Clear Sky Science · sv
En DNABERT-baserad djupinlärningsram för att förutsäga bindningsställen för transkriptionsfaktorer
Varför det spelar roll att förutsäga DNA:s kontrollknappar
Varje cell i din kropp bär i huvudsak samma DNA, ändå beter sig nervceller, leverceller och immunceller mycket olika. En anledning är att särskilda proteiner kallade transkriptionsfaktorer fungerar som molekylära strömbrytare och slår gener på eller av genom att fästa vid korta DNA-sekvenser som kallas bindningsställen. Att experimentellt hitta alla dessa fästpunkter över hela genomet är tidsödande och kostsamt. Denna studie presenterar TFBS-Finder, en ny artificiell intelligensmodell som kan läsa råa DNA-bokstäver och mer exakt förutsäga var transkriptionsfaktorer binder, vilket potentiellt kan påskynda forskning om genreglering och sjukdom.
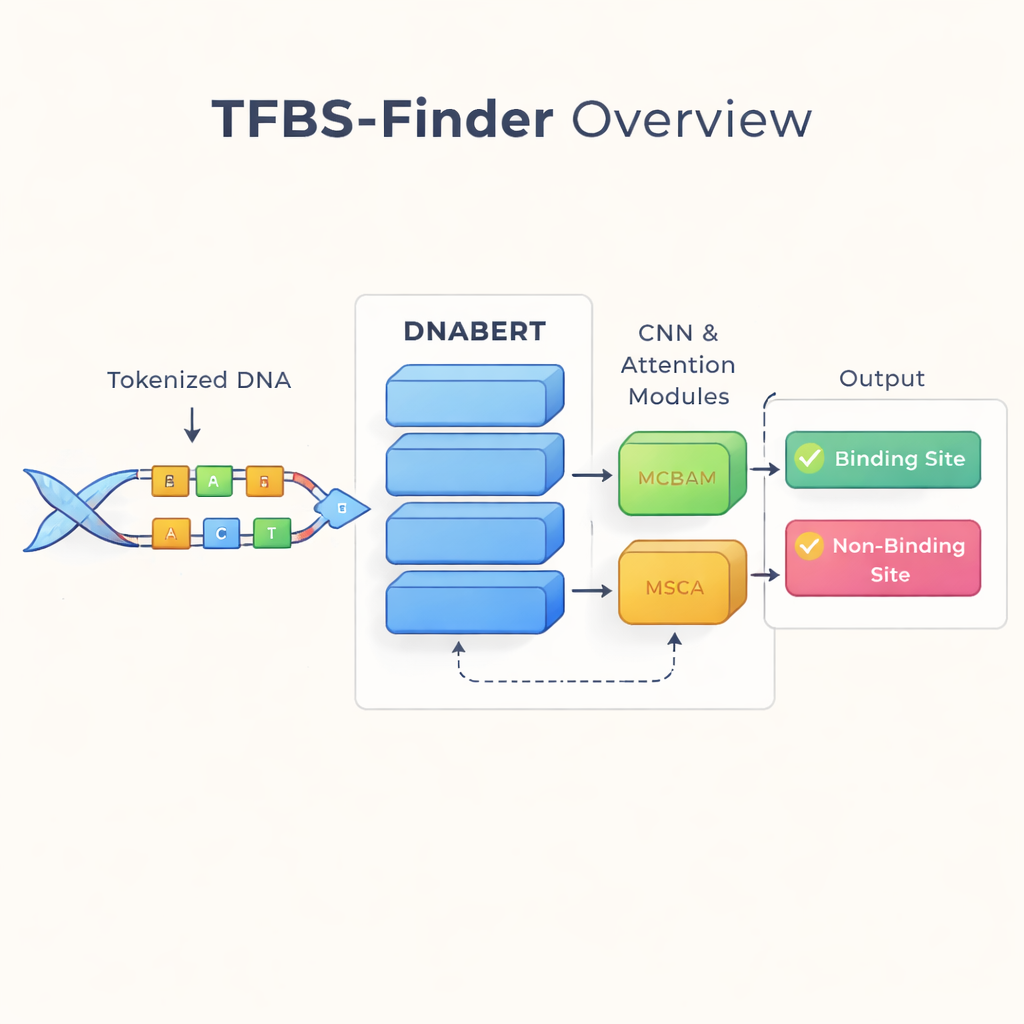
Läsa DNA som ett språk
Författarna bygger vidare på en idé som förändrat språkteknologin: behandla DNA som om det vore text. De använder DNABERT, en version av BERT-språkmodellen som tränats om på mänskligt DNA i stället för ord. DNABERT tittar inte bara på enskilda bokstäver utan delar upp DNA i överlappande korta "ord" om fem bokstäver och lär sig hur dessa delar tenderar att förekomma tillsammans. Detta låter modellen fånga långräckviddskontext, till exempel hur mönster i ena änden av en sekvens relaterar till mönster långt bort, på samma sätt som att förstå innebörden i en mening snarare än isolerade ord.
