Clear Sky Science · sv
End‑to‑end-protokoll för nödsvar vid tunnelolyckor förstärkt med förstärkningsinlärning
Varför smartare tunnelräddningar är viktiga
När en katastrof inträffar i en vägtunnel—oavsett om det handlar om en krasch, brand eller ett byggnadssammanfall—kan människor bli instängda i en lång, rökfylld, labyrintliknande tunnel med få utrymningsvägar. Mänskliga räddningsarbetare måste rusa in just när sikten försämras, temperaturen stiger och skräp blockerar vägen. Denna studie undersöker hur små flygande robotar, eller droner, styrda av en sofistikerad inlärningsstrategi, kan bli snabba och pålitliga hjälpmedel i sådana farliga situationer — hitta omkomna och kartlägga säkra vägar samtidigt som de håller mänskliga team borta från de värsta farorna.
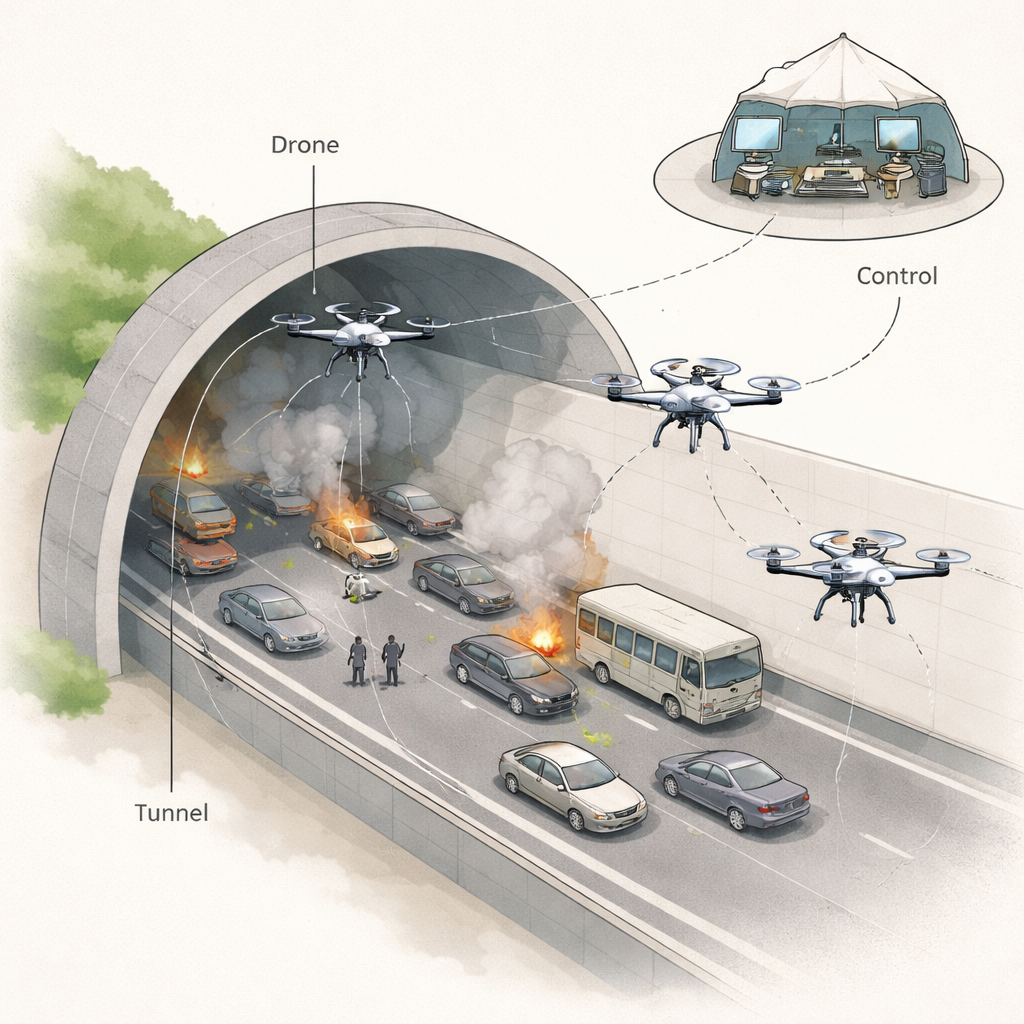
Farliga begränsningar under jord
Moderna städer är beroende av tunnlar för motorvägar, tåg och infrastruktur, men samma slutna utformning som gör dem effektiva gör också olyckor där ovanligt dödliga. Bränder sprider rök snabbt, giftiga gaser byggs upp och smala passager kan täppas igen av kraschade fordon eller fallande betong. Traditionella räddningsteam går ofta in med begränsad information och gissar vart de ska, medan deras radioförbindelser har svårt att fungera genom tjockt berg eller betong. Tidigare katastrofer i Kina och Japan, bland andra, har visat hur svårt det är att nå offer i tid och understryker behovet av verktyg som kan se och tänka framåt på sätt människor inte kan.
