Clear Sky Science · sv
Prestandautvärdering av generativa förtränade transformatorer på den nationella veterinärlegitimationsexamen i Japan
Varför smartare veterinärexamina berör alla
Bakom varje besök på djursjukhuset ligger år av rigorös utbildning och en nationell höginsats‑examen. I Japan måste blivande veterinärer klara den nationella veterinärlicensieringsprovet (NVLE), som testar allt från grundläggande biologi till komplex klinisk bedömning. Denna studie ställde en aktuell fråga: kan dagens avancerade AI‑språkmodeller, samma typ som driver populära chattrobotar, klara denna krävande examen på japanska — och vad kan det innebära för veterinärutbildning och djurvård?
Test av AI på ett riktigt veterinärexamen
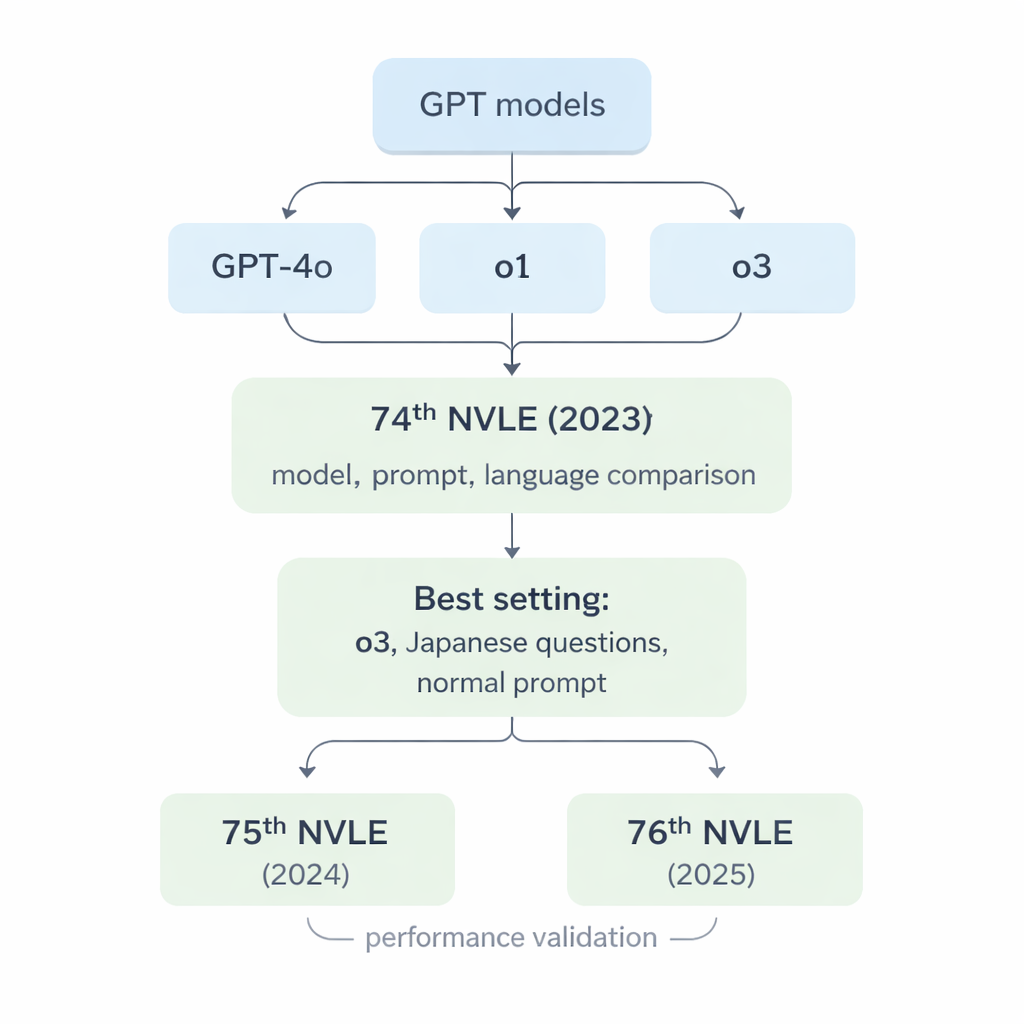
Forskarlaget fokuserade på tre generationer av stora språkmodeller från OpenAI: GPT‑4o, o1 och o3. Dessa system är byggda för att läsa och generera människolikt text, men de var aldrig specialtränade för veterinärmedicin. För att pröva dem använde teamet Japans 74:e NVLE (2023) som referensprov. Examensdelen är uppdelad i fem sektioner, inklusive text‑endast frågor och bildbaserade frågor som visar röntgen, foton eller diagram. Alla frågor är flervalsfrågor med fem alternativ, precis som det riktiga provet som studenter skriver. Modellerna fick varje fråga genom ett standardiserat skript och ombads svara endast med valt sifferalternativ, utan möjlighet att förklara eller förhandla sig fram till poäng.
