Clear Sky Science · sv
Förbättrad korsmodal återhämtning via optimering av etikettgraf och hybrida förlustfunktioner
Söka smartare över bilder och ord
Varje dag bläddrar vi genom oceaner av bilder, videor och text. Att hitta precis det vi vill ha — till exempel alla bilder som stämmer med en kort bildtext — beror på hur väl datorer kan koppla ihop bilder med språk. Denna artikel utforskar ett nytt sätt att göra den kopplingen mer träffsäker, särskilt i röriga, verkliga scener där många idéer och objekt dyker upp samtidigt. Resultatet är smartare sökverktyg som bättre ”förstår” vad vi menar, inte bara vad vi skriver.
Varför flera betydelser i en bild spelar roll
En enda bild visar sällan bara en sak. Ett foto av en val som hoppar ur vattnet kan samtidigt involvera havet, himlen, vågor, vind och djurliv. När vi taggar en sådan bild fäster vi ofta flera etiketter som är relaterade på subtila sätt. Befintliga söksystem behandlar vanligtvis dessa etiketter som om de vore oberoende kryssrutor. Den förenklingen slösar bort användbara ledtrådar: om ”val” ofta förekommer med ”hav”, borde närvaron av den ena öka sannolikheten för den andra. Detta arbete fokuserar på att fånga de dolda banden mellan etiketter så att en sökning efter en idé ändå kan hitta bilder och texter som uttrycker nära relaterade begrepp.

Bygga ett nätverk av sammanlänkade etiketter
Författarna introducerar en teknik kallad Two-Layer Graph Convolutional Network, eller L2-GCN, för att modellera hur etiketter relaterar till varandra. Enkelt uttryckt behandlas varje etikett (som ”himmel” eller ”val”) som en punkt i ett nätverk, och linjer mellan punkter speglar hur ofta dessa etiketter förekommer tillsammans. Metoden låter upprepade gånger varje etikett ”lyssna” på sina grannar, blanda information från relaterade etiketter samtidigt som etikettens egen identitet bevaras. Efter denna process får systemet rikare etikettbeskrivningar som bättre fångar hur verkliga scener är strukturerade, från parallella idéer (”hav” och ”strand”) till mer hierarkiska relationer (”djur” och ”val”).
Lära bilder och text att dela ett gemensamt rum
Etiketter är förstås bara halva historien; systemet måste också lära sig från bilderna och texterna själva. Ramverket använder etablerade verktyg för att omvandla råa pixlar och ord till numeriska egenskaper, för att sedan föra båda datatyperna in i ett delat utrymme där deras betydelser kan jämföras direkt. En adversariell modul — löst inspirerad av dynamiken i generativa adversariala nätverk — motverkar att modellen hänger fast vid särdrag hos enbart bilder eller enbart text. Det hjälper det gemensamma rummet att fokusera på innehåll snarare än format, så att en bild av en livlig gata och en kort bildtext som beskriver den hamnar nära varandra i denna gemensamma betydelsekarta.
