Clear Sky Science · sv
Jämförande analys av övervakade och ensemblemodeller med oövervakad utforskning för prediktion av Alzheimers sjukdom
Varför tidig varning är viktig
Alzheimers sjukdom berövar människor gradvis minnet och självständigheten, ofta långt innan en säker diagnos ställs. Familjer, läkare och vårdsystem tjänar alla på att varningssignaler upptäcks tidigt, eftersom det är då behandling, planering och stöd kan göra störst skillnad. Denna studie ställer en praktisk fråga: kan noggrant utformade datorprogram, tränade på rutinmässig klinisk information och hjärnavbildningar, upptäcka demens mer tillförlitligt än dagens standardverktyg — och samtidigt avslöja dolda mönster i hur sjukdomen utvecklas?
Att omvandla patientregister till användbara signaler
Forskarna använde en välkänd datainsamling kallad OASIS-2, som följer 150 äldre vuxna i åldern 60 till 96 över flera år. För varje besök innehåller datasetet grundläggande information som ålder, utbildningsår och socioekonomisk status, liksom kognitiva testresultat och mått härledda från MR-hjärnskanningar, till exempel totalt hjärnvolym. Innan någon prediktion kunde göras rengjorde teamet data, tog bort identifierare och tvetydiga fall, fyllde i ett litet antal saknade värden och satte alla numeriska mätningar på en gemensam skala. De hanterade också ett viktigt verklighetsproblem: betydligt fler i datasetet var friska än dementa. För att förhindra att modellerna helt enkelt gissade ”ingen demens” det mesta av tiden använde forskarna viktning som gör att fel på den mindre, dementa gruppen räknas tyngre under träningen.
Att jämföra klassiska verktyg med modellteam
