Clear Sky Science · sv
Förbättrad medicinsk kunskapsrepresentation i stora språkmodeller genom optimering av kliniska token
Varför smartare medicinsk läsning spelar roll
Bakom varje medicinsk AI-assistent finns en enkel men avgörande förmåga: hur den delar upp text i bitar den kan tolka. När denna ”hackning” går fel — särskilt för komplexa kinesiska medicinska termer — kan AI missa viktiga poänger i läkaranteckningar eller patientfrågor. Denna studie visar hur en liten men riktad förändring i det första steget kan göra stora språkmodeller bättre på att läsa, resonera kring och besvara frågor om kinesiska medicinska data, utan att bygga ett helt nytt system från grunden.
Att dela text i rätt bitar
Moderna språkmodeller läser inte tecken eller ord direkt; de konverterar först text till korta enheter kallade tokens. För engelska fungerar detta ganska bra eftersom mellanslag redan markerar ordgränser. Kinesiska är knepigare: det finns inga mellanslag och många medicinska uttryck är långa, specialiserade fraser. Standard-tokenizers, som främst är designade för engelska, tenderar att skära dessa fraser i många godtyckliga fragment. När en modell ser ett sjukdomsnamn eller ett laboratorietest uppdelat i flera åtskilda bitar blir det svårare att lära sig vad termen egentligen betyder, och modellens svar på medicinska frågor kan bli vagare eller felaktiga.
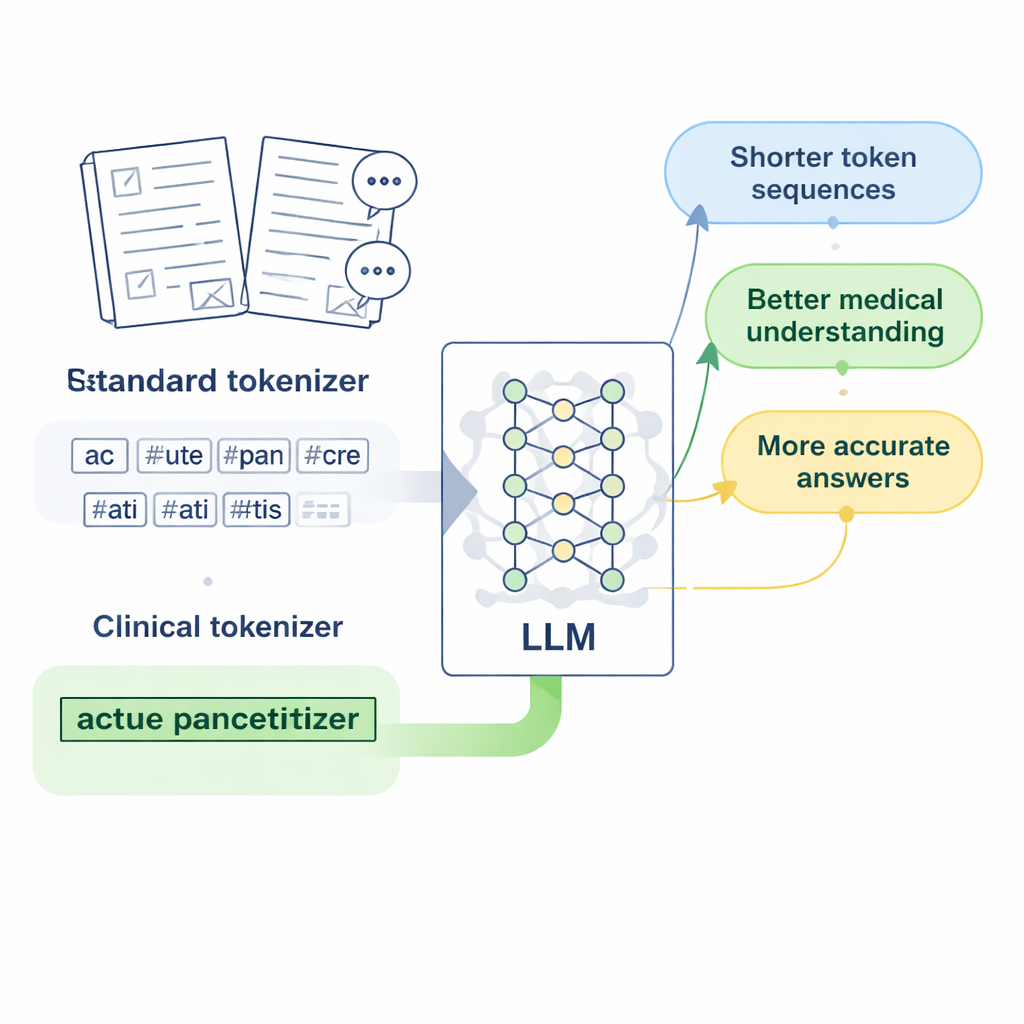
Att designa ”kliniska tokens” för kinesisk medicin
Forskarna fokuserar på LLaMA2, en populär öppen källkods-stor språkmodell, och frågar: vad händer om vi helt enkelt lär dess tokenizer ett rikare medicinskt ordförråd? De samlar stora mängder kinesisk medicinsk text, inklusive noggrant redigerade databaser för traditionell