Clear Sky Science · sv
DMSCA: dynamisk flerskalig kanal-rumslig uppmärksamhet för förbättrad funktionsrepresentation i konvolutionella neurala nätverk
Lära datorer att uppmärksamma bättre
Moderna bildigenkänningssystem kan upptäcka katter, trafikskyltar och tumörer i skanningar — men de vet inte alltid vad de ska fokusera på inne i en bild. Denna artikel presenterar ett nytt sätt att hjälpa systemen att koncentrera sig på de viktigaste delarna av en bild, vilket förbättrar noggrannheten och gör dem mer tillförlitliga i verklighetens stökiga förhållanden. Metoden, kallad Dynamic Multi-Scale Channel-Spatial Attention (DMSCA), kopplas in i befintliga konvolutionella neurala nätverk och hjälper dem att se både “vad” och “var” i en bild på ett mer intelligenta sätt.
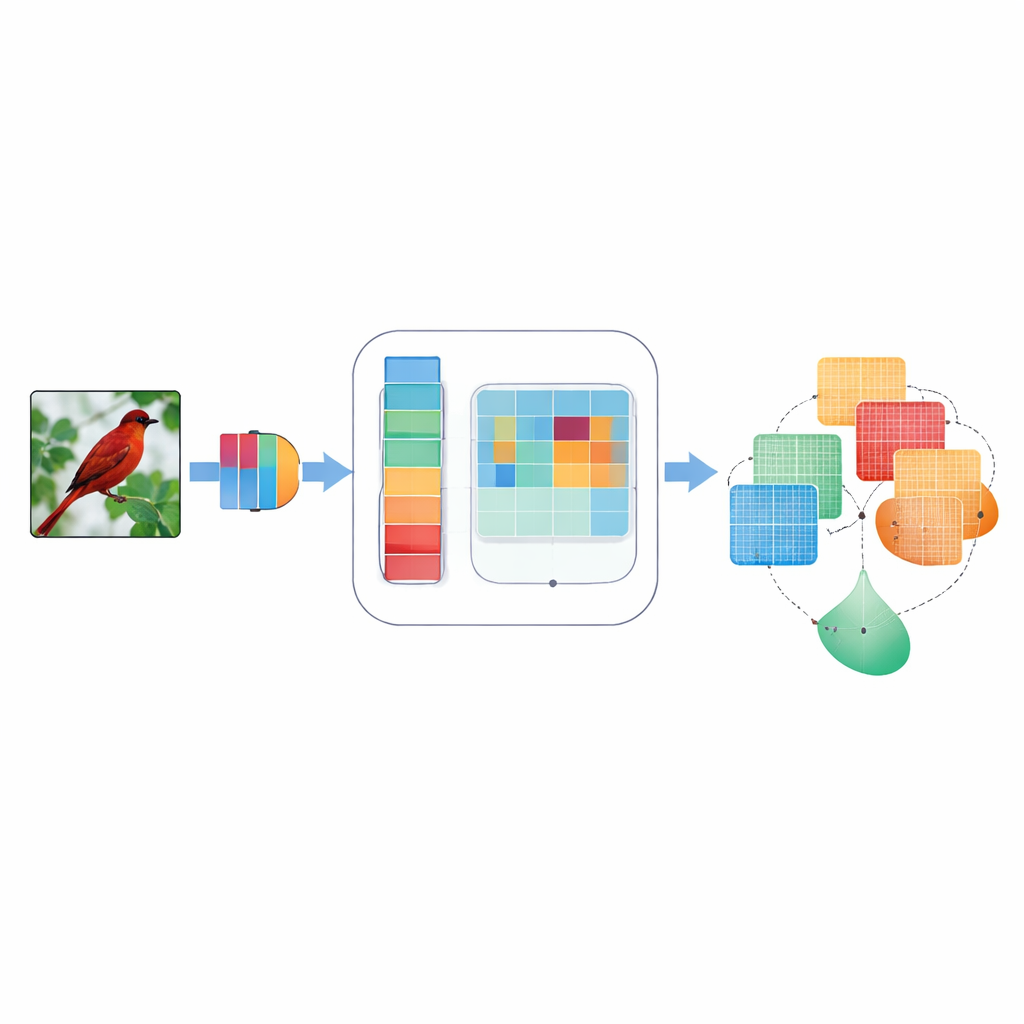
Varför fokus är viktigt för maskinseende
Konvolutionella neurala nätverk, arbetshästarna bakom många visionapplikationer, behandlar normalt varje internt signalvärde som lika viktigt. Det innebär att en svag kontur av en fågels vinge och en himmelsfläck kan få liknande uppmärksamhet, även om bara den ena hjälper till att identifiera arten. Tidigare ”uppmärksamhets”metoder försökte åtgärda detta genom att väga vissa interna signaler mer än andra — antingen över kanal-liknande färger eller över bildens tvådimensionella layout. Men dessa metoder använde ofta fasta, handdesignade regler, tittade bara på en detaljnivå i taget eller kombinerade information på ett stelt sätt som inte kunde anpassa sig till olika bilder. Som ett resultat missade de ibland fina detaljer, ignorerade riktningar som ”horisontell kontra vertikal” eller hade svårigheter när bilder var brusiga eller suddiga.
