Clear Sky Science · sv
Effekten av K‑val i K‑faldig korsvalidering på bias och varians i övervakade inlärningsmodeller
Varför det verkligen spelar roll att kontrollera modellen två gånger
Från medicinsk diagnostik till kreditpoängsättning bygger många beslut numera på maskininlärningsmodeller som tränats på historiska data. Men hur kan vi veta om en modell som ser bra ut på skärmen kommer att fungera väl på nya, osedda fall? Ett vanligt sätt att ”testa” modeller är k‑faldig korsvalidering, där data upprepade gånger delas upp i tränings‑ och testdelar. Denna studie ställer en förledande enkel men avgörande fråga: hur många delar — hur stort ska k vara — och hur påverkar det valet i det tysta tillförlitligheten i modellens rapporterade prestanda?
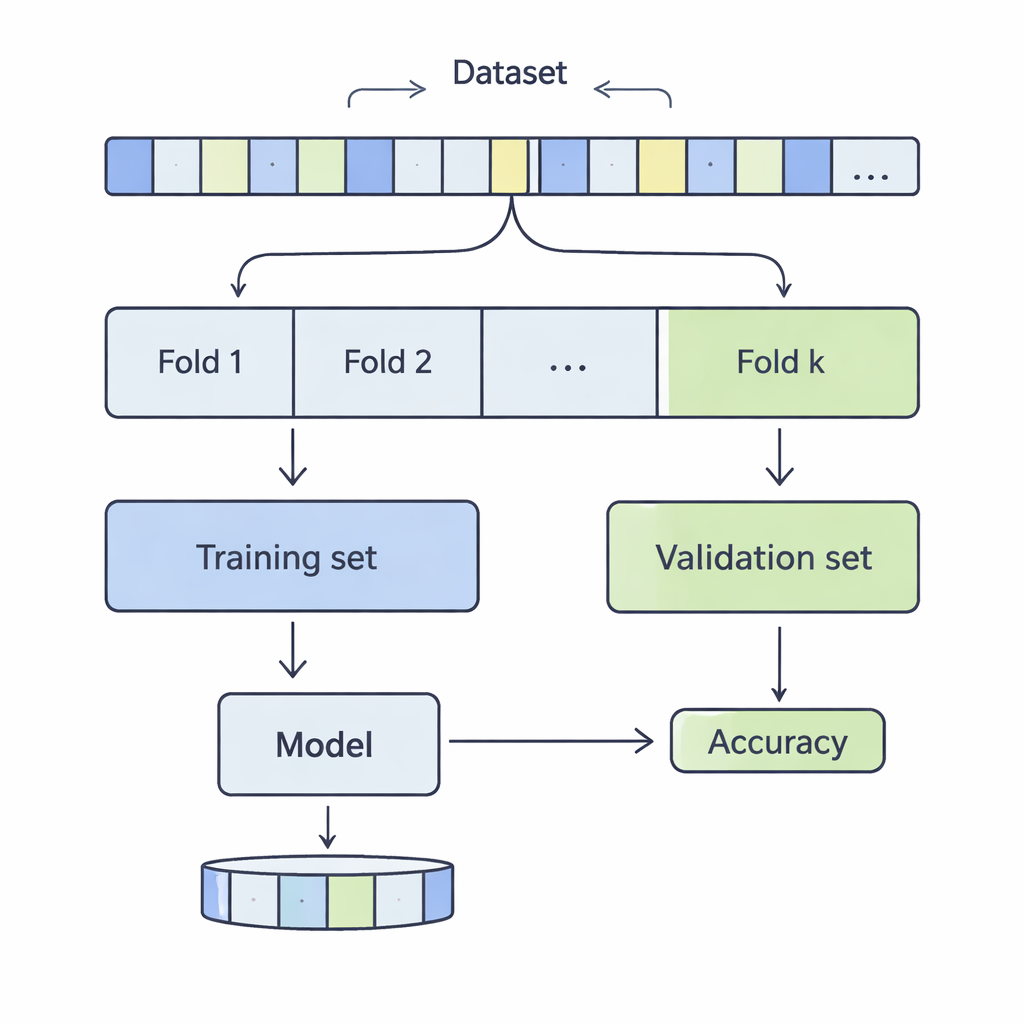
Hur data skivas för en verklighetskontroll
I k‑faldig korsvalidering blandas en datamängd och delas upp i k lika delar, eller folds. Modellen tränas på k‑1 av dessa folds och utvärderas på den återstående; processen upprepas tills varje fold tjänat som testdel. Författarna undersökte k‑värden från 3 till 20, över 12 verkliga datamängder som varierade från några tusen till mer än en halv miljon poster, och täckte områden som inkomstprediktion, medicinska utfall, cyberattacker, spel och vin‑kvalitet. De tillämpade fyra vanliga klassificeringsmetoder — Support Vector Machines, Decision Trees, Logistic Regression och k‑Nearest Neighbours — och mätte noggrant hur valet av k påverkade två centrala aspekter av prestanda: bias och varians.