Vilken AI‑modell klarade sig bäst?
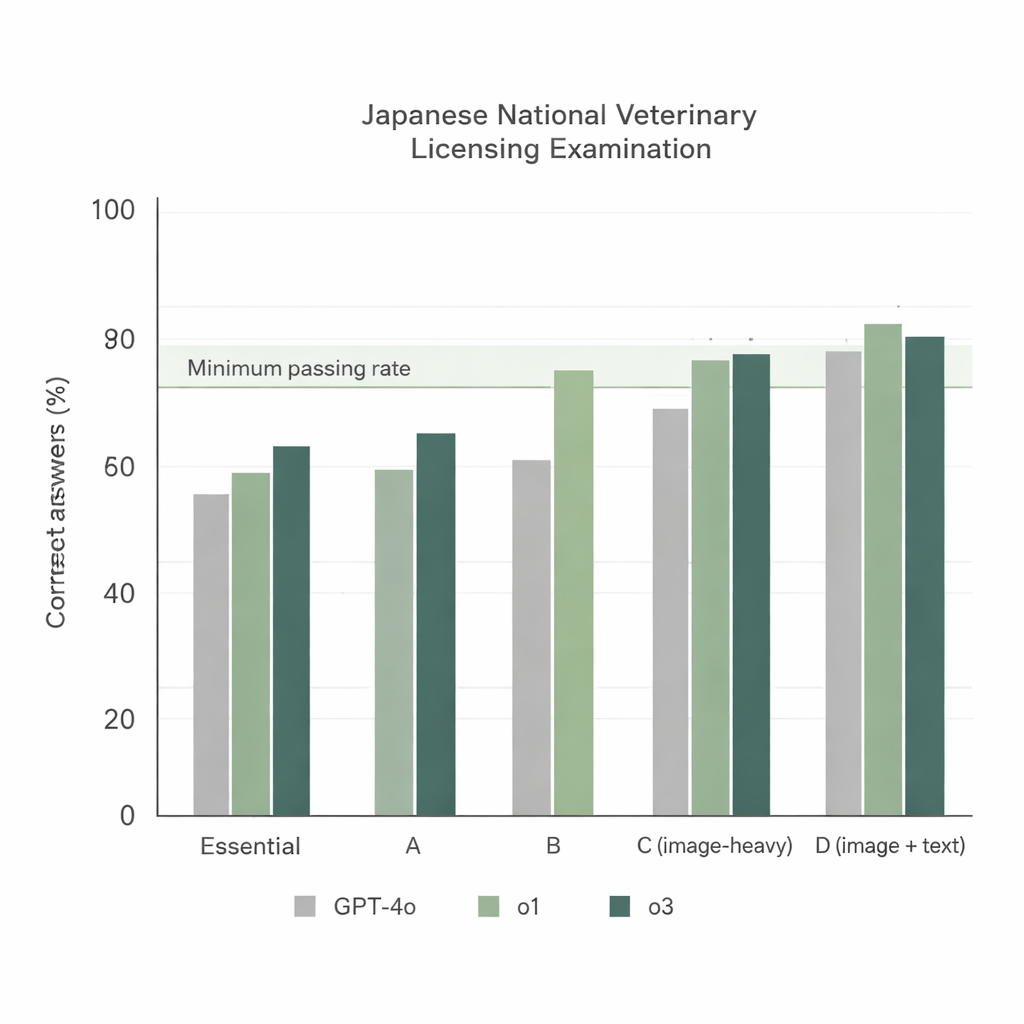
När de tre modellerna gavs 74:e NVLE med den enklaste inställningen — japanska frågor och en rak instruktion — framträdde två tydliga trender. För det första presterade alla modeller starkt på textbaserade sektioner, men o1 och o3 överträffade konsekvent GPT‑4o. För det andra sjönk prestationen för bildtunga sektioner, men o1 och o3 låg fortfarande över det officiella godkännandekravet, medan GPT‑4o föll under i en av dessa sektioner. Sammantaget svarade GPT‑4o rätt på cirka 78 % av frågorna, medan o1 nådde cirka 92 % och o3 cirka 93 %. Eftersom o3 något slog o1 i totalscore valde forskarna o3 för resten av experimenten.