Ett smartare uppmärksamhetstillägg
DMSCA är utformat som en liten, ansluten modul som kan införas i välkända neurala nätverk som ResNet utan att ändra deras övergripande struktur. Inuti koordinerar den sex tätt länkade delar som arbetar tillsammans snarare än isolerat. En del summerar hela bilden för att fånga vad som händer globalt, medan en annan lär sig hur starkt varje intern kanal ska väga, med en styrbar ”temperatur” som kan göra besluten skarpare eller mjukare efter behov. På det rumsliga planet använder DMSCA flera fönsterstorlekar samtidigt för att fånga både små texturer och större former, och den uppmärksammar uttryckligen horisontella och vertikala riktningar så att långa kanter eller ränder inte suddas ut. Slutligen, istället för att bara addera dessa signaler, lär sig modulen pixel för pixel hur mycket den ska lita på ”vad”-informationen från kanaler jämfört med ”var”-informationen från rummet.
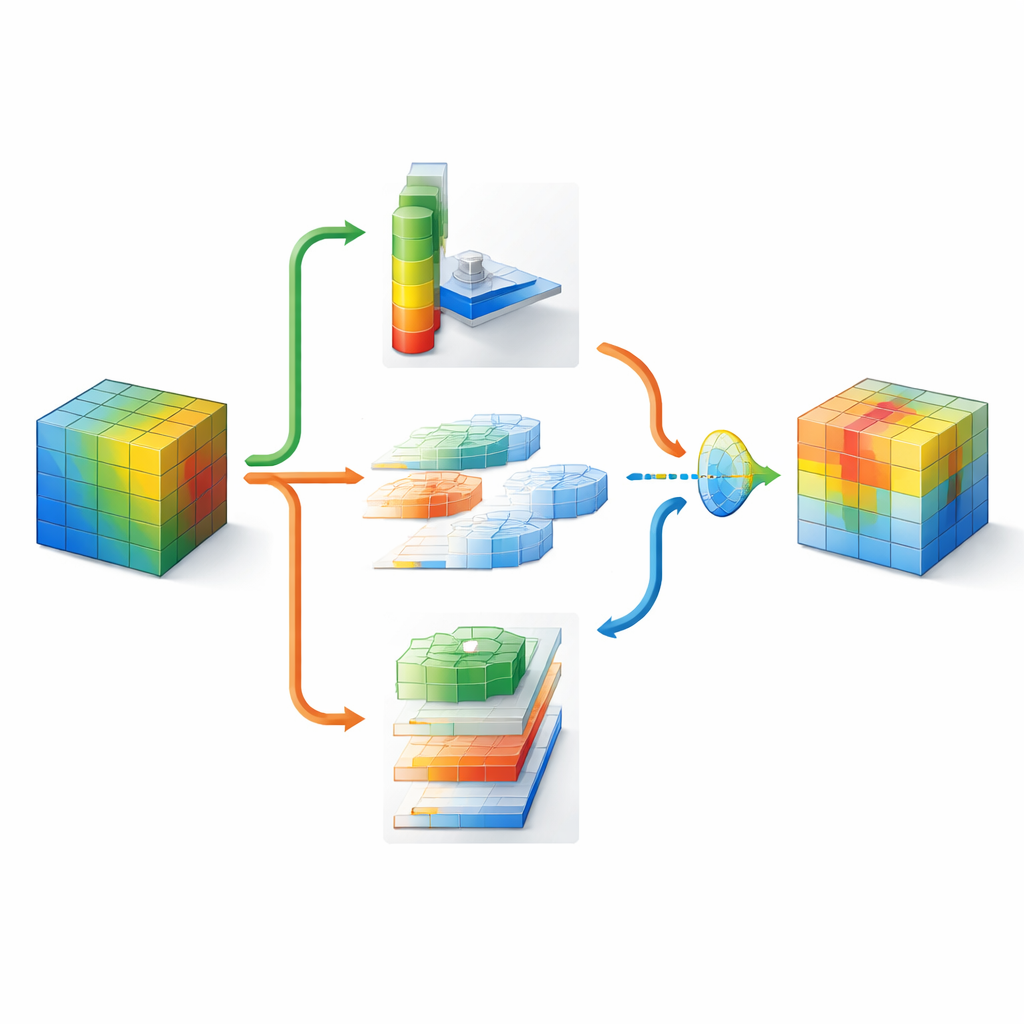
Se bilder i många skalor och riktningar
För att förstå var man ska titta i en bild komprimerar DMSCA först de många interna kanalerna till en kompakt tvålagerskarta som lyfter fram både bakgrundstrender och framträdande drag. Denna karta passerar sedan genom flera parallella filter i olika storlekar. Små filter ser finfördelade detaljer som päls eller fjädrar, medan större fångar former som hela huvuden eller kroppar. Parallellt skannar en riktad enhet längs rader och kolumner separat och bevarar den exakta positionen för viktiga strukturer. Dessa horisontella och vertikala vyer får sedan interagera, så att en stark vertikal signal till exempel kan förstärka rätt horisontella lägen. Resultatet är en rik uppmärksamhetskarta som talar om för nätverket inte bara att något är viktigt, utan var det är och i vilken skala.
Låta nätverket avgöra vad som betyder mest
