Clear Sky Science · sv
Forskning om plug-and-play-moduler för förbättring av korrelationer i djup flermärkningsinlärning
Lära maskiner hantera för många etiketter
Nätbutiker, juridiska arkiv och medicinska databaser är beroende av programvara som snabbt kan märka varje nytt dokument med rätt etiketter. Moderna system ställs ofta inför tiotusentals eller till och med miljontals möjliga etiketter—från produktkategorier till medicinska ämnen—medan varje text bara behöver några få. Denna artikel introducerar ett nytt tillägg, kallat Label Correlation Enhancement Network (LCENet), som hjälper befintliga djupinlärningsmodeller att bättre utnyttja hur etiketter naturligt uppträder tillsammans i verkliga data, vilket leder till mer exakt och snabbare etikettering av text.
Varför märkning i webbskala är så svårt
Många verkliga tillämpningar faller inom vad forskare kallar extrem flermärknings-textklassificering: givet en kort beskrivning eller ett långt dokument måste systemet välja en liten delmängd relevanta etiketter ur ett enormt katalog. Exempel är att tilldela kategorier till produkter på en e-handelsplats, indexera biomedicinska artiklar med MeSH-termer, matcha annonser till webbsidor eller kartlägga juridiska texter till detaljerade lagkoder. Dessa situationer delar tre utmaningar: etikettlistan är extremt stor, de flesta etiketter är sällsynta, och varje given text använder bara några få etiketter. Traditionella tekniker delar ofta upp problemet i många små klassificerare eller komprimerar etiketter till lågdimensionella vektorer, men de förlitar sig ofta på enkla ordräkningar och kan inte fullt ut fånga betydelse eller relationer mellan etiketter.
Vad vanliga djupa modeller fortfarande missar
