Clear Sky Science · sv
AE-LFOG-YOLO: robust detektion av skyddshjälmar via adaptiva ankare och belysningsinvariant inlärning
Varför smarta hjälmkontroller spelar roll
På stora byggprojekt och i underjordiska tunnlar kan en enkel skyddshjälm vara skillnaden mellan en nära olycka och en livsförändrande skada. Ändå glömmer eller undviker människor ofta att bära hjälm i det hektiska arbetsmiljön, och mänskliga tillsynspersoner kan inte hålla uppsikt över varje vrå hela tiden. Denna studie undersöker hur man bygger ett automatiserat kamerasystem som pålitligt upptäcker vem som bär hjälm och vem som inte gör det, även när tunneln är mörk, fylld av bländning från lampor eller full av arbetare på olika avstånd från kameran.
Utmaningar med att se i tuff tunnelbelysning
Tunnelbyggen är visuellt extrema miljöer. Ljusstarka strålkastare skapar bländning, medan djupa skuggpartier döljer detaljer. Människor rör sig mot och bort från kameran, så hjälmarna framträder i många olika storlekar. Vanliga AI-detektorer misslyckas ofta i dessa förhållanden: de missar hjälmar i mörka områden, förväxlar andra rundade föremål med hjälmar eller har problem med mycket små eller avlägsna arbetare. Många befintliga system försöker åtgärda detta genom att ljusa upp eller rengöra bilderna innan detektion, eller genom att justera några komponenter i populära YOLO-modeller. Eftersom dessa steg ofta är tillägg istället för en del av en enhetlig inlärningsprocess lämnar de prestanda på bordet och är inte robusta när belysning eller scenlayout ändras.
En ny metod för att lära kameror ignorera dålig belysning
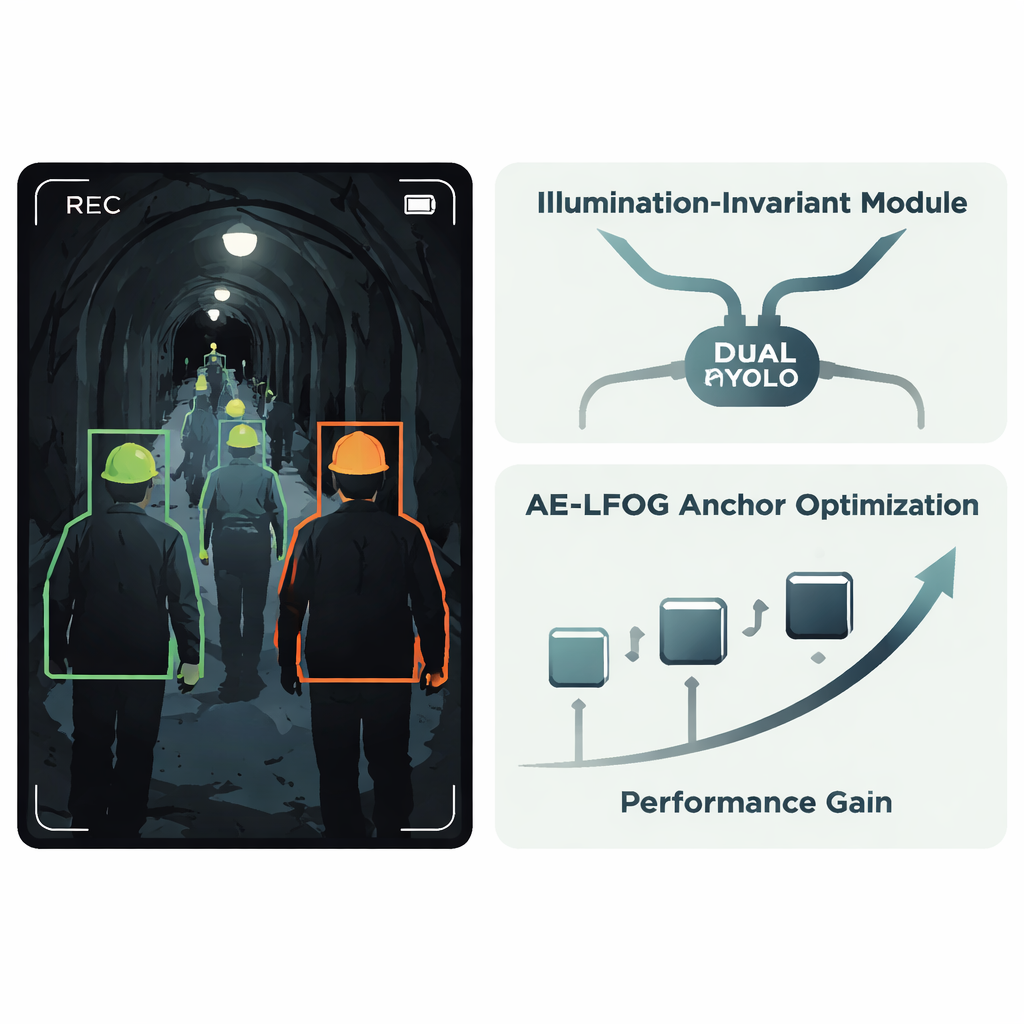
Författarna föreslår ett förbättrat system kallat AE‑LFOG‑YOLO, byggt ovanpå den välanvända detektorn YOLOv8. Den första nyckelidén är en Illumination‑Invariant Module, en liten enhet som läggs till i nätverket och som lär sig skilja på ”vad ljuset gör” och ”hur objekten verkligen ser ut”. Den delar upp inkommande feature‑kartor i en del som främst speglar belysningsmönster och en del som fångar mer stabil form och textur, som den krökta kanten på en hjälm. Genom att använda särskilda gating‑operationer och en gren som fokuserar på kanter och hörn tonar modulen ner ljusstyrkesvängningar och betonar stabil geometri. Eftersom detta sker inne i detektorn snarare än i ett separat förbehandlingssteg, kan hela systemet tränas end‑to‑end för att hålla fokus på själva hjälmarna istället för att luras av bländnings‑ eller mörkfläckar.