kinesisk medicin, tusentals kliniska journaler och doktor–patient-fråge-och-svar-par. Genom att använda en byte-nivåversion av Byte Pair Encoding-algoritmen, implementerad med verktyget SentencePiece, tränar de en ny tokenizer som lär sig behålla vanliga medicinska uttryck som enhetliga token. Dessa nya enheter, som författarna kallar ”kliniska tokens”, slås sedan ihop med LLaMA2:s ursprungliga vokabulär och utökar den för att bättre täcka kinesiskt medicinskt språk utan att kassera vad modellen redan kan.
Från bättre tokens till en bättre medicinsk modell
Att lägga till nya tokens är bara första steget; modellen måste lära sig användbara representationer för dem. Teamet justerar LLaMA2:s interna inbäddningslager så att det kan lagra vektorer för den utökade vokabulären och testar två sätt att initiera dessa nya vektorer. En metod tar medelvärdet av vektorerna för äldre delbitar av varje ord, medan den andra använder noggrant skalade slumpvärden. Motintuitivt presterar den slumpmässiga metoden bättre, sannolikt eftersom den undviker att låsa modellen vid en dålig initial gissning om varje terms betydelse. Författarna fortsätter sedan träningen av modellen på medicinsk text och finjusterar den på instruktionsliknande medicinska Q&A med en resurseffektiv metod kallad LoRA, vilket ger en specialiserad version de kallar Medical-LLaMA.
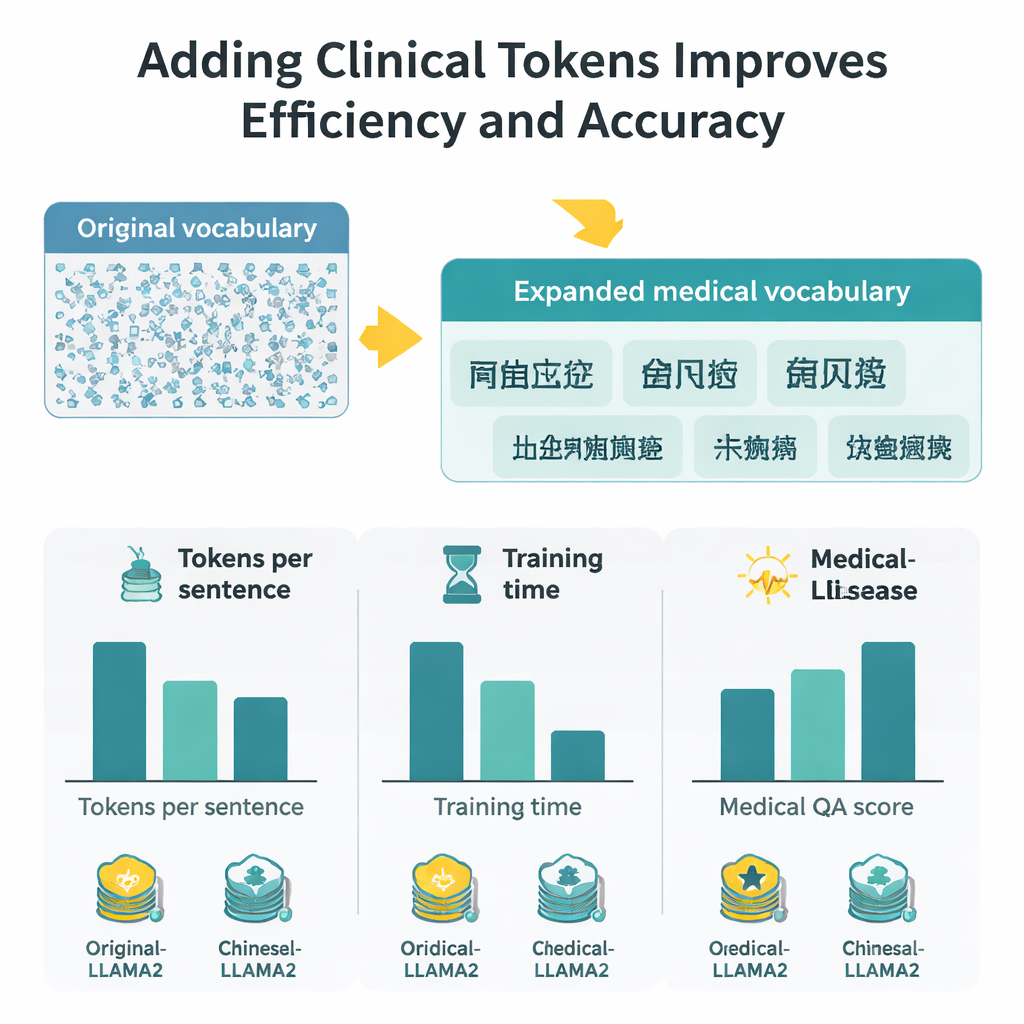
Mätbara vinster i hastighet, kontext och noggrannhet
Med den utökade vokabulären kräver varje kinesiskt tecken nu ungefär hälften så många tokens som tidigare, vilket innebär att modellen kan bearbeta längre avsnitt inom samma fasta tokenfönster. I praktiken fördubblas den effektiva kinesiska kontextlängden ungefär, och finjusteringstiden på en