Clear Sky Science · sv
Adaptiv suddig kluster‑styrd enkel, snabb och effektiv funktionsselektion för högdimensionella och starkt obalanserade binära bioinformatiska mikromatrisdata
Varför detta är viktigt för genforskning
Moderna genuttryckstester kan mäta tiotusentals gener i ett enda patientprov. Denna datamängd lovar tidigare cancerdiagnoser och bättre behandlingsval, men skapar också ett problem: de flesta av generna är brusiga, redundanta eller kopplade främst till vanliga fall snarare än de sällsynta och farliga. Denna artikel presenterar ett nytt sätt att sålla i massiva genuttrycksdatamängder så att datorer kan upptäcka patienter i en liten, svårupptäckt minoritetsgrupp på ett tillförlitligt sätt med hjälp av endast ett mycket litet, noggrant utvalt set av gener.
Utmaningen med för många, för lika gener
Mikromatrisexperiment följer ofta tusentals geners aktivitetsnivåer för bara några hundra patienter. Vanligtvis är en klass (till exempel en vanlig cancersubtyp) långt överrepresenterad jämfört med den andra, vilket skapar starkt obalanserade data. I detta läge uppvisar många gener mycket likartade beteenden, och mönstren för majoritets‑ och minoritetspatienter kan överlappa. Standardinlärningsmetoder tenderar att haka upp sig på majoritetsklassen och förvirras av redundanta gener, vilket leder till överanpassning och dålig upptäckt av sällsynta subtyper. Traditionella metoder för dimensionsreduktion offrar antingen tolkbarheten genom att bygga nya blandade funktioner, eller väljer gener utan att noga undersöka hur väl de hjälper en klassificerare att känna igen minoritetsfallen.
En ny färdplan för smartare genselektion
