Clear Sky Science · sv
Uppbyggnad och tillämpning av kunskapsgraf för dokument om frökvalitetsstandarder
Varför fröregler spelar roll för allas mat
Bakom varje påse ris eller förpackning med grönsaksfrön döljer sig en labyrint av tekniska standarder som tyst skyddar skördarna och livsmedelssäkerheten. Dessa regler för frökvalitet ligger emellertid ofta begravda i täta PDF-dokument som är svåra för odlare, tillsynsmyndigheter och företag att söka i eller tolka. Denna studie visar hur man kan förvandla dessa statiska dokument till en levande ”karta” av sammanlänkade fakta — en kunskapsgraf — som gör jordbruksstandarder mer transparenta, sökbara och redo för den digitala jordbrukseran. 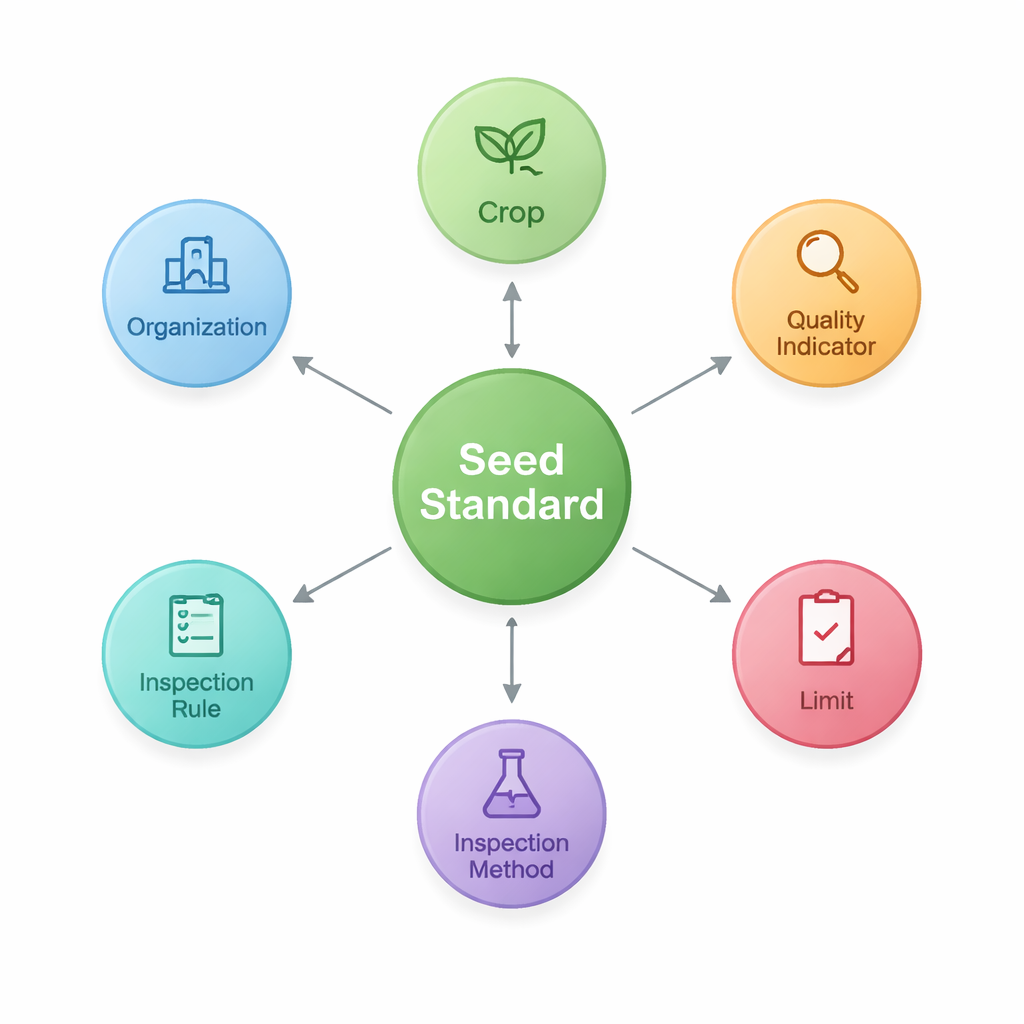
Från pappersstandarder till smart information
Frökvalitetsstandarder beskriver vad som räknas som acceptabelt frö: hur ren satsen måste vara, hur många frön som ska gro, hur mycket fukt som är tillåtet och vilka metoder som används för att testa dessa egenskaper. I Kina har antalet sådana dokument exploderat, och många finns fortfarande endast som skannade sidor eller ostrukturerad text. Enkel sökning efter nyckelord har svårt att svara på praktiska frågor som ”Vilka är renhetsgränserna för denna gröda?” eller ”Vilken regel ersatte en äldre?”. Författarna menar att för att hålla jämna steg med snabba förändringar i jordbruket måste dessa standarder övergå från människoläsbara sidor till maskinförståelig kunskap som kan stödja snabba frågor, jämförelser och automatiska kontroller.