stor uppsättning medicinska Q&A halveras nästan. För att bedöma svarens kvalitet kombinerar författarna två utvärderingsstrategier: BERTScore, som mäter hur semantiskt nära ett genererat svar ligger en referens, och en sofistikerad betygsmodell (DeepSeek-R1) som poängsätter relevans, noggrannhet, fullständighet och flyt. Över dessa mått slår Medical-LLaMA konsekvent både den ursprungliga LLaMA2 och en kinesisk-optimerad variant som inte inkluderade medicinskt specifika tokens. Den visar också små men stadiga förbättringar i relaterade uppgifter såsom igenkänning av medicinska entiteter och klassificering av klinisk text, samtidigt som prestandan på allmänna, icke-medicinska frågor bevaras.
Vad detta betyder för framtidens medicinska AI
För icke-specialister är huvudbudskapet att smartare ”läsglasögon” för AI — här en bättre metod att dela upp medicinskt språk — kan märkbart förbättra hur väl den förstår och besvarar hälsorelaterade frågor. Genom att infoga väl utvalda kliniska tokens i ett befintligt modells vokabulär ökar författarna både effektivitet och noggrannhet utan att kräva massiva nya träningskörningar eller helt nya arkitekturer. Även om arbetet är begränsat till en 7-miljarder-parametermodell och kinesisk medicinsk text pekar det på ett praktiskt recept: skräddarsy det tidigaste lagret i språkbehandlingen till domänen och träna sedan lätt. Denna strategi kan hjälpa framtida medicinska AI-verktyg att bli mer pålitliga partners för kliniker och patienter, särskilt i språk och specialiteter som standardmodeller har svårt att läsa.
Citering: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Nyckelord: medicinska språkmodeller, kinesisk klinisk text, tokenisering, klinisk vokabulär, medicinsk fråge-svar