Hjälper prompts eller översättningar egentligen?
Det har skrivits mycket om "prompt engineering" — att utforma invecklade instruktioner för att locka fram bättre svar från AI — och om att översätta lokala provfrågor till engelska för att anpassa dem till modellernas träningsdata. Studien testade dessa idéer direkt med o3‑modellen genom att jämföra en grundläggande problemlösningsprompt mot en mer detaljerad, optimerad prompt, samt japanska frågor mot versioner först översatta till engelska av samma modell. Överraskande nog gjorde ingen av dessa förändringar någon meningsfull skillnad: o3 klarade sig gott i alla sex kombinationerna, och det enklaste tillvägagångssättet (originaltext på japanska med grundprompten) fungerade lika bra som de mer komplicerade uppläggen. Det tyder på att åtminstone för dessa veterinärfrågor förstår de senaste modellerna japanska pålitligt och inte kräver invecklade prompts för att prestera väl.
Hur stabil är prestationen på nyare prov?
För att se om de starka resultaten var en tillfällighet gav teamet därefter o3 de 75:e (2024) och 76:e (2025) NVLE, återigen med enbart originalfrågorna på japanska och normalprompten. Modellen uppnådde totalscores över 92 % på båda proven och översteg godkännandetröskeln i varje sektion, inklusive de bildtunga delarna. De flesta frågor fick samma svar över tre oberoende körningar, vilket visar att o3:s svar i allmänhet var stabila även när viss slump tilläts. När forskarna granskade modellens misstag fann de att felen klustrade sig i två områden: praktisk veterinärkunskap (såsom japansk veterinärlagstiftning) och klinisk medicin, vilka kräver landspecifika regler och flerstegsresonemang snarare än enkel faktakunskap.
Vad detta betyder — och vad det inte betyder
Studien avslutar att toppmoderna GPT‑liknande modeller nu kan klara Japans veterinärlicensieringsexamen på japanska, utan översättningstrick eller komplexa prompts. För veterinärutbildningar och studenter öppnar detta möjligheter att använda AI som studiepartner, frågegenerator eller förklarare av provämnen. För allmänheten signalerar det att AI blir ett kraftfullt verktyg för att organisera och sprida veterinärkunskap. Författarna betonar dock att dessa system inte är redo att ersätta veterinärer eller fatta medicinska beslut på egen hand. Modellerna kan fortfarande misstolka bilder, ha svårt med nyanserad klinisk bedömning och ibland hitta på fakta. Använda med omsorg kan de bli värdefulla assistenter i veterinärutbildning och informationsstöd — men ansvaret för djurhälsa kommer fortsätta ligga tryggt i människohänder.
Citering: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Nyckelord: veterinärlegitimationsexamen, stora språkmodeller, artificiell intelligens i medicin, GPT-prestanda, japansk veterinärutbildning