Författarna introducerar AFCG‑SFE, en adaptiv modell för funktionsselektion särskilt utformad för högdimensionella, obalanserade genuttrycksdata. Metoden börjar med en enkel "single‑agent"‑sökning som växlar gener på eller av och testar hur väl de stödjer klassificering, men förfinar denna med flera datadrivna steg. Först grupperas gener baserat på hur likartat de beter sig, och gener tillåts höra till mer än en grupp för att spegla den biologiska verkligheten att en gen kan vara involverad i flera vägar. Inom varje grupp rankas gener efter hur informativa de är om sjukdomsetiketten och man behåller bara några nyckelrepresentanter, vilket kraftigt minskar redundans innan huvudsökningen ens börjar. 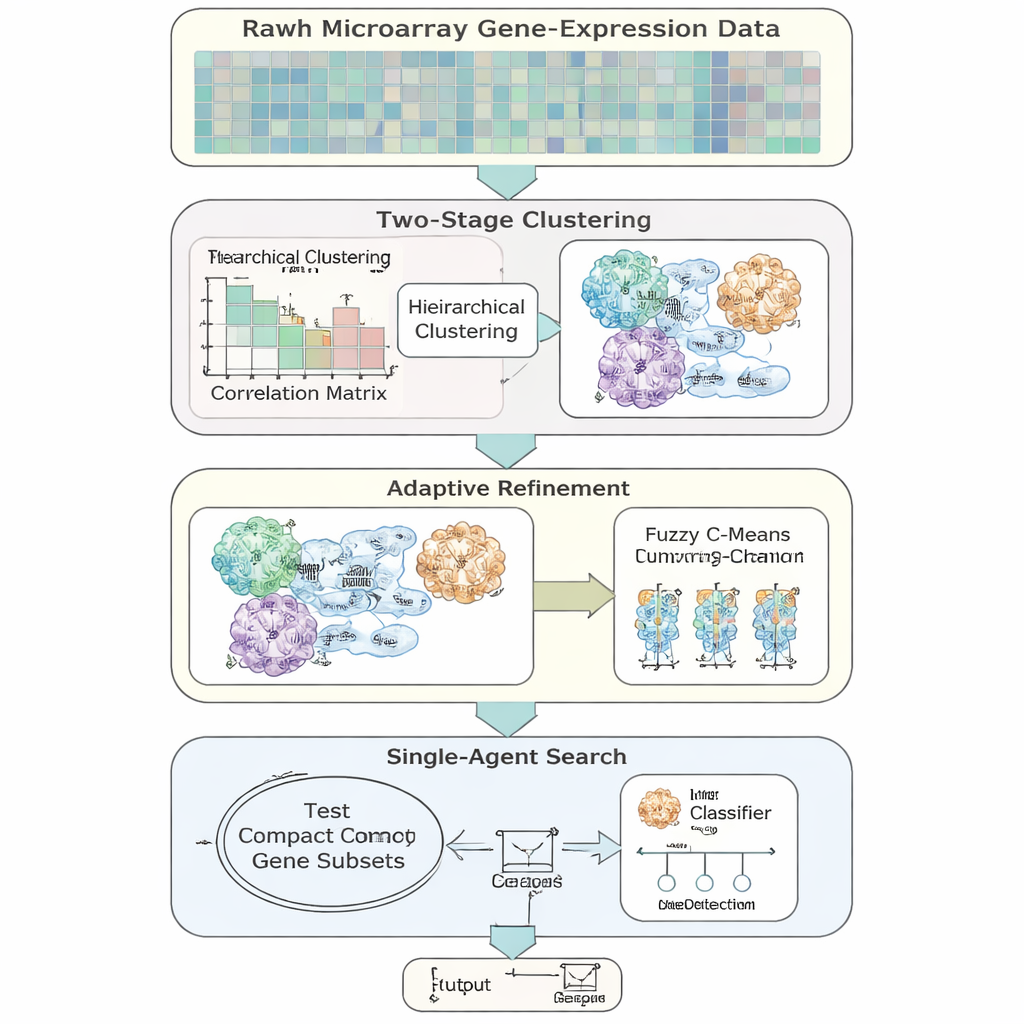
Få datorn att bry sig om sällsynta patienter
I stället för att fokusera på enkel noggrannhet använder AFCG‑SFE en fitness‑poäng som betonar mått lämpade för snedfördelade data, inklusive balansen mellan korrekt identifiering av minoritets‑ och majoritetsfall samt prestanda över alla beslutströsklar. Fitnessfunktionen inkluderar också straff för att välja för många gener eller många gener från samma kluster, och en belöning för gener som uppvisar stark beroende av sjukdomsetiketten. Viktigt är att styrkan i dessa straff och belöningar sätts automatiskt utifrån datasetets egenskaper, såsom hur många gener det finns per patient och hur mycket klasserna överlappar, i stället för genom manuell justering. Det gör metoden mer robust och lättare att överföra mellan studier.
Anpassning efter problemets svårighetsgrad
En central idé är att algoritmen inte alltid ska sikta på det minsta möjliga gensettet. När de två klasserna är mycket svåra att skilja åt eller kraftigt överlappar höjer metoden automatiskt en nedre gräns för hur många gener som måste behållas, vilket säkerställer att sällsynta men viktiga signaler inte slängs bort. När sökningen fortskrider stramar AFCG‑SFE gradvis åt ett per‑kluster‑tak för hur många gener som kan överleva från varje grupp, samtidigt som denna minimumgräns respekteras. Resultatet blir ett kompakt, diversifierat panel av gener som fångar datans struktur utan att domineras av ett enda, redundanta mönster. 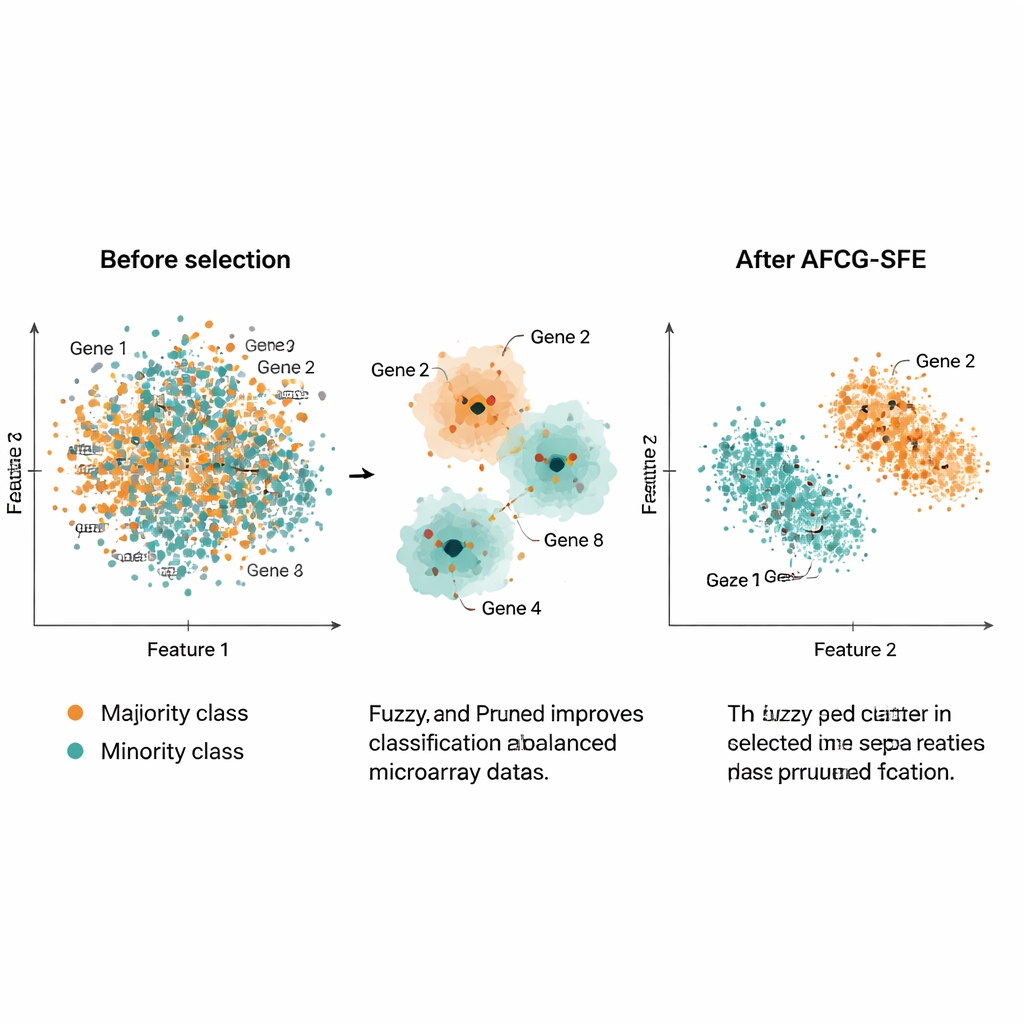