Vad bias och varians betyder i vardagliga termer
Bias, i detta sammanhang, fångar hur mycket bättre modellen framstår under korsvalidering än den faktiskt presterar på en separat, orörd testmängd. En stor positiv bias innebär att modellen ser överdrivet optimistisk ut under valideringen — likt en student som briljerar på övningstester men snubblar på den riktiga tentan. Varians återspeglar hur mycket modellens prestanda hoppar från fold till fold: låg varians betyder att poängen är stabila över olika datasnitt, medan hög varians innebär stora svängningar. I idealfallet vill vi att både bias och varians är låga så att den rapporterade noggrannheten är både realistisk och stabil.
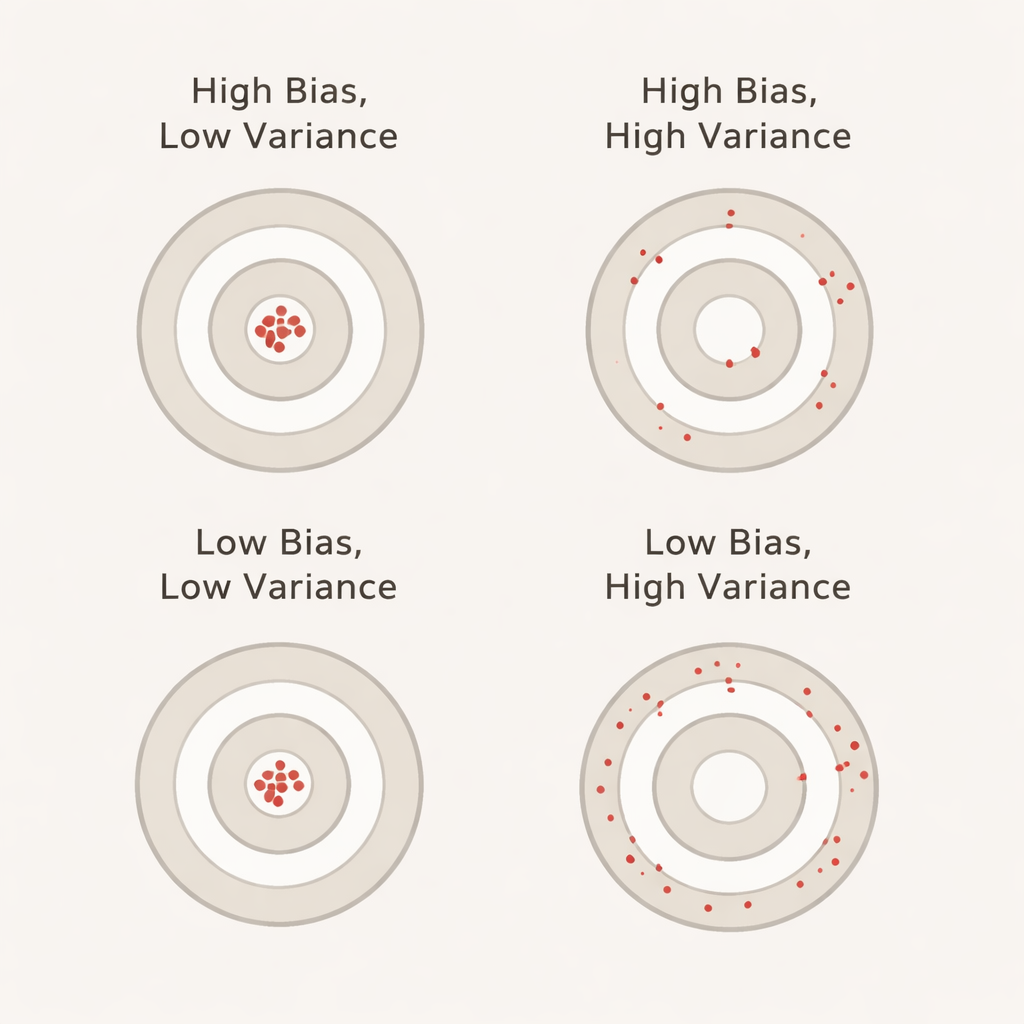
Vad som händer när vi ökar antalet folds
Över alla tolv datamängder och alla fyra algoritmer framträdde ett tydligt mönster: när k ökade steg variansen nästan alltid. Med andra ord gjorde fler folds att den rapporterade noggrannheten blev mindre stabil från en fold till en annan. Detta går emot en vanlig uppfattning att fler folds automatiskt ger bättre, mer tillförlitliga skattningar. Anledningen är att när k är stort blir varje valideringsdel mycket liten och mindre representativ, så resultaten blir mer känsliga för data‑särdrag. Samtidigt beteedde sig bias mindre enhetligt. För k‑Nearest Neighbours och Support Vector Machines tenderade bias att öka med k, vilket innebär att dessa modeller ofta verkade mer korrekta i korsvalidering än de var på den hållna testmängden. Decision Trees visade ungefär balanserade mönster, och Logistic Regression hamnade däremellan med blandade men mer måttliga bias‑förändringar.
Varför de ”standardinställningarna” kan vara missvisande