Låta modellen utveckla sina egna synvanor
Den andra huvudidén riktar sig mot hur detektorn gissar var objekt kan förekomma. Många detektorer startar från en fast uppsättning ”ankarlådor” som föreslår sannolika objektstorlekar och -former; dessa väljs vanligtvis en gång från träningsdata och uppdateras aldrig. I tunnlar kan dock den upplevda storleken på en hjälm förändras dramatiskt med kamerans avstånd och betraktningsvinkel. AE‑LFOG‑YOLO ersätter statiska ankare med en dynamisk process kallad Adaptive Evolutionary – Light Field Optimized Generation. I slutet av varje träningsrunda perturbas systemets ankarlådor lätt, man betygsätter hur väl de matchar verkliga hjälmar i alla storlekar och kontrollerar också om deras dimensioner är rimliga givet grundläggande kameroptik — hur stor en verklig hjälm bör se ut på sensorn vid typiska arbetsavstånd. Bättre bedömda ankarrader överlever till nästa runda. Med tiden ”utvecklar” detektorn ankare som både passar datan och respekterar hur kameror faktiskt avbildar världen.
Anpassa träningen till verklig bildkvalitet
Utöver att ändra vad modellen letar efter, ändrar författarna också hur den lär sig. De introducerar en träningsstrategi som ägnar mer uppmärksamhet åt att exakt lokalisera hjälmar när bildkvaliteten är dålig, och mer uppmärksamhet åt korrekt klassificering hjälm kontra ingen hjälm när förhållandena är goda. En fysikbaserad poäng, återigen härledd från kamerans avbildningsprinciper, berättar för systemet hur pålitliga bilderna är i varje skede. Om belysning eller fokus är dåligt ökar träningen automatiskt vikten av att få bounding‑boxarna rätt; om förhållandena förbättras flyttas vikten mot klassificering. Detta skapar en återkopplingsslinga där modellen kontinuerligt justerar sina prioriteringar för att matcha den fysiska miljö den kommer att möta i verkliga tunnlar.
Vad testerna visar i praktiken
Forskarlaget testar sitt tillvägagångssätt på en verklig tunnelskyddshjälmsdataset och jämför med flera avancerade YOLO‑baserade metoder. AE‑LFOG‑YOLO detekterar hjälmar med mycket hög noggrannhet, identifierar cirka 95 procent av hjälmarna vid en standardöverlappströskel och överträffar plain YOLOv8‑referensen både i precision och recall. Den körs tillräckligt snabbt för realtidsbruk och visar sig särskilt stark när belysningen manipuleras kraftigt för att simulera extrem mörker eller överexponering. Under dessa tuffa förhållanden behåller den nya modellen högre självförtroende, upptäcker fler små och avlägsna arbetare och fungerar över ett ljusstyrkeintervall som är mer än en tredjedel bredare än referensens, vilket innebär att den förblir pålitlig i en mycket större uppsättning verkliga scener.
Hur detta hjälper att hålla arbetare säkrare
För icke‑specialister är slutsatsen enkel: genom att lära ett AI‑system att förstå inte bara pixlar utan också fysiken i hur kameror ser i svåra miljöer levererar detta arbete en smartare, mer pålitlig väktare på tunnelväggen. AE‑LFOG‑YOLO kan bättre ignorera vilseledande belysning och anpassa sig till förändrade vyer, vilket minskar missade detektioner och falska larm. Utsatt i flera månader på en i drift varande kollektivtrafiklinje har det redan visat att det kan stödja säkerhetsteam i att säkerställa att arbetare bär sina hjälmar, och erbjuder ett praktiskt steg mot säkrare, mer noggrant övervakade byggarbetsplatser.
Citering: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Nyckelord: detektion av skyddshjälm, tunnelbyggnation, datorseende, svagt ljus-bildtagning, YOLOv8