Lära droner att utforska och söka
Författarna föreslår ett system där flera autonoma droner samarbetar för att utforska en skadad tunnel, bygga en levande karta och lokalisera instängda personer. Istället för att följa en fast, förprogrammerad rutin lär sig varje drönare av erfarenhet med en metod kallad förstärkningsinlärning: den provar åtgärder, ser vad som händer och upptäcker gradvis vilka val som tenderar att leda till snabbare räddningar och färre misstag. Tunneln representeras som ett rutnät av celler, och dronerna fokuserar på ”frontlinjer” där känt område möter okänt område, och trycker stadigt ut denna gräns. Vid varje steg väljer de bland ett litet antal rutnätsrörelser och uppdaterar sina interna tabeller över vilka drag som fungerat bäst i liknande situationer tidigare.
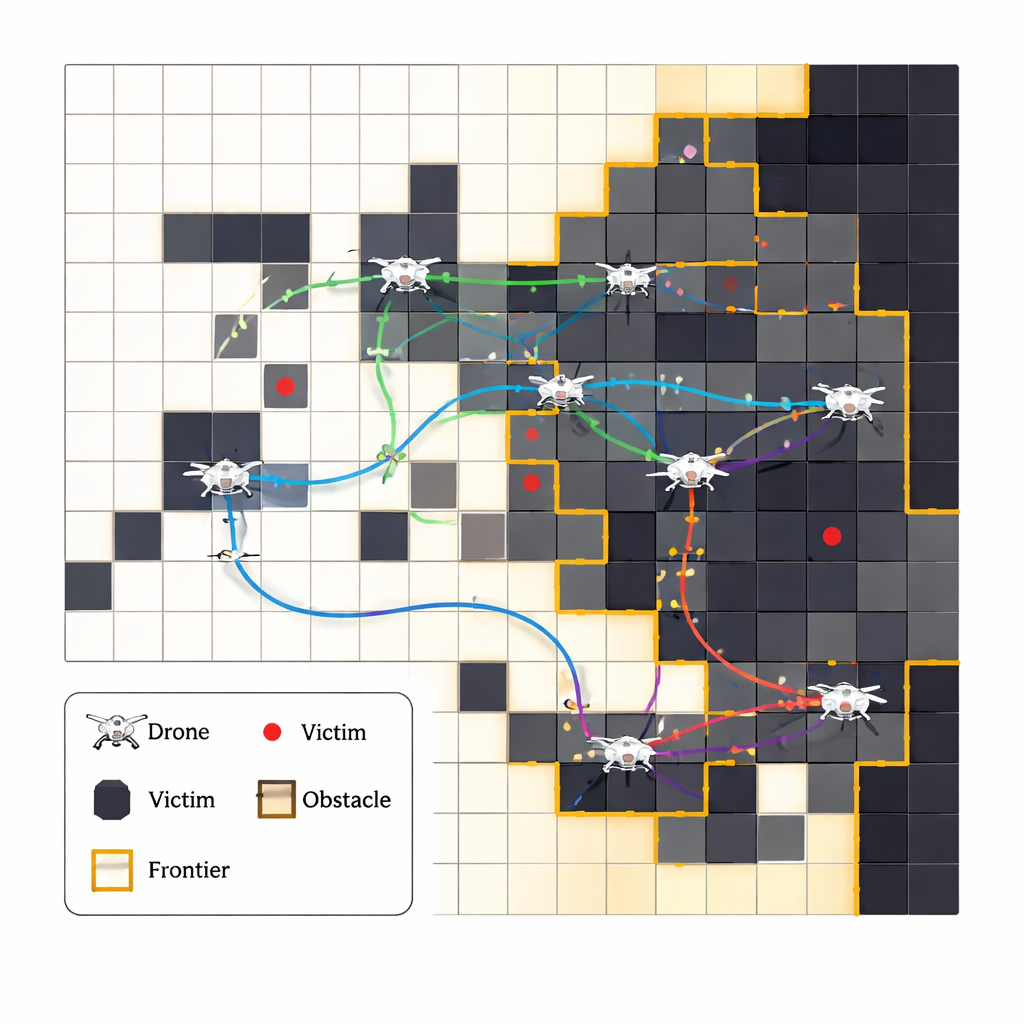
Få många robotar att samarbeta utan ständig kommunikation
Att låta flera droner söka i samma tunnel samtidigt skapar en ny utmaning: hur undviker de att flyga in i varandra eller upprepade gånger skanna samma område, särskilt när kommunikationen kan vara opålitlig? Istället för att ge dem en central ledare eller konstant radiotrafik utformar forskarna ett enkelt poängsystem som tyst uppmuntrar bra gruppbeteende. En drönare får en stor belöning när den upptäcker en ny person, men bestraffas om den slösar tid på att återbesöka samma plats, kolliderar med en annan drönare eller ”misslyckas” genom att tömma sitt batteri. Med tiden pressar detta varje drönare att favorisera outforskade områden och hålla sig borta från sina lagkamrater, så en form av samarbete uppstår naturligt ur de delade konsekvenserna, även om varje drönare tekniskt sett lär sig på egen hand.
Låna knep från vargar för att undvika att fastna
Ren trial‑and‑error‑inlärning kan ibland fastna i säkra men suboptimala vanor—som att alltid välja en bekant korridor istället för att pröva en riskfylld genväg. För att hålla dronerna nyfikna lånar teamet idéer från en matematisk modell av hur gråvargar jagar i flock. Denna komponent, ”Grey Wolf Optimization”, skjuter dronerna att ibland efterlikna de bäst presterande sökmönstren som setts hittills, samtidigt som det lämnas utrymme för utforskning. I praktiken formar det vilka nya åtgärder som prövas, vilket hjälper inlärningsprocessen att hoppa ur återvändsgränder och anpassa sig när tunneln förändras—till exempel om en del av vägen plötsligt blockeras av brand eller rasmassor.