Att bygga en karta över frökunskap
För att nå detta designar forskarna först en ”ontologi” — en gemensam ritning som definierar huvudbyggstenarna i frökvalitetsstandarder och hur de hör samman. De identifierar sju kärntyper av objekt, inklusive själva standarden, den gröda den omfattar, kvalitetsindikatorer som renhet eller grobarhet, de numeriska gränserna för dessa indikatorer, inspektionsmetoder och regler samt organisationerna som utarbetar eller publicerar dokumenten. Denna struktur fångar mönster som ”Gröda–Kvalitetsindikator–Gräns”, vilka är särskilt viktiga inom jordbruket. Med denna ritning lagrar de sedan de extraherade fakta som noder och länkar i en grafdatabas (Neo4j), och skapar ett nätverk av 2 436 enheter sammanbundna av 3 011 relationer.
Kombinera regler och maskininlärning
Den verkliga utmaningen är att extrahera rena, tillförlitliga fakta ur röriga källdokument. Fröstandarder blandar prydligt formaterade tabeller, stela metadata på framsidan och långa, löpande textstycken. Ingen enskild teknik hanterar allt detta väl. Teamet bygger därför ett hybridutvinningssystem. De använder precisa regelmönster (regular expressions) för att läsa strukturerade tabeller och grundläggande dokumentinformation, som ofta följer strikta format. För den mer komplexa narrativa texten — såsom detaljerade inspektionsregler — tränar de en modern språkmodellspipeline kallad BERT–BiLSTM–CRF för att känna igen viktiga namn, koder och tekniska uttryck. Denna modell lär sig från noggrant märkta exempel och kan hitta entiteter även när de förekommer i varierande formuleringar och långa meningar. 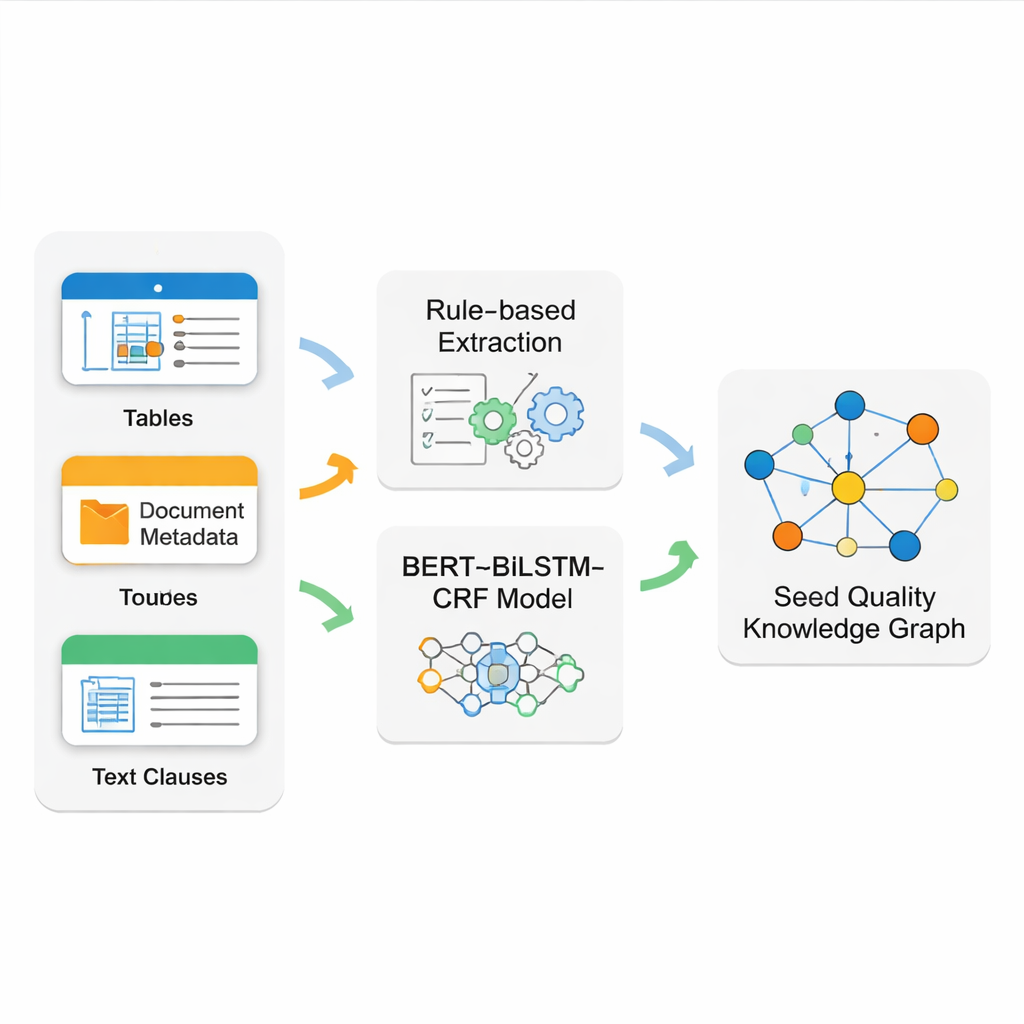
Hur väl systemet fungerar i praktiken
