Clear Sky Science · sv
Kunnskapsförankrad stor språkmodell för generering av personliga träningsprogram
Smartare träningsprogram för vanliga människor
De flesta träningsappar lovar personliga program, men många förlitar sig fortfarande på generiska mallar som bortser från hur din kropp faktiskt mår. Denna artikel presenterar LLM-SPTRec, ett nytt system som använder samma typ av stora språkmodeller som moderna chattbotar, kombinerat med granskad idrottsvetenskaplig kunskap och data från bärbara enheter, för att skapa säkrare och mer effektiva träningsprogram. För den som undrat varför appen fortsätter föreslå fel övningar — eller oroat sig för om AI‑framställda hälsoråd verkligen är säkra — visar detta arbete hur digital coaching kan bli både mer personlig och mer vetenskaplig.
Varför traditionella träningsappar brister
Konventionella rekommendationsmotorer, som dem som föreslår filmer eller produkter, har svårt när de appliceras på träning. De kopierar ofta standardmallar, har problem med begränsade data för nya användare och tar sällan hänsyn till hur din kropp förändras från dag till dag. Värre är att de inte är utformade för beslut där säkerhet är avgörande. Allmänna språkmodeller är bra på att prata om träning, men eftersom de tränas på brett internetinnehåll kan de “hallucinera” riskfyllda råd eller förbise viktiga vilodagar. Författarna menar att för träningsplanering — där dålig vägledning kan orsaka skador eller överträning — måste AI vara förankrad i verifierad idrottsvetenskap och följa en persons förändrade tillstånd över tid.
Att bygga en rik bild av individen
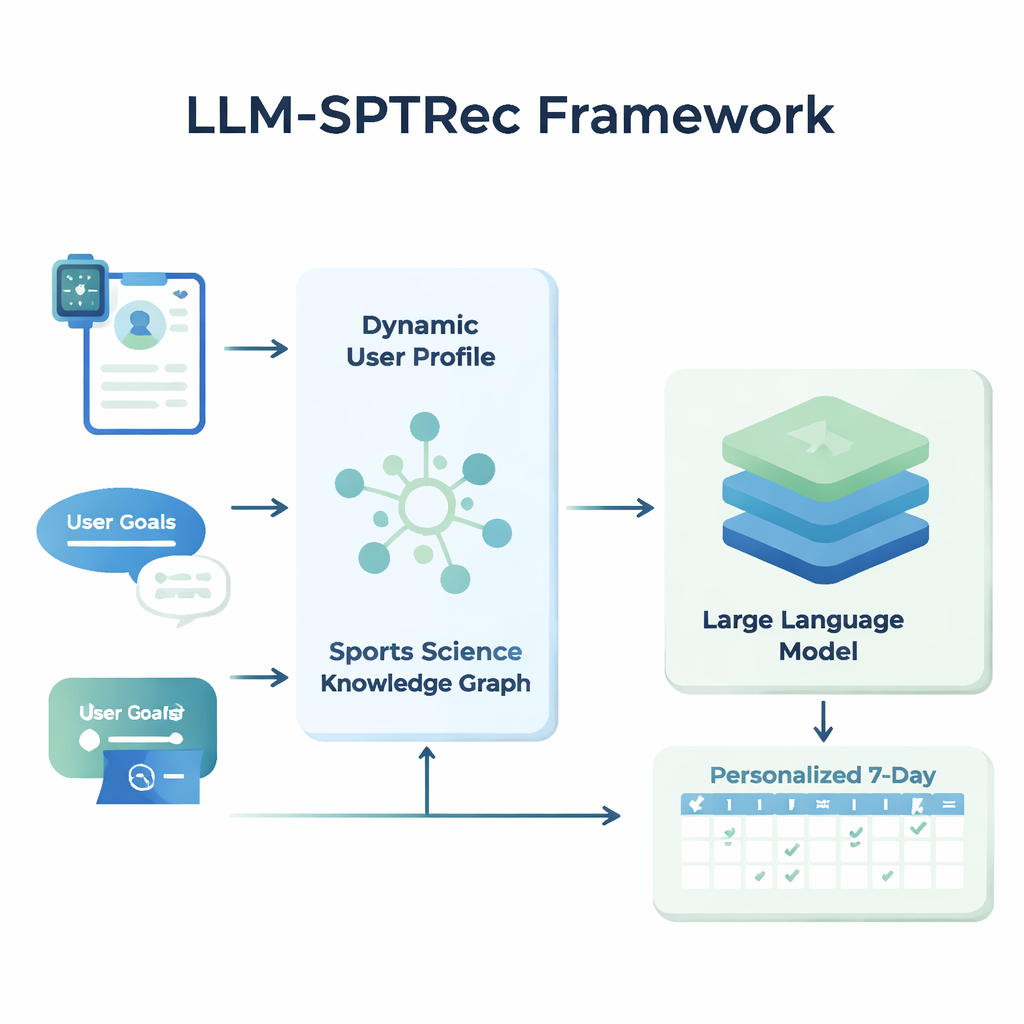
I kärnan av LLM-SPTRec finns en modul som skapar en detaljerad ögonblicksbild av varje användare. Istället för att bara spara ålder, kön eller erfarenhetsnivå sammansmälter systemet tre typer av information: statiska egenskaper (såsom träningshistoria), dynamiska signaler (som hjärtfrekvens, hjärtfrekvensvariation, sömnpoäng och tidigare träningar från wearables och loggar) samt fria textmål skrivna av användaren. En