Clear Sky Science · sv
Bildbehandlingspipeline för AI-driven karakterisering av nanopartikel-megabibliotek
Varför små partiklar behöver hjälp av stora data
Modern materialvetenskap förlitar sig i allt större utsträckning på att framställa och testa enorma antal små partiklar för att hitta bättre katalysatorer, batterier och andra avancerade material. Nya metoder kan nu odla miljontals olika nanopartiklar på en enda chip, men att kontrollera kvaliteten på var och en genom ett mikroskop ger långt fler bilder än vad någon människa rimligen kan granska. Denna artikel beskriver hur forskare byggde en automatiserad bildbehandlings- och AI-pipeline som snabbt skiljer ”bra” från ”dåliga” nanopartikelbilder, vilket minskar beräkningskostnader och snabbar upp experiment samtidigt som besluten hålls mycket tillförlitliga.
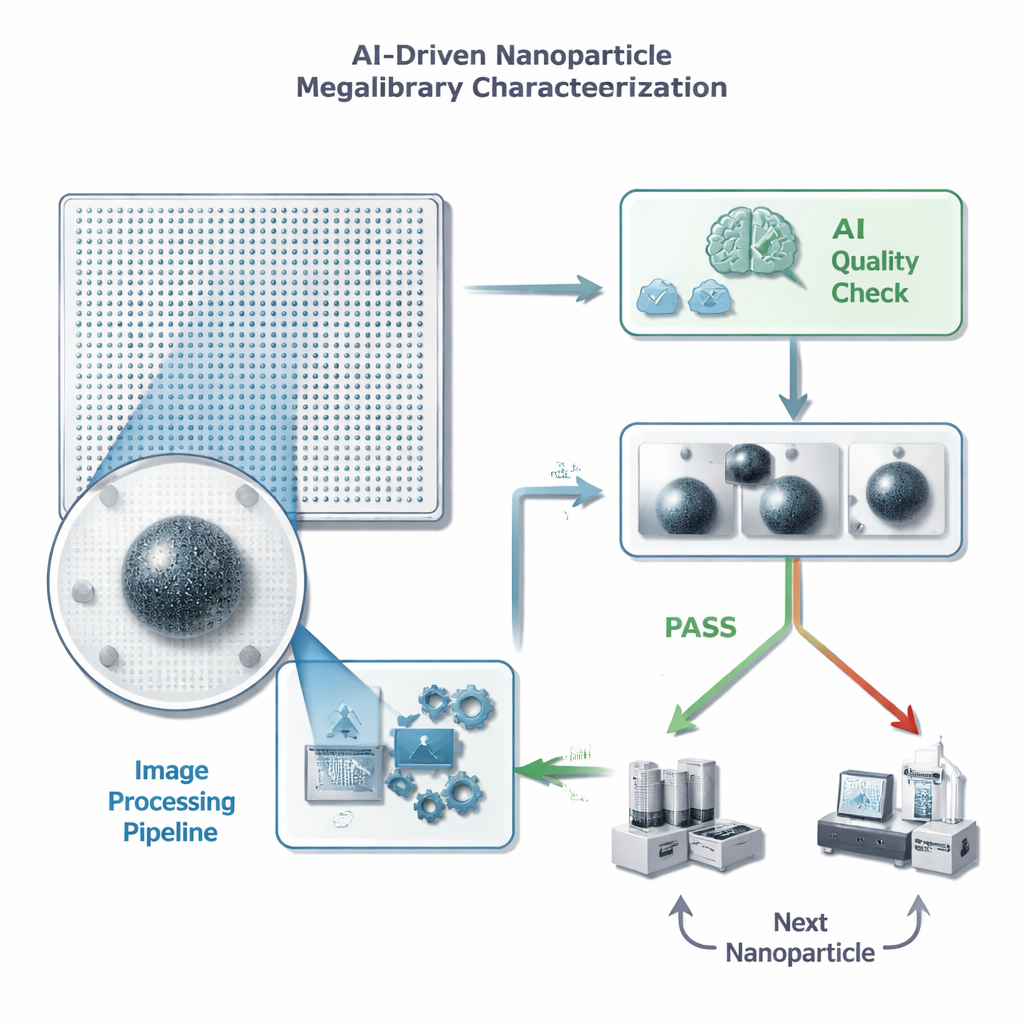
Från oändliga bilder till snabba beslut
Varje nanopartikel i ett ”megalibrary”-chip sitter på en känd position och kan avbildas med ett elektronmikroskop. Innan forskare satsar tid och kostsamma uppföljningsmätningar på enskilda partiklar behöver de en snabb kvalitetskontroll: finns det exakt en välfokuserad partikel i bilden, utan störande skräp eller artefakter? Författarna formulerar detta som en enkel godkänd/underkänd-uppgift för en maskininlärningsmodell, men med strikta begränsningar för hur lång tid modellen får lägga på varje bild—mindre än en halv sekund, eftersom ett enda chip kan innehålla miljontals partiklar. De betonar också att falska positiva är särskilt skadliga: om AI felaktigt godkänner en dålig bild slösas tid och lagringsutrymme på värdelösa detaljerade mätningar, medan enstaka missade bra partiklar är mindre skadliga för det övergripande arbetet.
