Clear Sky Science · sv
Innovativ temporär summering för komplex videoklassificering
Varför smartare videosummeringar spelar roll
Från övervakningskameror till strömningstjänster spelas mer video in än vad människor eller datorer bekvämt kan hantera. Varje sekund innehåller dussintals bildrutor, men många av dem är nästan identiska. Den här artikeln undersöker ett sätt att krympa långa videor till endast de mest talande ögonblicken, så att datorer fortfarande kan känna igen handlingar som att laga mat, spela sport eller promenera en hund—samtidigt som de använder avsevärt mindre tid, minne och energi. Sådana framsteg kan bidra till att göra kraftfull videoanalys möjlig på vardagliga enheter, från hemrobotar till bärbara kameror.

Från oändliga bildrutor till nyckelögonblick
Traditionella system för videoklassificering försöker avgöra vad som händer i ett klipp—till exempel att hacka grönsaker eller skjuta en basketboll—genom att mata långa sekvenser av bildrutor till tunga djupinlärningsmodeller. Dessa modeller måste hantera både utseende (hur saker ser ut) och timing (hur de rör sig över tid). Att bearbeta alla bildrutor leder till stora datamängder, höga lagringskrav och långsam, energikrävande beräkning. Författarna menar att många av dessa bildrutor är överflödiga: om inget väsentligt förändras från en ruta till nästa får systemet liten nytta av att analysera båda. Kärn-idén i arbetet är att plocka ut en mycket mindre uppsättning "nyckelbilder" som ändå fångar de viktiga förändringarna i scenen.
Mäta förändring mellan bildrutor
För att hitta dessa nyckelögonblick utformar och jämför forskarna flera sätt att mäta hur mycket en bildruta skiljer sig från en annan. Istället för att enbart förlita sig på den klassiska Euklidiska distansen, som jämför alla pixlar jämnt, prövar de alternativ som är mer känsliga för strukturella förändringar. Deras huvudförslag, kallat "Norm of Rows"-avståndet, fokuserar på den största skillnaden över varje pixelrad och tar sedan den mest framträdande raden som mått på förändring mellan två bildrutor. De undersöker också kolumnbaserade avstånd och metoder baserade på egenvärden hos matriser som sammanfattar hur pixelskillnaderna sprids. Alla dessa tillvägagångssätt syftar till att bättre upptäcka meningsfull rörelse eller scenförändringar, såsom en hand som når efter ett redskap eller en spelare som hoppar.
Hur summeringspipelinens fungerar
Summeringsprocessen börjar med den allra första bildrutan i en video, som behandlas som den inledande nyckelbilden. Systemet jämför sedan denna nyckelbild med varje efterföljande ruta med hjälp av en av distansmåtten. När distansen når en topp över en vald tröskel markeras motsvarande ruta som en ny nyckelbild, vilket indikerar att något visuellt viktigt har förändrats. Proceduren upprepas sedan med denna nya nyckelbild som referens, och stegar genom videon för att samla en kedja av representativa ögonblicksbilder. Genom att justera tröskelvärdet kan metoden behålla så lite som 20 procent eller så mycket som 80 procent av de ursprungliga bildrutorna, vilket innebär en avvägning mellan kompakthet och detaljrikedom. Dessa summerade sekvenser skickas sedan till en standard djupinlärningsklassificerare som kombinerar ett kraftfullt bildernätverk (ResNet-50) med en tidskänslig LSTM-modul.
