Clear Sky Science · sv
En metod för att upptäcka skyddshjälmar under jord baserad på YOLOv11-SRA-modellen
Varför smartare hjälmkontroller är viktiga under jord
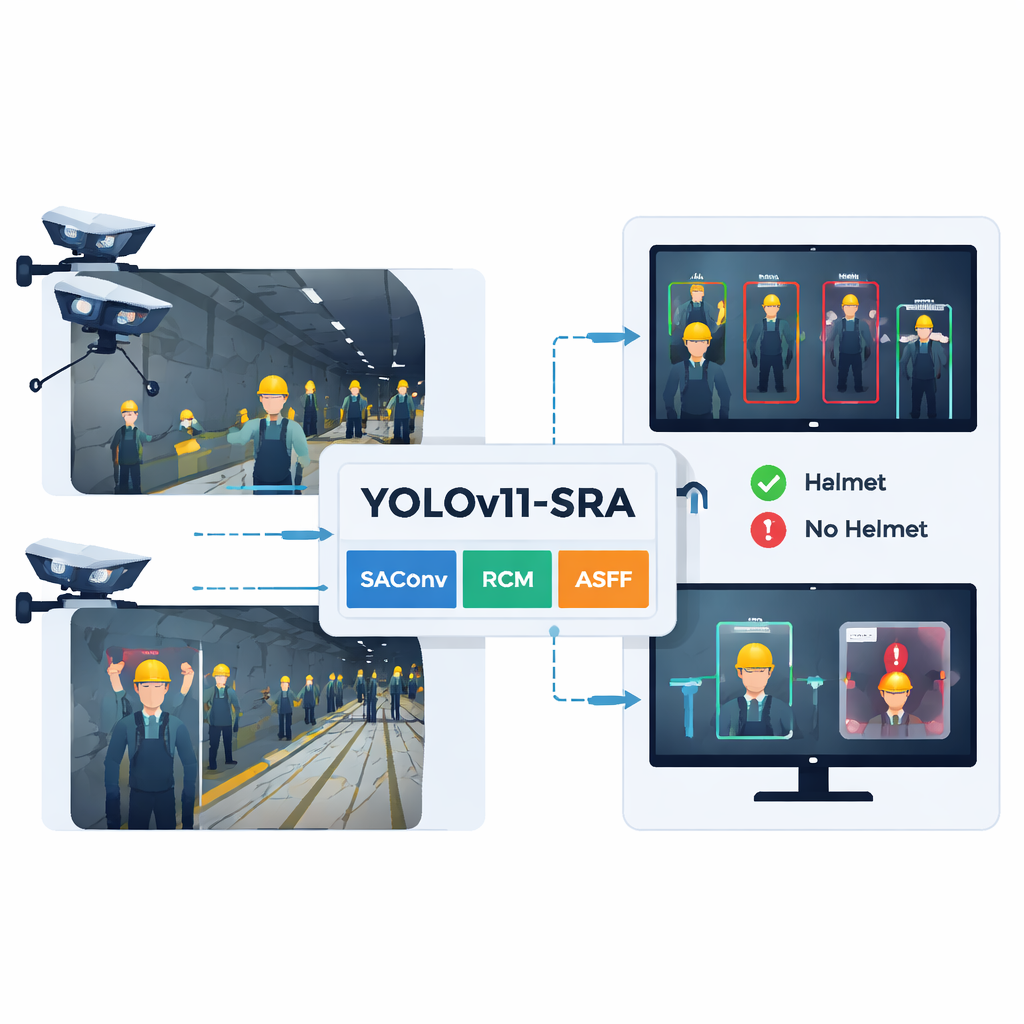
Djupt under jord i gruvor och tunnlar förlitar sig arbetare på skyddshjälmar som sista försvarslinje mot stenras, maskiner och låga tak. Men i mörka, dammiga och trånga gångar är det svårt för tillsynspersoner—och även för konventionella kameror—att avgöra vem som är korrekt skyddad. Denna artikel presenterar ett nytt datorseendesystem, baserat på en förbättrad YOLOv11-SRA-modell, som kan automatiskt upptäcka hjälmar och blottade huvuden i realtid, även när ljuset är svagt, sikten är blockerad och människor befinner sig långt från kameran.
