Clear Sky Science · sv
Tillämpning av hierarkisk självövervakad kontrastiv inlärning vid domänanpassningsmatchning av multimodala bilddata från fjärranalys
Att se jorden genom olika ögon
Vädersatelliter, radarmissioner och högupplösta kameror i rymden betraktar samma planet på mycket olika sätt. Denna mångfald är en styrka för uppgifter som att följa översvämningar, kartlägga städer eller övervaka skogar—om vi kan ställa upp bilderna på ett pålitligt sätt. Artikeln som sammanfattas här introducerar en ny artificiell intelligensmetod som lär datorer att matcha dessa mycket olika vyer av jorden mer exakt och med avsevärt mindre mänsklig märkning, vilket öppnar dörren för snabbare och mer robust miljöövervakning.
Varför det är så svårt att matcha olika bilder
Bilder från fjärranalys kommer från många olika sensorer: optiska kameror som ser likt våra ögon, radarsystem som mäter ytstruktur och multispektrala instrument som fångar subtila färgskillnader. Eftersom varje sensor har sitt eget sätt att ”se” kan samma byggnad, skepp eller åker se helt olika ut i olika bilder—kornigt i radar, skarpt i optiskt, eller färgtonat på ovanliga sätt i multispektrala vyer. Traditionella matchningsmetoder bygger antingen på handgjorda visuella drag eller på fullt övervakad djupinlärning som kräver stora mängder noggrant märkta data. Båda angreppssätten tenderar att falla när utseendeskillnaden mellan sensorer är stor eller när märkta exempel är sällsynta, vilket ofta är fallet vid katastrofer eller i avlägsna områden.
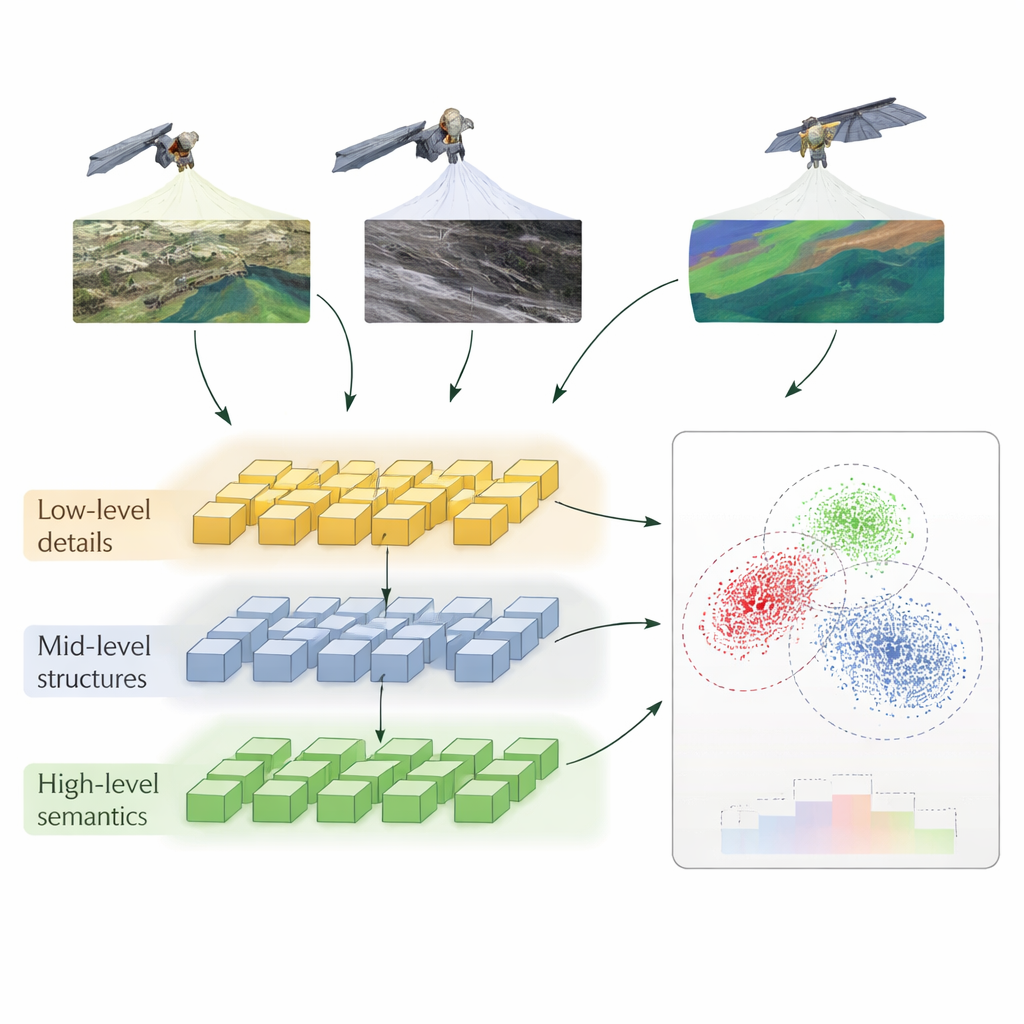
En lagerindelad metod för att lära datorer jämföra