Eftersom olika delar av en bild kan kräva olika strategier påtvingar inte DMSCA ett fast recept för att kombinera kanal- och ruminformation. Istället bygger den en liten ”grind” som undersöker båda och bestämmer — oberoende för varje pixel — hur stor vikt varje typ ska få. I en rörig bakgrund kan systemet förlita sig mer på vilka kanaler som sticker ut, medan det vid skarpa objektkanter kan betona rumsliga ledtrådar. Ett slutligt adaptivt aktiveringssteg fungerar sedan som en inlärd dimmer, som förstärker verkligt informativa områden och dämpar kvarvarande brus. Denna flerstegprocess hjälper till att styra nätverkets uppmärksamhet mot koherenta, objektrelaterade regioner, vilket bekräftas av visuella värmekartor och kvantitativa mått på hur väl de markerade områdena stämmer överens med sanningens objekt.
Skarpare seende med måttlig extra insats
Författarna testade DMSCA på flera standardmätningar, från små samlingar av små bilder till den storskaliga ImageNet-databasen. När den lades till populära ResNet-modeller förbättrade DMSCA konsekvent klassificeringsnoggrannheten — med upp till cirka 2 procentenheter på små dataset och 1,5 procentenheter på ImageNet — och överträffade en rad befintliga uppmärksamhetsmetoder. Den gjorde också modeller mer robusta mot vanliga bildnedsättningar som brus, suddighet och kraftig kompression, och förbättrade prestanda på relaterade uppgifter såsom objektdetektion och scenklassificering. Dessa förbättringar kom med endast en måttlig ökning i beräkning och minnesåtgång. I enkla termer ger DMSCA konvolutionella nätverk ett mer flexibelt och kontextmedvetet sätt att avgöra vad de ska titta på och vad de ska ignorera, vilket för maskinseendet ett steg närmare människans selektiva fokus.
Citering: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Nyckelord: uppmärksamhetsmekanismer, bildigenkänning, konvolutionella neurala nätverk, funktionsrepresentation, robust datorseende