Clear Sky Science · sv
Jämförande studie om att förutsäga postoperativ fjärrmetastasering vid lungcancer med maskininlärningsmodeller
Varför det är viktigt att förutsäga cancerutbredning
Lungcancer är fortfarande en av de dödligaste cancerformerna, även när kirurger avlägsnar alla synliga tumörer. Många patienter utvecklar senare dolda cancerrumor som dyker upp i hjärnan, skelettet, levern eller andra organ. Läkare skulle vilja veta tidigt efter operation vilka patienter som löper större risk för denna typ av fjärrspridning, så att man kan anpassa uppföljningar och behandlingar. Denna studie undersöker om moderna datorprogram, kända som maskininlärningsmodeller, kan hjälpa till att förutsäga vilka som har högre risk, med hjälp av information som sjukhusen redan samlar in i rutinvård.
Noga granskning av många patienter
Forskarna granskade journaler från 3 120 personer med stadium I till III lungcancer som fått sina tumörer avlägsnade vid ett enda cancercenter i Kina. Alla hade minst två års uppföljning. För varje patient samlade teamet 52 typer av information, inklusive ålder, kön, kroppsvikt, rökhistorik, röntgenfynd, operationsdetaljer, laboratorietester och om de fick ytterligare behandlingar som cytostatika eller strålbehandling efter operationen. Med tiden utvecklade 596 av dessa patienter fjärrmetastaser, medan 2 524 inte gjorde det. Denna verklighetsbaserade blandning gjorde det möjligt för teamet att se vilka egenskaper som var kopplade till framtida spridning.
Lära datorer att känna igen riskmönster
I stället för att förlita sig på en enda formel jämförde forskarna nio olika maskininlärningsmetoder, från enkla beslutsträd till mer avancerade tekniker som kombinerar många små modeller. De använde först ett matematiskt filter för att krympa de ursprungliga 52 faktorerna till en mindre, mer informativ uppsättning. Sedan tränade och testade de upprepade gånger varje modell på delar av data, och testade mot patienter modellen aldrig tidigare ”sett”. Eftersom endast ungefär en av fem patienter utvecklade metastas justerade man träningen så att datorn inte bara skulle förutsäga ”låg risk” för alla. De bedömde prestanda med flera mått, inklusive hur väl modellerna separerade hög- från låg-riskpatienter och hur väl de förutsagda riskerna överensstämde med vad som faktiskt hände.
Hitta den mest tillförlitliga modellen
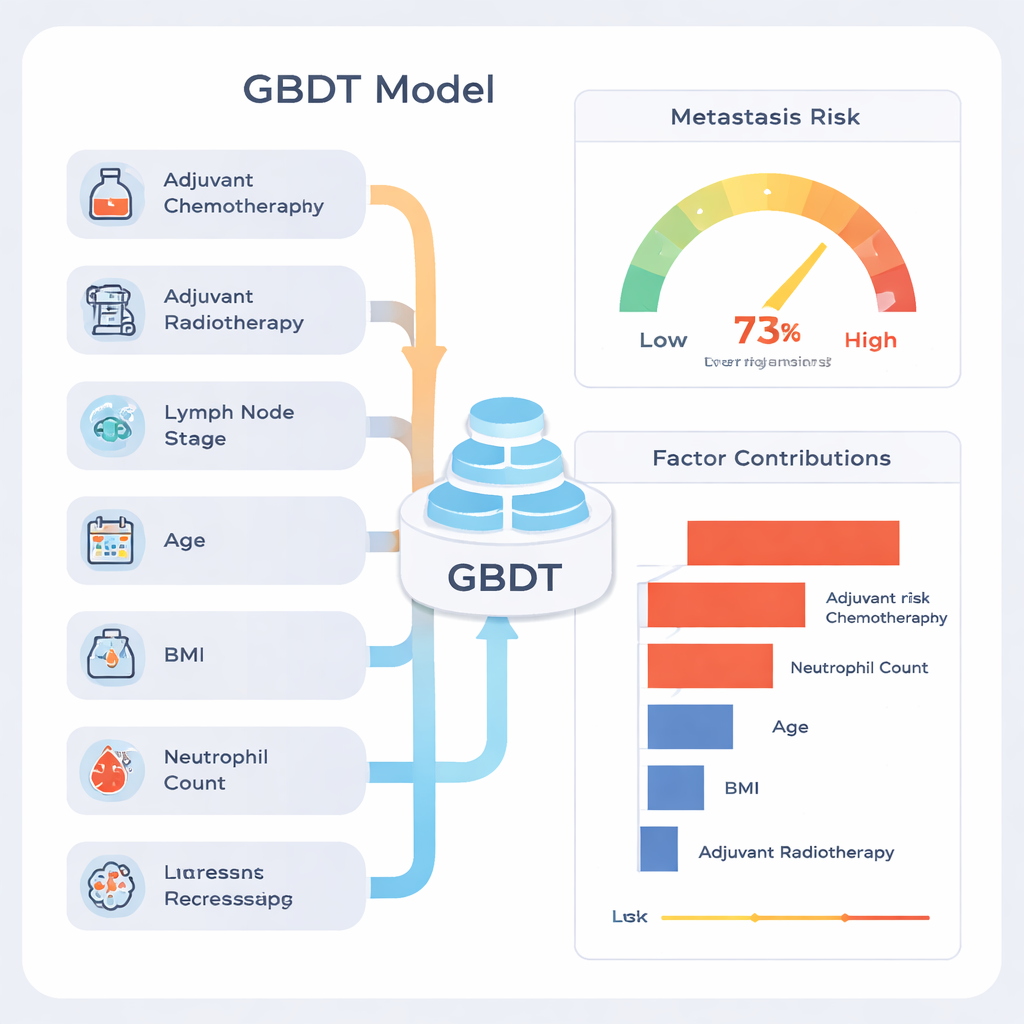