Moderna djupinlärningsmetoder, såsom konvolutionsnätverk, rekurrenta nätverk och Transformer-baserade modeller som BERT, har starkt förbättrat textförståelsen genom att lära rika semantiska representationer. Ändå gör nästan alla en avgörande förenkling i slutsteget: när texten väl kodats till en vektor förutsäger de varje etikett oberoende. I praktiken interagerar etiketter starkt. En medicinsk artikel märkt med ”diabetes” har större sannolikhet att även innefatta ”insulinresistens”, och en pryl märkt ”smartphone” är vanligtvis relaterad till ”elektronik” och ”kommunikationsenheter”. Att ignorera dessa mönster innebär att modeller inte kan använda högkonfidens-etiketter för att stödja svagare sådana, och de kan till och med ge kombinationer som inte är meningsfulla tillsammans.
En plug-in som lär sig etikettrelationer
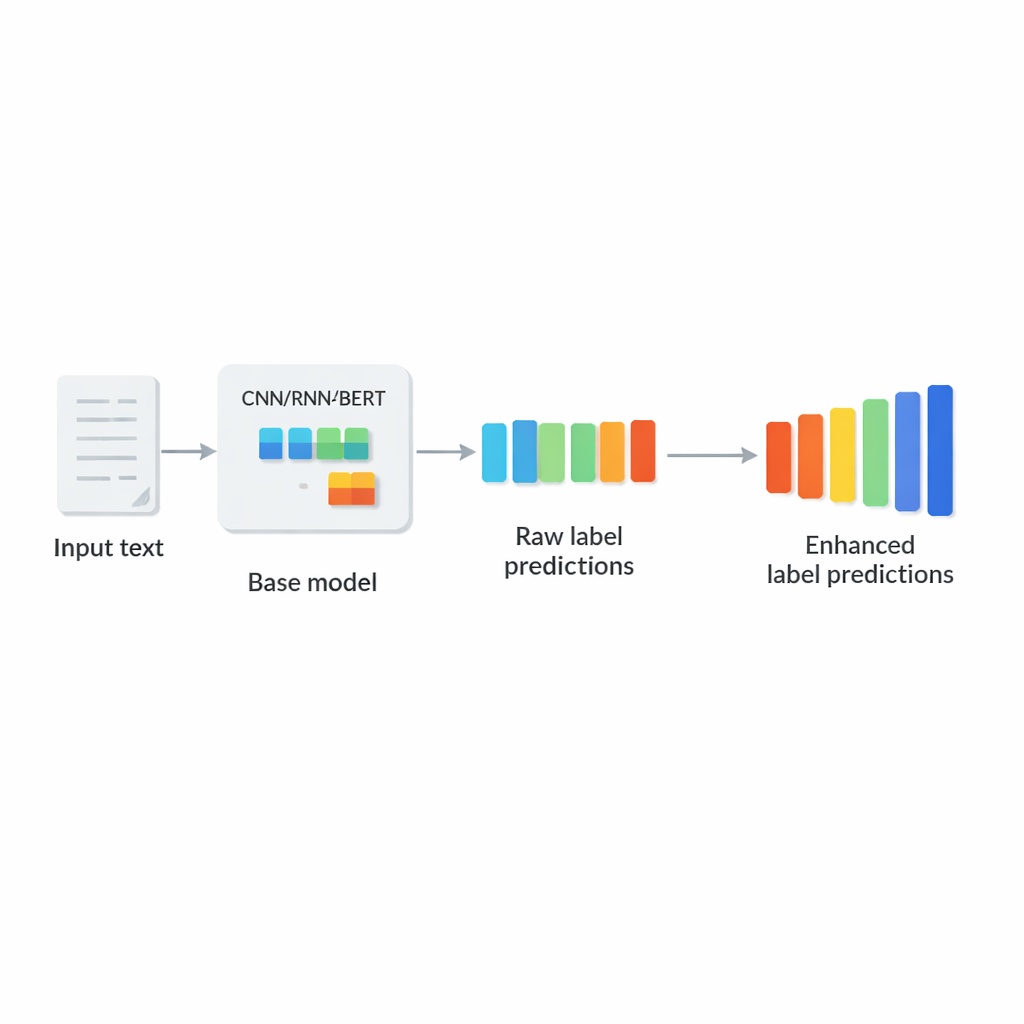
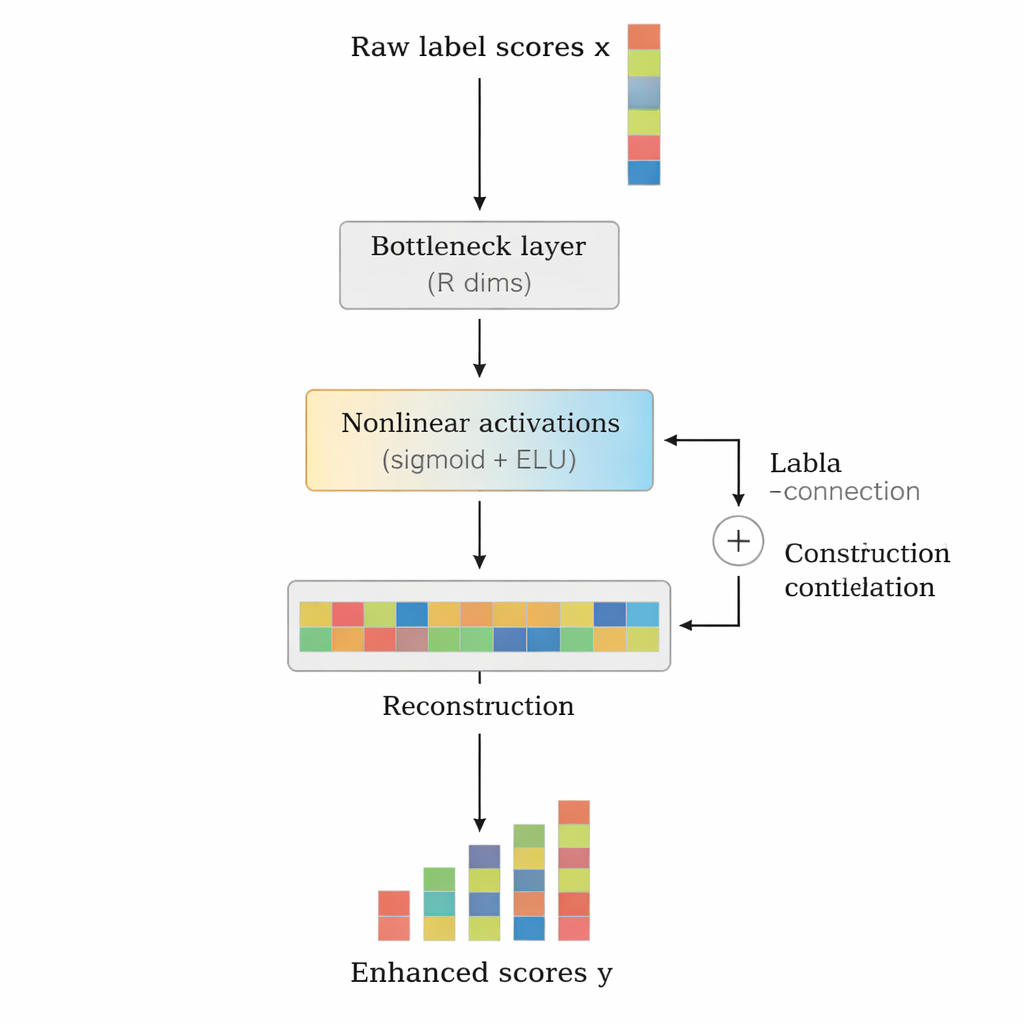
Författarna föreslår LCENet som en lätt, plug-and-play-modul som placeras efter vilken befintlig djup textklassificerare som helst. Istället för att ändra hur basmodellen läser text tar LCENet de råa etikettpoäng den producerar och för dem genom en kompakt ”flaskhals” som tvingar systemet att upptäcka en lågdimensionell representation där relaterade etiketter klustrar ihop sig. Icke-linjära aktiveringsfunktioner gör det möjligt för modulen att fånga komplexa, högre ordningens associationer, inte bara enkla parvisa länkar. En residual- eller skip-anslutning matar de ursprungliga poängen direkt till utgången tillsammans med de korrigerade poängen, vilket stabiliserar träningen och säkerställer att tillägget inte lätt kan göra saken sämre. Avgörande är att LCENet minskar antalet extra parametrar från något som skulle växa med kvadraten av antalet etiketter till en långt mer hanterbar linjär tillväxt, så det förblir genomförbart även för hundratusentals etiketter.
Visar fördelarna över modeller och datamängder