Rensa bilden innan AI:n tittar
I stället för att stoppa råa, brusiga mikroskopbilder direkt i ett stort, komplext neuralt nätverk utformade teamet en specialanpassad bildbehandlingspipeline som först ”städar upp” bilderna. Pipen tar bort bakgrundsbrus, skärper kanter, beskär tätt kring partikeln och krymper sedan bilden till en mycket mindre storlek. Avgörande är att denna förbehandling gör svaga detaljer lättare att se och efterliknar utseendet hos en bild med högre förstoring utan att faktiskt avbilda provet igen. Resultatet är en kompakt, högkontrastbild som kan matas till ett relativt enkelt neuralt nätverk, vilket minskar både träningstid och lagringsbehov samtidigt som de detaljer som är viktiga för kvalitetsbedömningar bevaras.
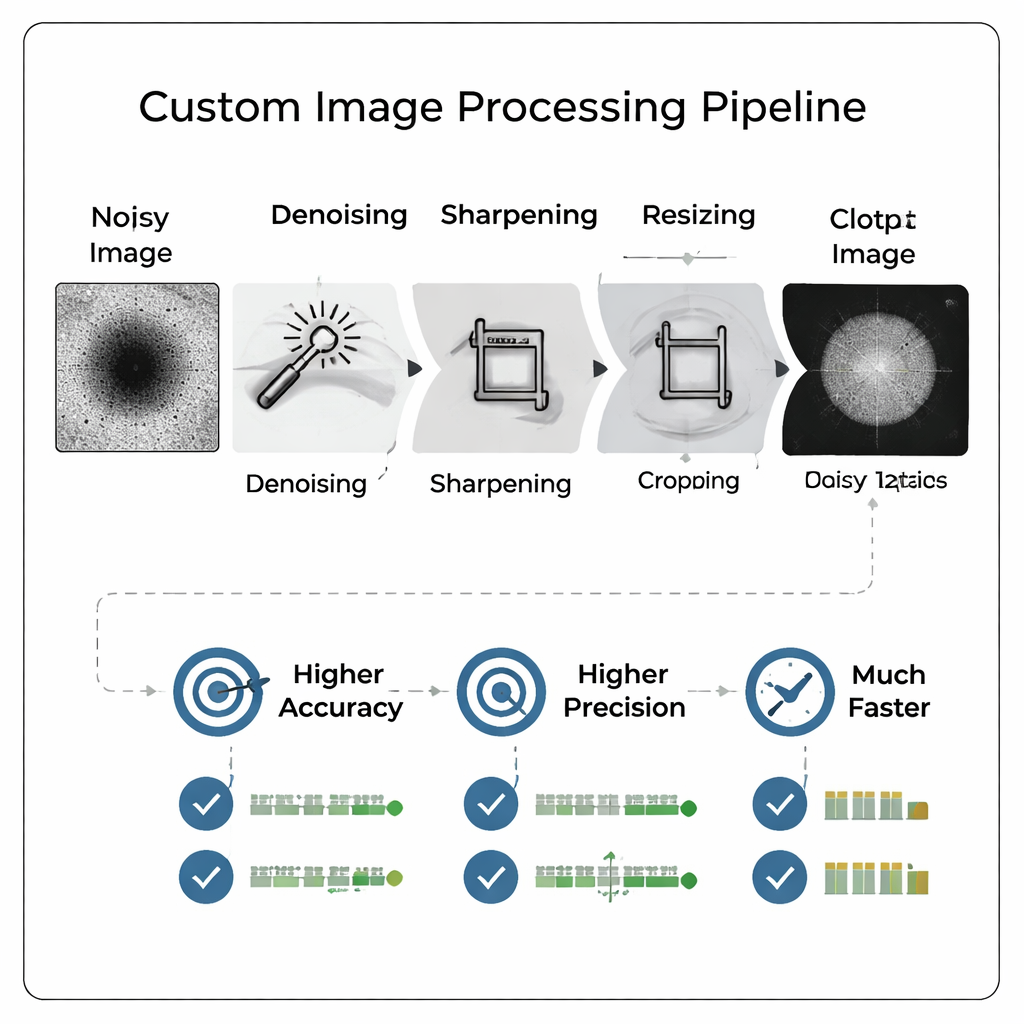
Smartare bilder slår större modeller
Forskarna jämförde rigoröst många pipeline-varianter och upplösningar och tränade slutligen 800 olika modeller för att se hur bildstorlek och bearbetning påverkar prestanda. De fann att noggrant bearbetade bilder i modest upplösning (till exempel 128×128 pixlar) gör att ett litet konvolutionellt neuralt nätverk överträffar en tidigare, mycket större modell som upptäckts av en automatiserad arkitektsökning och tränats på fulla 512×512-bilder. Noggrannheten förbättrades med över 13 procentenheter, medan recall—förmågan att korrekt fånga bra partiklar—ökade med mer än 18 procentenheter. Precision, den viktiga mätningen för att undvika slöseri med dåliga partiklar, nådde cirka 96 procent, och den kombinerade prestandamått som författarna föredrar förbättrades också.
Mer gjort med långt mindre data