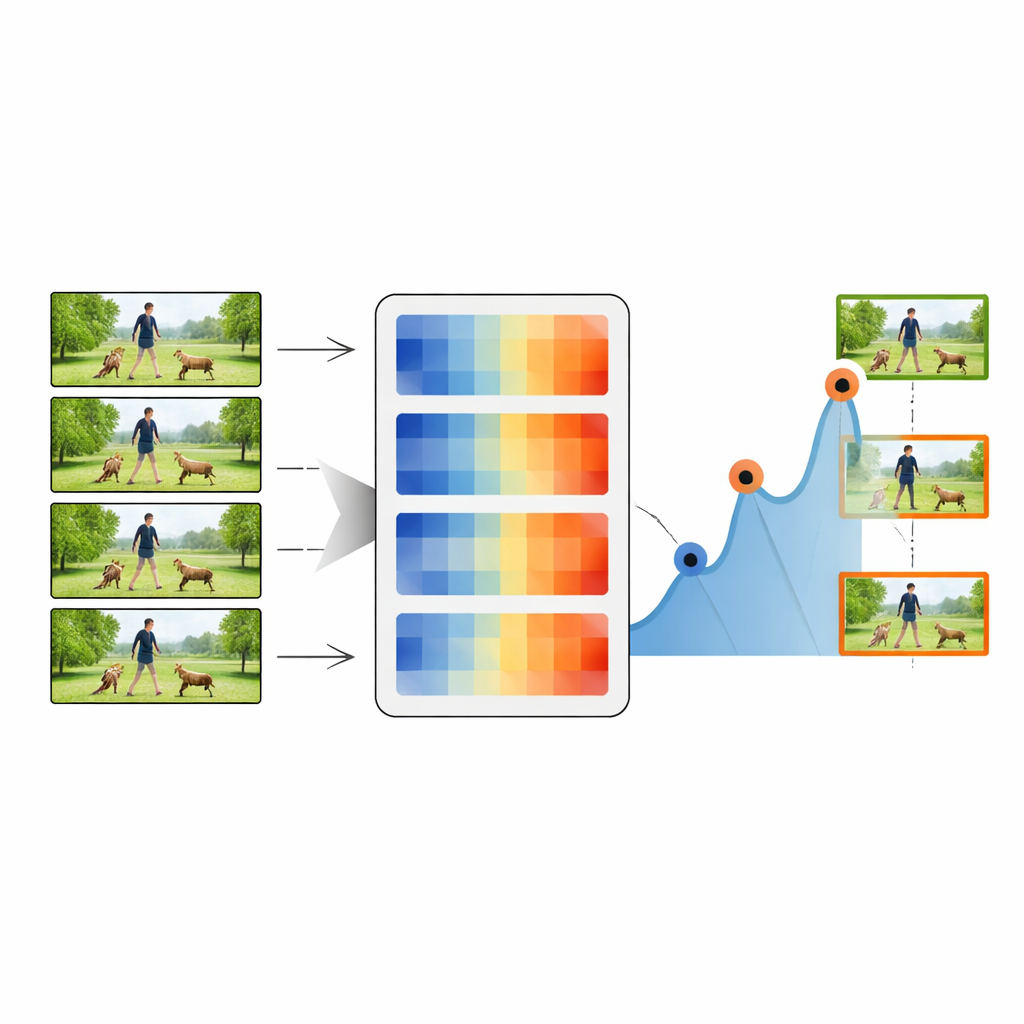
Sätta metoden på prov
Författarna utvärderar noggrant sitt tillvägagångssätt på fyra välkända videosamlingar: vardagliga köksaktiviteter (MMAC), sporter och allmänna handlingar (UCF101 och UCF11) och mer varierade, utmanande klipp (HMDB51). Över dessa benchmarks ger Norm of Rows-avståndet konsekvent den bästa balansen mellan hastighet och noggrannhet. Med bara omkring hälften av bildrutorna bevarade når deras system klassificeringsnoggrannheter över 90 procent på flera datamängder—ofta matchande eller överträffande mer komplexa metoder som använder fullständiga, osummerade videor. De mäter också hur väl summeringarna täcker det ursprungliga innehållet, hur redundanta de valda rutorna är och hur mångsidiga de fångade ögonblicken blir. Den föreslagna metriska uppnår hög täckning med låg redundans, vilket innebär att den bevarar videons berättelse utan att upprepa liknande rutor.
Snabbare beslut för verklig video
Genom att skära ner antalet bildrutor ungefär till hälften halverar metoden i stort sett bearbetningstiden på standarddatorhårdvara och ger fortfarande märkbara hastighetsförbättringar även på moderna grafikkort. För verkliga system som måste reagera i realtid—såsom övervakning, autonoma robotar eller mobilappar—är denna minskning av arbetsbelastningen avgörande. Studien visar att ett omsorgsfullt utformat distansmått kan fungera som en smart grindvakt, som väljer vilka bildrutor som förtjänar uppmärksamhet och vilka som säkert kan hoppas över.
Slutsats för vardagsanvändning
Enkelt uttryckt visar detta arbete att datorer inte behöver titta på varje enskild bildruta för att förstå vad som händer i en video. Genom att fokusera på de ögonblick då bilden verkligen förändras och bortse från nästan-duplicates behåller den föreslagna tekniken kärnan i en handling samtidigt som mängden data minskas drastiskt. Det gör högkvalitativ videoförståelse mer praktisk på begränsad hårdvara och öppnar dörren för snabbare, mer effektiva verktyg för att analysera den växande strömmen av visuella data i vår vardag.
Citering: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Nyckelord: videoklassificering, videosummering, val av nyckelbild, aktionsigenkänning, effektivitet i datorseende