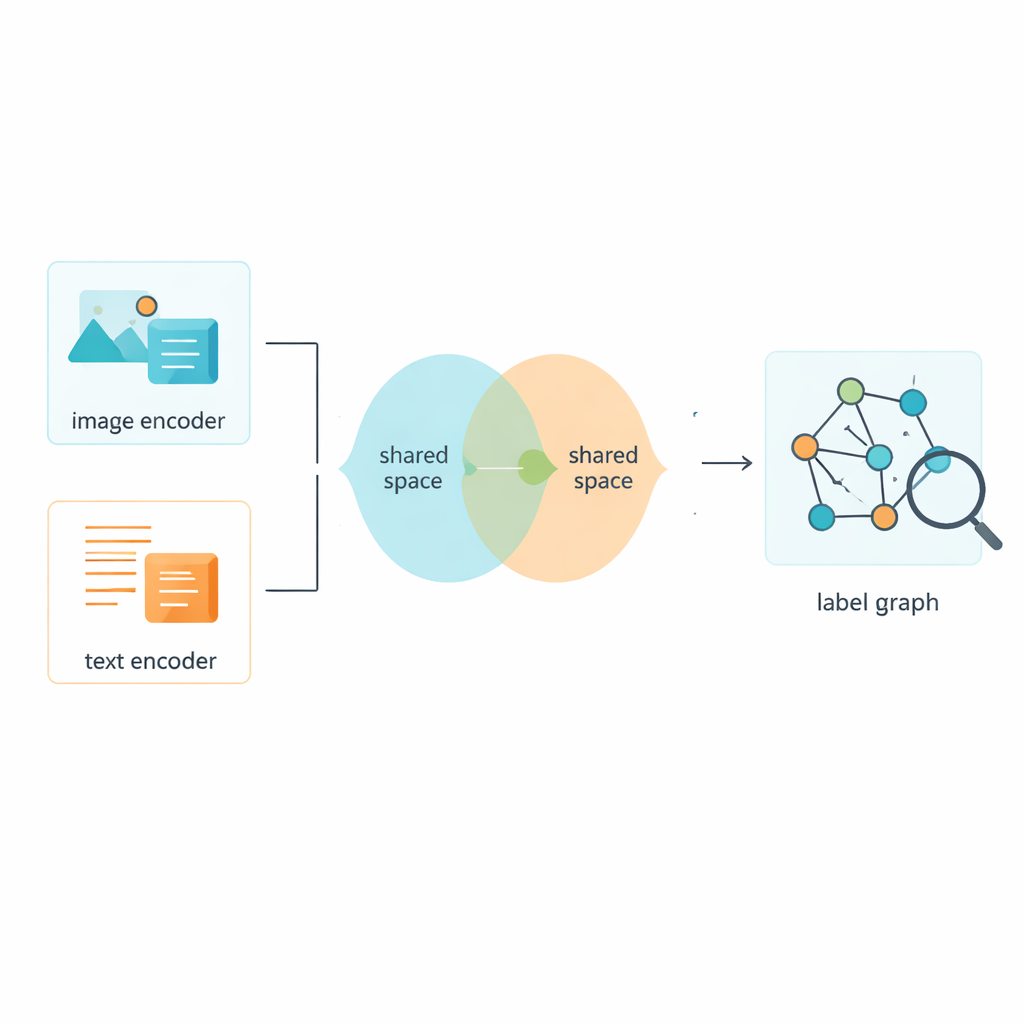
En hybrid träningsstrategi för skarpare distinktioner
Att träna ett sådant system kräver mer än en enda inlärningsregel. Författarna designar en kombinerad förlustfunktion, kallad Circle-Soft, som blandar två kompletterande idéer. Den ena delen uppmuntrar exempel från samma kategori att klustra tätt tillsammans samtidigt som olika kategorier pressas isär på ett flexibelt, adaptivt sätt. Den andra delen fokuserar på hur väl bilder och texter som beskriver samma scen överensstämmer över formatgränsen. En justerbar vikt balanserar dessa två mål så modellen inte överanpassar sig till vare sig snäva kategorigränser eller enbart korsmodal justering. Ytterligare klassificerings- och adversariella förluster uppmuntrar vidare konsistens mellan de förfinade etiketterna och de delade bild–text-egenskaperna.
Hur mycket bättre blir sökningen?
För att avgöra om dessa idéer leder till bättre sökresultat testade författarna sin metod på tre populära samlingar av verkliga bild–text-par: MIRFlickr, NUS-WIDE och MS-COCO. Dessa datamängder innehåller från tiotusentals till hundratusentals foton med tillhörande taggar eller bildtexter, och täcker vardagliga scener från stadsgator till djurliv. Över alla tre benchmarks presterade det nya tillvägagångssättet konsekvent bättre än en rad konkurrerande metoder, inklusive andra avancerade system som redan använder grafbaserad etikettmodellering. Vinsterna — omkring en halv till en hel procentenhet i en strikt återhämtningspoäng — kan låta blygsamma, men i väletablerade benchmarks signalerar även små förbättringar en mer precis förståelse av innehåll. I praktiska termer innebär det att när en användare anger en kort textfråga eller skickar en bild är systemet mer sannolikt att visa de mest relevanta korsmodala matchningarna högst upp i resultatlistan.
Vad det innebär för vardagsanvändare
För icke-specialister är huvudbudskapet att smartare hantering av etiketter och träningsregler kan märkbart förbättra hur maskiner kopplar bilder och ord. Genom att behandla etiketter som ett sammanlänkat nät snarare än isolerade taggar, och genom att noggrant forma hur visuella och textuella information möts i ett delat utrymme, gör detta ramverk korsmodal sökning mer pålitlig i komplexa, mångämnesrika scener. Med tiden kan tekniker som denna driva mer intuitiva fotobibliotek, medieplattformar och intelligenta assistenter som hittar vad vi menar — även när våra ord inte perfekt matchar bilderna vi har i åtanke.
Citering: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Nyckelord: bild-text-sökning, multimodal sökning, grafneuronala nätverk, semantiska etiketter, maskininlärning