Med detta förberedda dataset jämförde författarna välkända maskininlärningsverktyg med mer avancerade ”ensembler”, som kombinerar flera modeller till en starkare prediktor. Den klassiska gruppen inkluderade logistisk regression, beslutsträd, stödvektormaskiner och random forests. Ensemblegruppen bestod av AdaBoost, XGBoost och en majoritetsröstningsmodell som blandade tre finjusterade klassificerare. Alla modeller tränades på en del av data och testades på avhållna fall, med prestanda bedömd med hjälp av noggrannhet (accuracy), förmågan att korrekt flagga dementa individer (recall) och arean under ROC-kurvan, en sammanfattning av hur väl modellen särskiljer friska från sjuka fall. 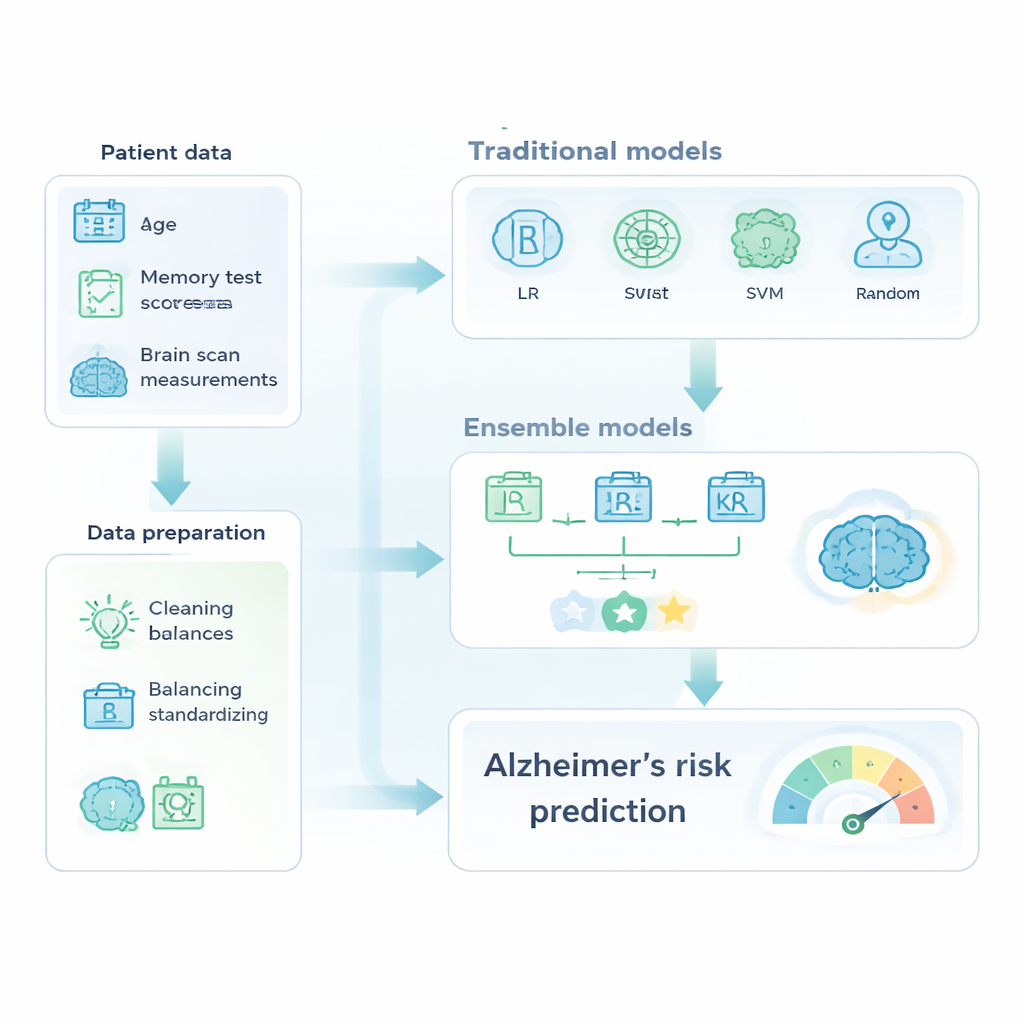
När många sinnen slår en
Direktjämförelsen var tydlig. Medan de bästa traditionella metoderna presterade rimligt bra, nådde de en platå kring nivåerna som rapporterats i tidigare studier, med testnoggrannheter i det låga till mittersta 80-procentspannet. I kontrast nådde majoritetsröstningsensemblen omkring 95 procent noggrannhet och en liknande hög ROC-poäng, och överträffade den ofta citerade 92-procentsgränsen. AdaBoost och andra ensemblemodeller presterade också bättre än någon enskild traditionell modell. Denna fördel uppstår eftersom olika algoritmer fångar upp skilda aspekter av data; genom att låta dem ”rösta” jämnar ensemblen ut individuella egenheter och överanpassning, vilket leder till mer stabila prediktioner. Priset för denna vinst är minskad transparens: det är svårare vid en blick att se varför en ensemble fattade ett särskilt beslut jämfört med en enkel regression eller ett enskilt träd. 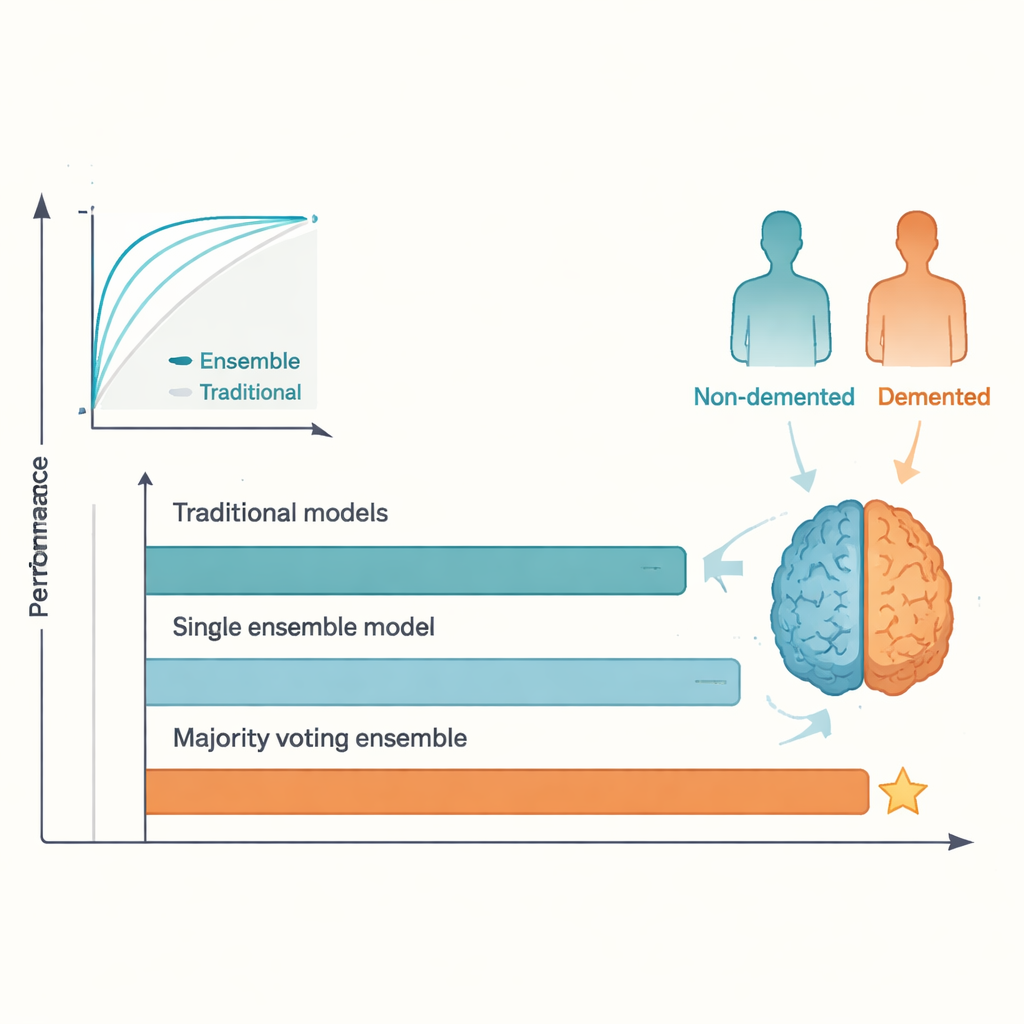
Söka naturliga grupperingarna i data