De flesta praktiska guider föreslår enkelt att man använder fem eller tio folds, oavsett datamängd eller inlärningsalgoritm. Författarnas analys visar att sådan one‑size‑fits‑all‑rådgivning kan vara missvisande. På vissa datamängder och för vissa modeller förstärkte högre k‑värden överoptimistiska intryck av prestanda; på samtliga ökade fler folds variabiliteten i uppskattningarna. Detta är särskilt oroande i områden med höga insatser såsom vård, finans eller infrastruktur, där falsk tilltro till en modells noggrannhet kan få verkliga konsekvenser. Studien argumenterar för att effekterna av k beror både på datans natur (liten vs. stor, brusig vs. renare) och på hur en viss algoritm lär sig från upprepade, nästan identiska träningsuppsättningar.
Huvudbudskapet för alla som använder maskininlärning
Den centrala lärdomen är att antalet folds i korsvalidering inte är en ofarlig teknisk detalj — det formar direkt hur tillförlitliga dina noggrannhetssiffror är. I dessa experiment gjorde fler folds konsekvent resultaten mer svajiga och fick ofta vissa modeller att framstå bättre än de verkligen var. Istället för att blint välja k=5 eller k=10 rekommenderar författarna att betrakta k som en justerbar parameter: kontrollera hur resultaten förändras över ett litet intervall av k‑värden och, där det är möjligt, granska mer än ett prestationsmått. För praktiker och intresserade läsare är budskapet tydligt: när det gäller att utvärdera maskininlärningsmodeller kan sättet du skär upp data nästan vara lika viktigt som själva modellen.
Citering: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Nyckelord: k-fold cross-validation, bias-variance trade-off, model evaluation, machine learning validation, supervised classification