Författarna föreslår en metod kallad Hierarkisk Självövervakad Kontrastiv Inlärning (HSSCL), som förändrar hur ett neuralt nätverk lär sig att jämföra bilder. Istället för att enbart titta på en enda sammanfattning av varje bild extraherar nätverket information på tre nivåer: fina detaljer såsom kanter och texturer, mönster i mellanskala som vägar och byggnadsomriss, och breda mönster såsom stadsstrukturer eller markanvändningstyper. På varje nivå uppmuntrar systemet att drag från olika sensorer som avbildar samma område ska bli mer lika, samtidigt som drag från orelaterade områden trycks isär. Denna ”kontrastiva” träning sker utan mänskliga etiketter: modellen använder kända par av bilder från olika sensorer över samma plats, plus automatiskt funna liknande exempel, för att bygga upp en rik känsla för vad ”samma plats” ser ut som över modaliteter.
Rensa bort brus och bevara geometri
Data från verkligheten är röriga—radarbilder innehåller specklebrus, optiska bilder kan vara dimmiga, och alla kan vara feljusterade med några pixlar. HSSCL hanterar detta genom att först dela upp bilder i små block och tillämpa skräddarsydd brusreducering, vilket hjälper nätverket att fokusera på meningsfull struktur snarare än slumpmässiga variationer. Det matar sedan in drag från olika block i en grafbaserad modul som behandlar varje region som en nod och länkar regioner som ligger nära varandra och ser lika ut. Genom att operera på denna graf stärker ett specialiserat grafneuronät den geometriska konsistensen i matchningar, vilket ökar sannolikheten att vägar stämmer mot vägar och byggnader mot byggnader, även under svåra förhållanden.
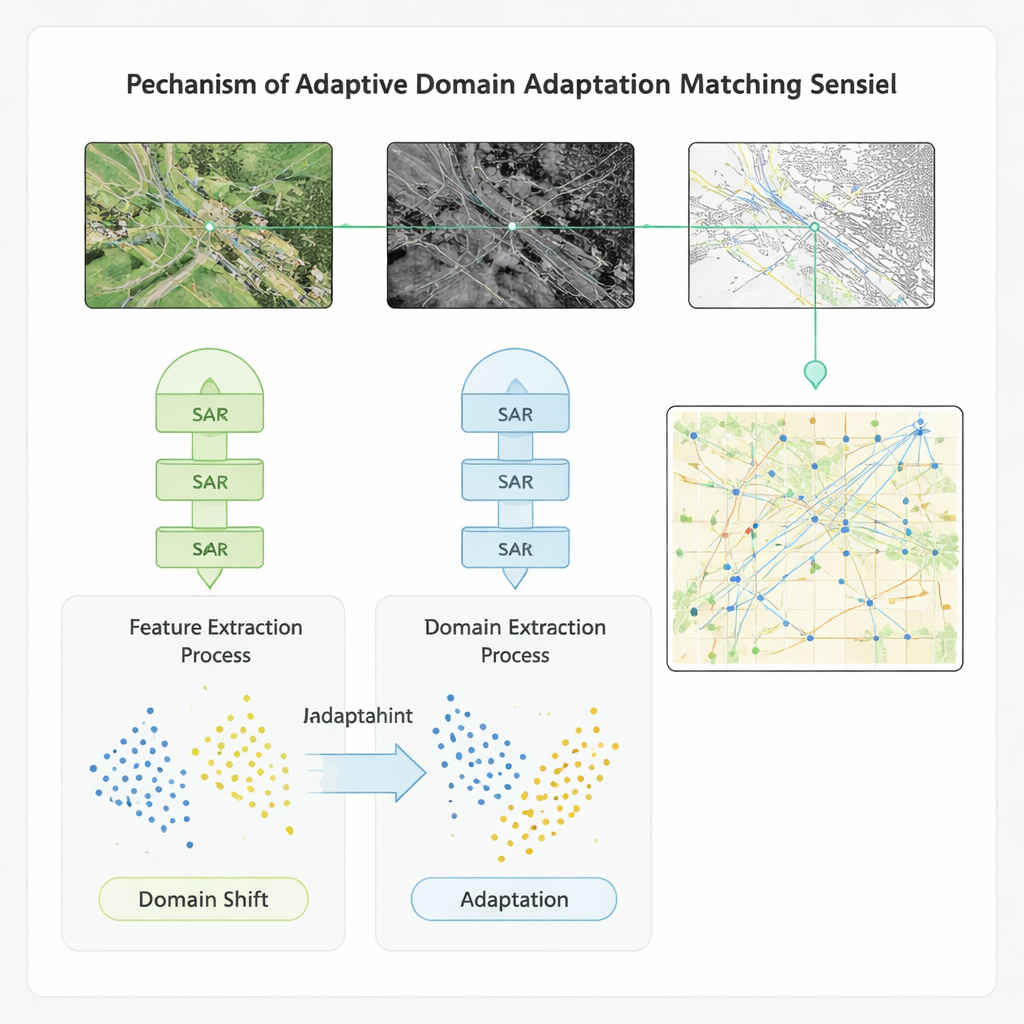
Anpassning över dataset och förhållanden