Ett av de mest iögonfallande resultaten är att bearbetning spelar större roll än rå bildstorlek. När teamet jämförde modeller tränade på enkla ”endast nedskalade” bilder mot de som använde den fulla specialpipeline vann de bearbetade bilderna konsekvent—även när de krymptes till extremt små storlekar som 16×16 pixlar. Faktum är att den bästa modellen som använde bearbetade 16×16-bilder slog den bästa modellen som använde obearbetade 128×128-bilder i nästan alla mätvärden. Pipen hjälpte också mest vid lägre mikroskopförstoringar, där bilder normalt är svårare att tolka. Eftersom bilder med lägre förstoring är snabbare att få fram innebär detta att laboratorier kan skanna chip snabbare utan att kompromissa med beslutskvaliteten.
Snabbare beslut för självstyrande laboratorier
Genom att kombinera smart bildbehandling med en slank AI-modell minskade författarna träningstiderna från många timmar på en superdator till under en minut på en enda grafisk processor. När modellen är tränad kan systemet bearbeta och klassificera en ny bild på cirka 75 millisekunder, långt under målet på 500 millisekunder och mycket snabbare än en mänsklig granskare. I praktiska termer betyder detta snabb och pålitlig screening av nanopartikel-megabibliotek, vilket hjälper forskare att rikta dyra instrument mot de mest lovande kandidaterna. När laboratorier går mot mer automatiserade, ”självkörande” upptäcktsystem erbjuder tillvägagångssätt som detta—rengör först data, applicera sedan strömlinjeformad AI—ett kraftfullt sätt att förvandla överväldigande bildströmmar till handlingsbar vetenskaplig insikt.
Citering: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Nyckelord: nanopartiklar, bildbehandling, maskininlärning, materialupptäckt, elektronmikroskopi