Faran med att förlita sig på mänskliga kontroller
Traditionell hjälminspektion i gruvor förlitar sig fortfarande i hög grad på att människor går igenom tunnlarna för att leta efter överträdelser, eller på grindar och kontrollpunkter som arbetare måste passera. Dessa metoder är långsamma, täcker bara några få platser och kan missa riskbeteenden när människor rör sig djupare under jord. Sensorbaserade hjälmar med taggar eller inbyggd elektronik erbjuder viss automatisering, men de är dyra, svåra att underhålla i hårda förhållanden och kräver modifiering av varje hjälm. När gruvdrift expanderar och arbetspassen blir längre har dessa äldre tillvägagångssätt svårt att erbjuda det dygnet-runt, gruvomfattande vaksamhet som behövs för att förebygga olyckor.
Att lära kameror se hjälmar i svåra förhållanden
Senaste framstegen inom djupinlärning har förändrat hur datorer tolkar bilder, särskilt för att upptäcka objekt som bilar eller fotgängare. YOLO-familjen av algoritmer används brett eftersom den kan skanna en bild och lokalisera objekt i ett enda, snabbt svep—idealisk för livevideo. Underjordiska scener pressar dock dessa system till deras gränser. Hjälmar kan framträda som små färgade fläckar på ett avlägset huvud, vara halvskymda bakom rör eller maskiner, eller smälta in i bakgrunden under dämpad och ojämn belysning. Författarna utformade YOLOv11-SRA specifikt för att hantera dessa problem, så att gruvkameror pålitligt kan skilja mellan skyddade och oskyddade arbetare.
En tredelad uppgradering av en populär visuella motor
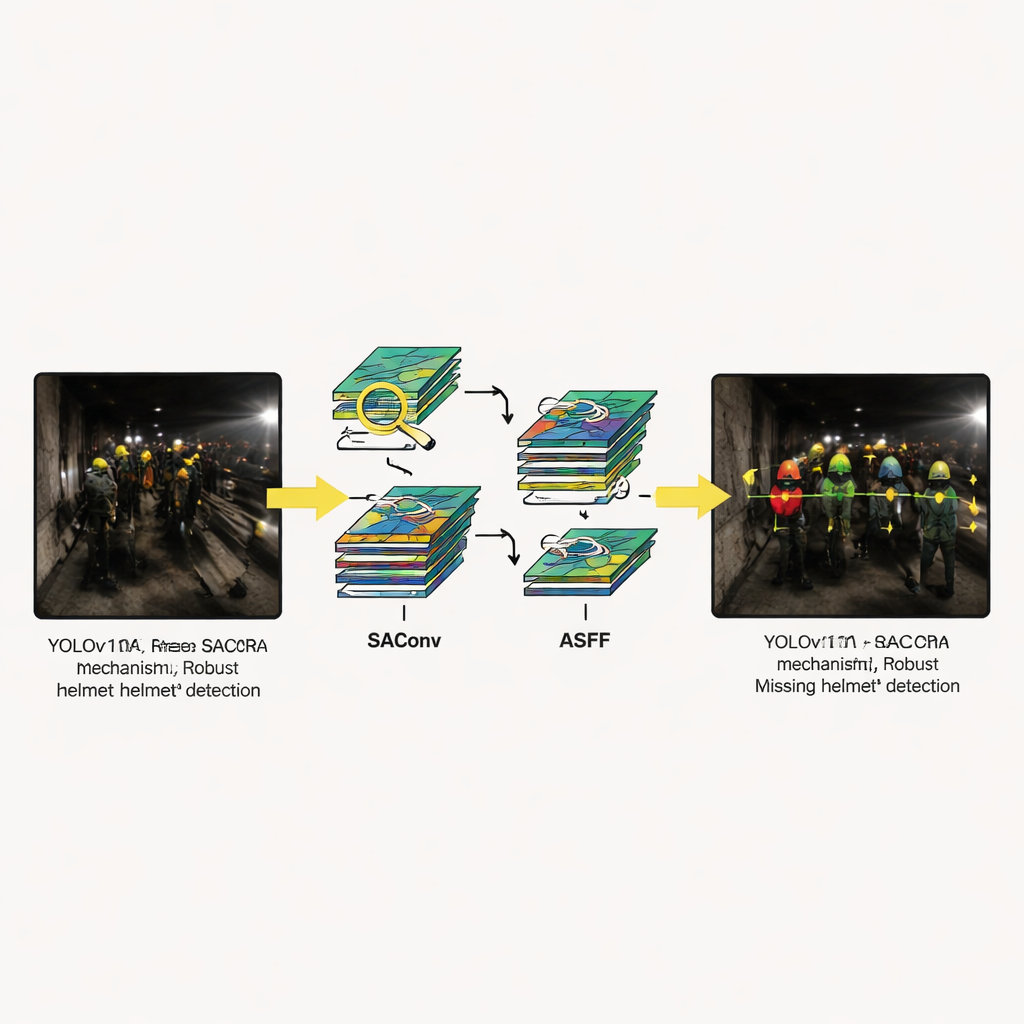
Den nya modellen behåller den övergripande strukturen hos YOLOv11—input, backbone, neck och detektionshuvud—men lägger till tre specialiserade moduler. För det första tillåter SAConv-blocket nätverket att betrakta varje bild i flera "zoomnivåer" samtidigt, så att det kan fånga både små avlägsna hjälmar och större närbilder utan extra kostnad. För det andra vägleder RCM-blocket modellen att fokusera på långa, rektangulära regioner som matchar den typiska formen av en persons huvud och axlar i en tunnel, vilket hjälper den att följa hjälmkonturer även när utrustning eller andra arbetare skymmer. För det tredje blandar ASFF-blocket information från flera bildskalor, vilket låter systemet välja, pixel för pixel, vilken nivå som bäst beskriver varje del av scenen. Tillsammans minskar dessa uppgraderingar förvirring mellan hjälmar och bakgrundsbrus och skärper konturerna hos små eller delvis synliga hjälmar.
Att testa systemet