Bland de nio metoderna utmärkte sig en som kallas Gradient Boosting Decision Tree (GBDT). På testdata rankade den patienter korrekt med en total noggrannhet på cirka 77 %, och dess sammanfattande diskrimineringspoäng (arean under ROC-kurvan) var 0,81, vilket anses starkt för medicinska prediktionsverktyg. Modellen var särskilt bra på att identifiera patienter som skulle förbli metastasfria (hög ”negativ prediktivt värde”), vilket betyder att ett lågriskresultat oftast var lugnande. När teamet undersökte hur modellen presterade över många olika slumpmässiga uppdelningar av data förblev dess prestanda stabil, vilket tyder på att den inte bara memorerade särdrag i en viss delmängd.
Vad som driver modellens beslut
En vanlig kritik mot maskininlärning är att den kan vara en ”svart låda”. För att hantera detta använde författarna en förklaringsmetod kallad SHAP, som tilldelar varje faktor ett bidrag till den slutliga riskuppskattningen för varje patient. Denna analys visade att de starkaste signalerna var om patienten fått cytostatika eller strålbehandling efter operation, hur många lymfkörtlar som innehöll cancer, ålder, kroppsmassindex (BMI) och det preoperativa neutrofila antalet, en typ av vita blodkroppar. Patienter med mer avancerad lymfkörtelinvolvering och tecken på systemisk inflammation tenderade att ha högre förutsagd risk. Författarna betonar att höga bidrag från cytostatika och strålbehandling inte betyder att dessa behandlingar orsakar metastaser; snarare är de markörer för att läkarna redan bedömt sjukdomen som mer aggressiv, så dessa patienter hade från början högre risk.
Hur detta kan hjälpa patienter i praktiken
Där modellen använder information som de flesta cancercenter redan registrerar, skulle den, efter ytterligare tester, kunna byggas in i sjukhusens mjukvara. För en ny patient som just genomgått lungoperation kan systemet hämta deras data och ge en personlig sannolikhet för fjärrmetastasering, tillsammans med en enkel förklaring av vilka faktorer som höjer eller sänker risken. Kliniker kan då använda detta för att avgöra vem som kan behöva tätare bilduppföljning, extra rådgivning eller inkludering i kliniska studier, och vem som tryggt kan undvika intensiv övervakning. Studien gjordes på ett enda sjukhus, så verktyget behöver fortfarande kontrolleras och förfinas i andra regioner och vårdsystem. Men det erbjuder en lovande modell för att kombinera rutinmässiga kliniska data med transparent maskininlärning för att förbättra långtidsvården för personer med lungcancer.
Citering: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Nyckelord: lungcancer, fjärrmetastasering, maskininlärning, riskprediktion, postoperativ uppföljning