Testa metoden i virtuella katastrofer
Eftersom det inte är säkert att testa oprövade strategier i verkliga nödtunnlar bygger forskarna detaljerade datasimuleringar som efterliknar smala korridorer, återvändsgränder, hinder och utspridda offer. De jämför sitt inlärningsbaserade system med flera andra metoder, inklusive ren slumpvandring och fristående optimering utan inlärning. Både i tester med en enskild drönare och med flera drönare hittar deras metod offer snabbare, utforskar mer av tunneln med färre onödiga steg och undviker kollisioner mer pålitligt. Viktigt är att det görs med lättviktiga, tabellbaserade beräkningar istället för energikrävande djupa nätverk, vilket innebär att det realistiskt skulle kunna köras på små omborddatorer under en verklig nödsituation.
Vad detta kan betyda för framtida räddningsinsatser
Studien visar att svärmar av relativt enkla drönare, vägledda av noggrant utformade inlärningsregler och några idéer hämtade från naturen, kan bli värdefulla partner för brandkårer och räddningslag vid tunnelkatastrofer. Genom att snabbt kartlägga rökfyllda, föränderlig miljöer och rikta in sig på sannolika offerplatser utan ständig mänsklig kontroll kan sådana system spara dyrbara minuter i responstid samtidigt som de minskar riskerna för förstainsatserna. Även om arbetet hittills bygger på simuleringar och idealiska sensorer, lägger det en praktisk grund för framtida verkliga system som måste fungera under strikta tids-, energi‑ och beräkningsbegränsningar i några av de mest krävande räddningsmiljöerna på jorden.
Citering: ur Rehman, H.M.R., Gul, M.J., Younas, R. et al. End-to-end emergency response protocol for tunnel accidents augmentation with reinforcement learning. Sci Rep 16, 6226 (2026). https://doi.org/10.1038/s41598-026-37191-w
Nyckelord: tunnelnödsvar, sökochräddningsdroner, fleragenters förstärkningsinlärning, robotisk katastrofhantering, autonom utforskning