När det testas presterar den hybrida metoden starkt. Språkmodellen uppnår ett totalt F1-värde (en balans mellan korrekthet och fullständighet) på omkring 91,6 %, vilket slår två vanligt använda baslinjemodeller. Den är särskilt bra på att hitta strukturerade element som standardkoder och håller måttet även i svårare uppgifter som långa inspektionsregler. När all denna information väl är inläst i kunskapsgrafen kan användare visuellt utforska hur en viss standard relaterar till tidigare versioner, vilka organisationer som utarbetat den, vilka grödor och indikatorer den omfattar och vilka provningsmetoder den föreskriver. Istället för att bläddra igenom långa PDF-filer kan tillsynsmyndigheter och fröföretag göra riktade sökningar och se sammanlänkade resultat på några sekunder.
Vad detta betyder för odlare och livsmedelssystem
För icke-specialister är resultatet ett smartare sätt att hantera de regler som håller frön tillförlitliga och grödor produktiva. Studien visar att genom att kombinera tydlig konceptuell design med både regelbaserad och lärandebaserad extraktion är det möjligt att förvandla spridda frökvalitetsstandarder till en sammanhållen, sökbar kunskapsbas. Detta lägger teknisk grund för ”SMARTA” standarder som datorer kan läsa, korsgranska och uppdatera när regler ändras. På sikt kan sådana verktyg hjälpa bönder och jordbruksföretag att snabbt bekräfta om frön uppfyller gällande kvalitetskrav, stödja tillsynsmyndigheter i att spåra revideringar och luckor och bidra till mer stabila skördar och livsmedelssäkerhet.
Citering: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Nyckelord: frökvalitetsstandarder, kunskapsgraf, jordbruksdigitalisering, namngiven enhetsigenkänning, smarta standarder