För att säkerställa att metoden fungerar bortom en enskild benchmark bäddar författarna in sitt inlärningsschema i en domänanpassningsmodell. Denna komponent minskar uttryckligen gapet mellan de statistiska egenskaperna hos drag från olika sensorer och dataset, så att en modell tränad på en region eller ett instrument kan appliceras på en annan med minimal noggrannhetsförlust. Testad på fyra publika dataset som innehåller global multispektral bilddata, högupplösta radar‑optiska par, marktäcke‑scener och fartygsbilder, överträffar den nya metoden flera avancerade referensmetoder. Den förbättrar noggrannhet, återkallelse och F1‑poäng med ungefär 20 procentenheter, snabbar upp matchning med mer än 20 % och ökar noggrannheten i videoliknande defektdetektering—viktigt för övervakning av förändringar över tid—med över 40 %. Metoden visar också starkare motståndskraft mot brus och mot skift mellan tränings‑ och driftsförhållanden.
Vad detta betyder för verklig övervakning
För en lekmannapublik visar studien hur datorer kan tränas att känna igen ”detta är samma plats” över bilder som ser helt olika ut för mänskliga ögon. Genom att lära på flera detaljnivåer, rensa bort brus och uttryckligen anpassa till nya sensorer och regioner gör HSSCL det enklare att kombinera många satellitdataströmmar till en sammanhängande bild. Det kan i sin tur hjälpa räddningspersonal att snabbare ställa in radar‑ och optiska bilder efter en storm, bistå planerare i att följa hur städer eller skogar förändras över år och stödja kontinuerlig spårning av fartyg till sjöss. Medan författarna noterar att extremt brus och mycket stora distortioner fortfarande utgör utmaningar, erbjuder deras arbete en lovande och praktiskt väg mot snabbare, mer pålitlig matchning av de många ögon vi har i omloppsbana.
Citering: Li, Y., Luo, Z., Zhu, G. et al. Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image. Sci Rep 16, 6445 (2026). https://doi.org/10.1038/s41598-026-37312-5
Nyckelord: fjärranalys, multimodala bilder, självövervakad inlärning, kontrastiv inlärning, domänanpassning