För att undersöka om dessa idéer fungerar i praktiken tränade och testade forskarna modellen på CUMT-HelmeT, en offentlig samling av underjordiska övervakningsbilder märkta med "hjälm" och "ingen hjälm", såväl som andra vanliga objekt. Eftersom den råa datamängden är relativt liten utökade de den femfaldigt genom att beskära, rotera och ljusa upp bilder för att efterlikna olika kameravinklar och belysning. På denna utmanande benchmark uppnådde YOLOv11-SRA en mean average precision på cirka 84 % och en recall nära 80 %, vilket tydligt slog flera välkända detektorer, inklusive nyare YOLO-versioner, RetinaNet, SSD och Faster R-CNN. Trots förbättrad noggrannhet förblir modellen kompakt och effektiv: den använder färre parametrar och mindre beräkning än de flesta konkurrenter, och kan analysera nästan 100 bilder per sekund på ett modernt grafikkort, tillräckligt snabbt för realtidslarm.
Se igenom mörker, damm och bländning
Visuella exempel belyser hur systemet beter sig i situationer som regelbundet förvirrar äldre metoder: hjälmar som är halvskymda, scener upplysta endast av svaga lampor, arbetare långt från kameran och hårda reflexer från blanka ytor. I varje fall ger YOLOv11-SRA mer säkra och konsekventa detektioner än konkurrerande modeller. Den missar mindre sannolikt små eller svaga hjälmar och är bättre på att undvika falsklarm när ljusa fläckar eller rör imiterar hjälmfärger. Ablationsstudier—där författarna slår på och av enskilda moduler—visar att varje del bidrar, men att de största vinsterna uppnås när alla tre kombineras, vilket bekräftar att utformningen fungerar som en integrerad helhet snarare än en samling isolerade trick.
Från forskningsprototyp till säkrare skift
I tillgängliga termer innebär detta arbete att ge gruvkameror ett skarpare, mer anpassningsbart "öga" för grundläggande skyddsutrustning. Genom att mer pålitligt flagga arbetare som saknar hjälm, även i brusiga, svagt ljusande videoströmmar, skulle YOLOv11-SRA-systemet kunna hjälpa tillsynspersoner att ingripa tidigare och minska risken för huvudskador. Eftersom modellen är relativt lätt kan den distribueras på inbyggda enheter nära kamerorna i stället för enbart i avlägsna datacenter. Författarna noterar att bredare träningsdata och ytterligare effektivisering kan göra tillvägagångssättet ännu mer robust, men deras resultat pekar redan mot smartare, mer skalbar säkerhetsövervakning i de krävande förhållandena i modern underjordisk gruvdrift.
Citering: Wang, L., Wan, X., Shi, X. et al. A method for detecting safety helmets underground based on the YOLOv11-SRA model. Sci Rep 16, 6194 (2026). https://doi.org/10.1038/s41598-026-37148-z
Nyckelord: säkerhet i underjordiska gruvor, hjälmupptäckt, datorseende, övervakning i realtid, djupinlärning