transformerbaserad modell — besläktad med tekniken bakom moderna språkmodeller — lär sig mönster i dessa tidsseriedata, exempelvis hur ett tufft pass igår kan påverka dagsform idag. En attention‑mekanism väger sedan vilka signaler som är viktigast i ett givet ögonblick och kombinerar dem till en enda numerisk representation av användarens aktuella tillstånd.
Att lära AI verklig idrottsvetenskap
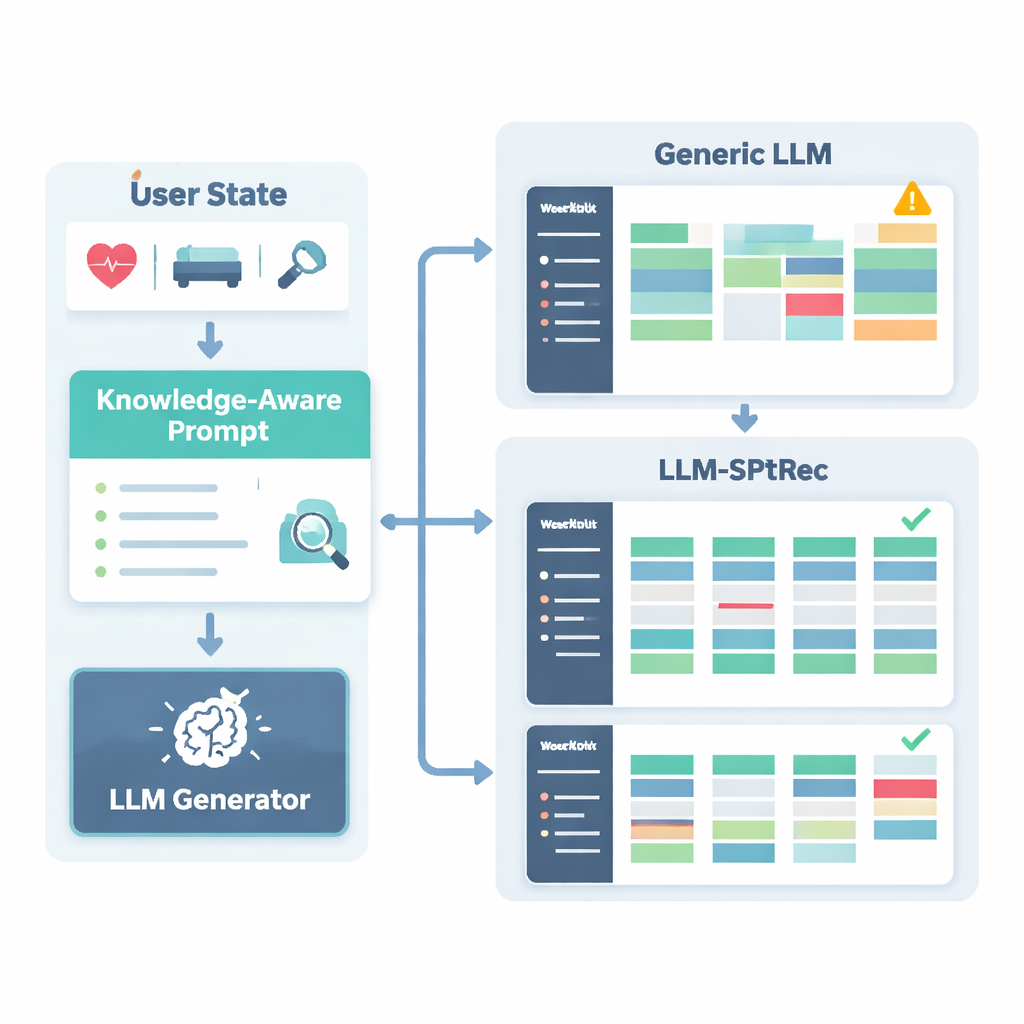
För att förhindra osäkra eller ovetenskapliga rekommendationer byggde forskarna en Sports Science Knowledge Graph, i praktiken en strukturerad karta över expertgranskade fakta. Den innehåller tusentals poster som länkar övningar till muskler, rörelsetyper, utrustning, vanliga skador och träningsprinciper som progressiv överbelastning och specificitet. För varje användare hämtar systemet de mest relevanta delarna av denna graf — till exempel vilka muskler bänkpress tränar och vilka rörelser som är olämpliga vid axelproblem — och omvandlar dem till läsbar text som matas in i språkmodellen tillsammans med användarprofilen. Språkmodellen uppmanas sedan, via en noggrant utformad prompt, att generera ett flerdagars träningsprogram i ett strukturerat format och följa regler som att rotera muskelgrupper mellan dagarna och undvika kända kontraindikationer.
Hålla program strukturerade, säkra och förbättrade över tid
LLM-SPTRec gör mer än att bara generera text. En valideringsmodul kontrollerar varje program mot hårda regler, såsom att inte överbelasta samma primära muskelgrupper dag efter dag, och flaggar konflikter med skadrisker som lagras i kunskapsgrafen. Om ett program misslyckas med dessa kontroller uppmanar systemet modellen igen och pekar uttryckligen ut vad som gick fel, tills ett säkert program produceras. Träningen av systemet sker också i två steg. Först lär det sig från en stor samling expertutformade program. Därefter finslipas det med hjälp av återkoppling, där simulerade eller verkliga användarbetyg belönar program som är koherenta, i linje med mål och tillfredsställande att följa, medan osäkra förslag straffas hårt. Denna återkopplingsslinga styr modellen mot rekommendationer som fungerar bättre i praktiken.