Hitta lokala mönster med fokuserad uppmärksamhet
Medan DNABERT är bra på att greppa global kontext, beror transkriptionsfaktorers bindning ofta på mycket korta, precisa motiv — lokala mönster i DNA. TFBS-Finder lägger därför till flera extra komponenter ovanpå DNABERT. Ett konvolutionellt neuralt nätverk (CNN) genomsöker sekvensinbäddningarna för att framhäva återkommande lokala former, på samma sätt som bildprogramvara upptäcker kanter och hörn. Två uppmärksamhetsmoduler, kallade MCBAM och MSCA, fungerar sedan som justerbara strålkastare som stärker de mest informativa dragen och nedtonar brus. Tillsammans balanserar dessa block helhetskontext med finkorniga detaljer för att avgöra om ett DNA-segment innehåller ett verkligt bindningsställe.
Bevisa att varje del verkligen hjälper
För att testa om alla dessa komponenter är nödvändiga genomförde teamet omfattande så kallade ablationsexperiment, där de systematiskt tog bort eller omarrangerade moduler och tränade om systemet på 165 benchmarksatser som täcker 29 transkriptionsfaktorer över 32 celltyper. Med hjälp av standardmått för förutsägelsekvalitet kom den fullständiga TFBS-Finder-modellen konsekvent ut i topp. Enklare versioner som bara förlitade sig på DNABERT, eller som saknade en av uppmärksamhetsmodulerna, förlorade tydligt i noggrannhet. Statistiska tester bekräftade att dessa prestandafall inte berodde på slump, vilket visar att kombinationen av global sekvensförståelse och noggrant utformad uppmärksamhet på lokala mönster är avgörande.
Fungerar över celltyper och slår äldre verktyg
En viktig fråga är om en modell som tränats i ett biologiskt sammanhang kan generalisera till ett annat. Författarna fokuserade på en välstuderad transkriptionsfaktor kallad CTCF och tränade TFBS-Finder på data från en cellinje för att sedan testa den på andra. I alla kombinationer nådde modellen höga poäng, vilket tyder på att den fångar kärnegenskaper i CTCF-bindning som delas mellan vävnader. I jämförelse med nio ledande metoder, inklusive tidigare djupinlärnings- och BERT-baserade modeller, visade TFBS-Finder högre genomsnittlig noggrannhet och gav mer tillförlitliga rangordningar av bindningsställen. Den körde också något snabbare och använde mindre minne än den mest liknande tidigare modellen, vilket indikerar att bättre prestanda inte krävde tyngre beräkning.
Se vad modellen har lärt sig
Komplexa AI-system kritiseras ofta som "svarta lådor." Här försökte forskarna öppna den lådan genom att visualisera vilka DNA-positioner som mest påverkade TFBS-Finders beslut. För två transkriptionsfaktorer med välkända bindningsmotiv, CEBPB och GATA3, genererade de betydelsepoäng längs sekvensen och klustrade de starkaste signalerna till konsensusmönster. Dessa återvunna motiv matchade väl referensmotiv från etablerade databaser, och de förutspådda bindningsregionerna överlappade med oberoende upptäckta motivinstanser. Detta tyder på att TFBS-Finder inte bara memorerar exempel utan har lärt sig biologiskt meningsfulla regler för hur transkriptionsfaktorer känner igen DNA.
Vad detta betyder för genetik och medicin
TFBS-Finder erbjuder ett mer exakt och tolkbart sätt att kartlägga de kontrollknappar som finns inbäddade i vårt DNA. Genom att peka ut var transkriptionsfaktorer sannolikt binder kan det hjälpa forskare att kartlägga genreglerande nätverk, prioritera vilka genetiska varianter som kan störa viktiga kontrollställen och utforma mer riktade experiment. Även om det nuvarande arbetet använder omkastade sekvenser som artificiella negativa exempel och fokuserar enbart på DNA-bokstäver planerar författarna att lägga till strukturell information om DNA-form och utforska mer realistiska bakgrundssekvenser. När dessa modeller förbättras kan de bli kraftfulla verktyg för att förstå hur förändringar i icke-kodande DNA påverkar utveckling, evolution och sjukdomsrisk.
Citering: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
Nyckelord: bindningsställen för transkriptionsfaktorer, djupinlärning, DNABERT, genreglering, genomik