För att testa om LCENet verkligen är generell kopplade författarna den till fyra mycket olika djupa modeller, inklusive CNN-baserade och BERT-baserade arkitekturer, samt system särskilt designade för biomedicinska och extrem-etikettinställningar. De utvärderade dessa kombinationer på tre offentliga referensdatamängder: ett europeiskt juridiskt korpus (EUR-Lex), en Amazon-produktdatamängd (AmazonCat-13K) och en massiv Wikipedia-samling med över en halv miljon etiketter (Wiki-500K). Över alla modeller, datamängder och sex rankningsfokuserade mått förbättrade LCENet konsekvent prestandan, ibland ökade top-1-precisionen med mer än fem procentenheter på den största datamängden. Träningskurvor visade dessutom att LCENet ofta halverar antalet träningssteg som krävs för att nå en viss noggrannhet, eftersom den tillagda etikett-korrelationstrukturen ger tydligare inlärningssignaler från början.
Varför detta spelar roll för vardagliga system
För praktiker som redan förlitar sig på djupa modeller för att märka text erbjuder LCENet ett praktiskt sätt att förbättra noggrannhet och träningstid utan att omdesigna system eller samla nya typer av annoteringar. Det behandlar etikettutrymmet självt som en kunskapskälla, lär sig vilka taggar som tenderar att förekomma tillsammans eller utesluta varandra, och justerar sedan förutsägelserna därefter. Även om det utvecklats för text kan samma idé att förbättra förutsägelser med lärda relationer mellan utdata tillämpas på bilder, multimodala data och andra strukturerade prediktionsuppgifter. Enkelt uttryckt hjälper LCENet maskiner att ”komma ihåg” hur etiketter hänger ihop, så att de gissar mindre som oberoende kryssrutor och mer som en kunnig människa som förstår hur begrepp hör ihop.
Citering: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Nyckelord: extrem flermärknings-textklassificering, etikettkorrelation, djupinlärning, textklassificering, neuronätverk