet i detta arbete är att systemet lärs att inte bara göra bilder skarpare, utan också att respektera den underliggande strukturen hos ett mänskligt ansikte. För att uppnå detta integrerar författarna ett separat ansiktsanpassningsnätverk, ursprungligen utformat för att lokalisera landmärken som ögonvrår, nästipp och munkontur. Detta anpassningsnätverk förutser "heatmaps" som framhäver var varje landmärke bör vara. Under träningen jämför modellen heatmaps från den återställda bilden med de från ett verkligt högupplöst ansikte av samma person och bestraffar avvikelser. Avgörande är att detta använder en förtränad anpassningsmodell och inte kräver manuella landmärksetiketter för varje träningsbild. Resultatet är en form av geometrisk vägledning: förbättringsnätverket knuffas att placera ögon, näsa och mun på rätt positioner och med rätt former, istället för att enbart måla över suddet med generiska ansiktslika texturer.
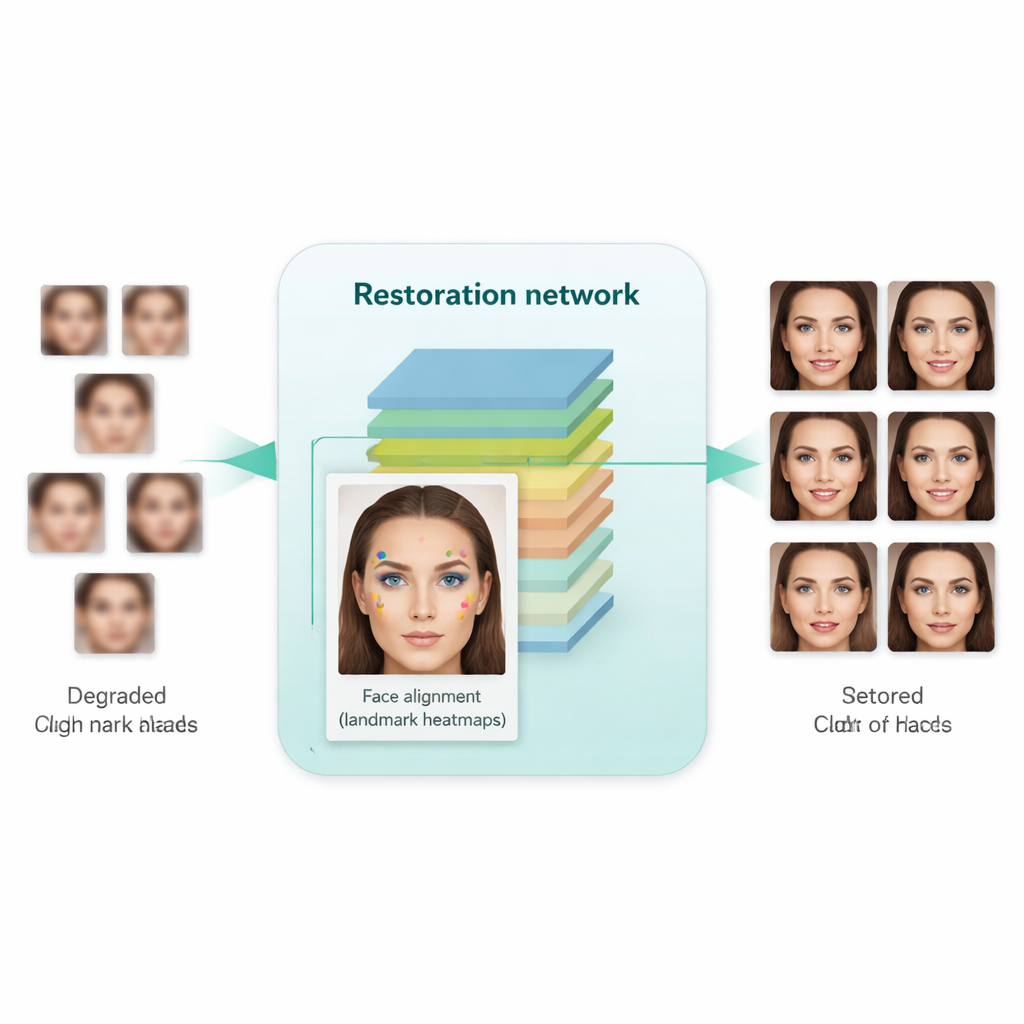
Hur bra fungerar det i praktiken?
Forskarna tränade sitt system på en stor samling högkvalitativa ansikten och en separat uppsättning verkligt lågkvalitativa ansikten från dataset i verkliga förhållanden. De testade det sedan både på syntetiska benchmarks (där rena referensbilder finns tillgängliga) och på verkliga bilder (där endast visuell realism och statistiska mått kan användas). Jämfört med tidigare metoder—inklusive välkända verktyg som Real-ESRGAN, GFPGAN och ursprungliga SCGAN—producerade den nya metoden bilder som inte bara såg mer naturliga och mindre förvrängda ut, utan som också ledde till bättre prestanda i praktiska uppgifter. När de förbättrade bilderna matades till standardansiktsdetektorer och en populär ansiktsigenkänningsmodell (FaceNet) förbättrades detektions- och verifieringsnoggrannheten märkbart, vilket indikerar att identitetsrelaterade detaljer bevarades bättre. Samtidigt antydde automatiska kvalitetsmått att de genererade ansiktena låg närmare fördelningen för verkliga högupplösta foton.
Vad detta betyder för vardagsanvändning
Enkelt uttryckt visar detta arbete att du kan få skarpare, mer tillförlitliga ansikten från dåliga bilder genom att kombinera två idéer: lär en realistisk modell av hur bilder förstörs i verkliga förhållanden, och använd information om ansiktslandmärken för att behålla ansiktets struktur. Istället för att enbart "gissa" ett snyggare ansikte styrs systemet att rekonstruera rätt person med klarare ögon, mun och hel form. Det gör metoden särskilt lovande för tillämpningar som säkerhet, forensik och arkivrestaurering, där både visuell klarhet och korrekt identitet är avgörande och där ursprungliga högkvalitativa versioner sällan finns tillgängliga.
Citering: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Nyckelord: ansiktssuperupplösning, generativa adversariella nätverk, ansiktsanpassning, ansiktsigenkänning, bildrestaurering