Vad experimenten visar
Författarna testade AFCG‑SFE på 20 offentliga cancer‑mikromatrisdataset, vardera med tusentals gener men bara cirka 100–200 prover och stark klassobalans. De jämförde sin metod med flera evolutionära sökbaslinjer, enkla filter och inbäddade tillvägagångssätt som bygger in funktionsselektion i klassificeraren. Över en rad mått — inklusive F‑mått, balanserad noggrannhet, area under ROC‑kurvan och ett mått på överanpassning — var AFCG‑SFE bäst eller delad bäst på alla dataset. Den valde typiskt färre än 25 gener (ofta så få som 6–8), och tog bort mer än 99 % av de ursprungliga funktionerna samtidigt som klassificeringsprestandan förbättrades eller bibehölls. Den minskade också ett komplexitetsindex som fångar hur mycket klasserna överlappar i funktionsutrymmet, vilket indikerar tydligare separation efter selektionen.
Slutsatsen för icke‑experter
I praktiska termer erbjuder detta arbete ett sätt att krympa enorma, brusiga genuttrycksprofiler till mycket små uppsättningar informativa gener som ändå låter datorer korrekt känna igen sällsynta patientundergrupper. Genom att intelligent gruppera liknande gener, belöna dem som verkligen följer sjukdomen och uttryckligen skydda mot bias mot majoritetsklassen levererar AFCG‑SFE både bättre prediktion och mycket enklare genpaneler. Den kombinationen kan hjälpa forskare att hitta potentiella biomarkörer, utforma mer tolkbara diagnostiska tester och i slutändan förbättra hur precisionmedicinska verktyg fungerar med verkliga, ofullkomliga biologiska data.
Citering: Tye, Y.W., Chew, X., Yusof, U.K. et al. Adaptive fuzzy cluster-guided simple, fast, and efficient feature selection for high-dimensional and highly imbalanced binary-class bioinformatics microarray data. Sci Rep 16, 6650 (2026). https://doi.org/10.1038/s41598-026-37086-w
Nyckelord: genuttryck, funktionselektion, obalanserade data, mikromatris, cancersubtyper