Bortom frågan vem som har demens undersökte forskarna också hur patienter naturligt grupperar sig, oberoende av diagnosetiketter. För att göra detta transformerade de alla kontinuerliga variabler till ordnade kategorier — såsom intervall för ålder eller hjärnvolym — och använde en teknik kallad multipel korrespondensanalys för att komprimera denna rika information till ett fåtal underliggande dimensioner. De använde sedan k-means-klustring för att dela upp dessa punkter i ett litet antal sammanhängande grupper. Vissa kluster dominerades av personer med bevarad hjärnvolym och normala kognitiva poäng, medan andra innehöll individer med låg hjärnvolym, dåliga testresultat och mer uttalade demensgrader. Att dessa oövervakade kluster stämde väl överens med klinisk status tyder på att data bär på en stark, konsekvent signal om sjukdomsrisk och förlopp.
Vad detta betyder för patienter och kliniker
För en lekman är slutsatsen enkel: när de utformas omsorgsfullt kan modellteam inom maskininlärning upptäcka Alzheimersrelaterad demens i strukturerade kliniska data mer precist än äldre metoder, och de kan göra det med information som många kliniker redan samlar in. Samtidigt visar explorativa tekniker att människor faller i distinkta profiler av hjärnhälsa och kognitiv funktion, vilket antyder olika vägar sjukdomen kan ta. Även om studien begränsas av sitt måttliga stickprov och av komplexiteten i att tolka ensemblemodeller, visar den att kombinationen av kraftfull prediktion och noggrann explorativ analys både kan skärpa tidig upptäckt och fördjupa vår förståelse av hur Alzheimers tar fäste.
Citering: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Nyckelord: Alzheimers sjukdom, demensprediktion, maskininlärning, ensemblemodeller, hjärnavbildning