Hur väl systemet fungerar i praktiken
Författarna testade LLM-SPTRec på en stor, verklig dataset kallad SportFit-1M, som kombinerar anonymiserade data från träningsappar och bärbara enheter och täcker tiotusentals användare samt miljontals träningsloggar och fysiologiska poster. De jämförde sitt system med starka baslinjer: klassisk kollaborativ filtrering, en sekvensmodell som bara ser tidigare val, en avancerad kunskapsgrafrekommendator och ett ramverk baserat på en allmän språkmodell. LLM-SPTRec slog alla dessa inte bara när det gällde att välja lämpliga övningar, utan — viktigare — vid framställandet av kompletta program som experter bedömde som mer koherenta och mer i linje med användarnas mål. Förutsagda användarnöjdhetspoäng var också högre, och en liten mänsklig studie med certifierade tränare bedömde dess säkerhet betydligt bättre än en allmän språkmodell utan idrottsspecifik förankring.
Vad detta betyder för framtida digital coaching
För en lekmannamässigt intresserad är slutsatsen att smartare, säkrare AI‑coaching är möjlig när tre ingredienser kombineras: rik data från dina enheter, expertkunskap inom idrottsvetenskap kodad som strukturerad kunskap och kraftfulla språkmodeller vars kreativitet noggrant styrs och kontrolleras. LLM-SPTRec visar att en sådan kombination kan generera adaptiva, dag‑för‑dag‑program som respekterar din kropps förändrade tillstånd och dina personliga mål, samtidigt som risken för skadliga eller nonsensartade råd minskas. Framöver skulle samma recept kunna sträcka sig bortom träning till näring, rehabilitering eller till och med mental hälsa, och peka mot en framtid där AI‑assistenter beter sig mindre som generiska chattbotar och mer som kunniga, säkerhetsmedvetna digitala coacher.
Citering: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Nyckelord: personlig träning, idrottsvetenskap AI, fitnessrekommendation, bärbara enheter data, kunskapsgraf