Clear Sky Science · sv
Utvecklingen av objektdetektion från CNN:er till transformatorer och multimodal fusion
Lära datorer att se vardagliga föremål
Varje gång din telefon taggar vänner på ett foto, en bil upptäcker en fotgängare eller ett läkarverktyg markerar en tumör på en skanning, arbetar en tyst men kraftfull teknik i bakgrunden: objektdetektion. Denna översiktsartikel förklarar hur objektdetektion snabbt har utvecklats under det senaste decenniet, från tidiga bildbehandlingsknep till dagens transformatorbaserade och flersensorsystem, och varför dessa framsteg är viktiga för säkrare gator, smartare robotar och mer precisa medicinska diagnoser.
Från pixlar till igenkännbara ting
Objektdetektion är uppgiften att hitta och märka specifika objekt i bilder eller video—bilar, cyklister, djur, medicinska strukturer med mera. Artikeln börjar med att kartlägga hur brett denna förmåga används: i självkörande fordon, övervakning, medicinsk bildbehandling och robotik. Tidiga system förlitade sig på handgjorda regler för att plocka ut former och texturer, men moderna metoder lär sig direkt från data med hjälp av djuplärande. Två breda familjer dominerar nu: konvolutionella neurala nätverk (CNN:er), som är mycket bra på att upptäcka lokala mönster som kanter och hörn, och transformatorer, som utmärker sig i att förstå den bredare scenen och relationer mellan avlägsna objekt. Tillsammans definierar de hur dagens maskiner ”ser” världen.
Hur klassiska visionsmotorer fungerar
CNN-baserade metoder driver fortfarande många applikationer i realtid. De skannar bilder med små filter för att bygga upp rikare och rikare feature-kartor, och matar sedan dessa till detektionshuvuden som ritar ut begränsande rutor och tilldelar etiketter. Översikten förklarar två huvudstrategier. Tvåstegssystem som Faster R-CNN föreslår först troliga objektregioner och förfinar dem sedan, vilket ofta ger hög noggrannhet till en beräkningskostnad. Enstegs-system som YOLO-familjen hoppar över förslagssteget och förutser rutor och etiketter i ett enda pass, vilket byter lite noggrannhet mot hastighet. Nyare versioner som YOLOv5 och YOLOv8 har finslipats—med smartare feature-pyramidstrukturer för små objekt, lätta byggstenar för kant-enheter och förbättrade förlustfunktioner—för att nå hundratals bildrutor per sekund samtidigt som de förblir konkurrenskraftiga på tuffa benchmarktest.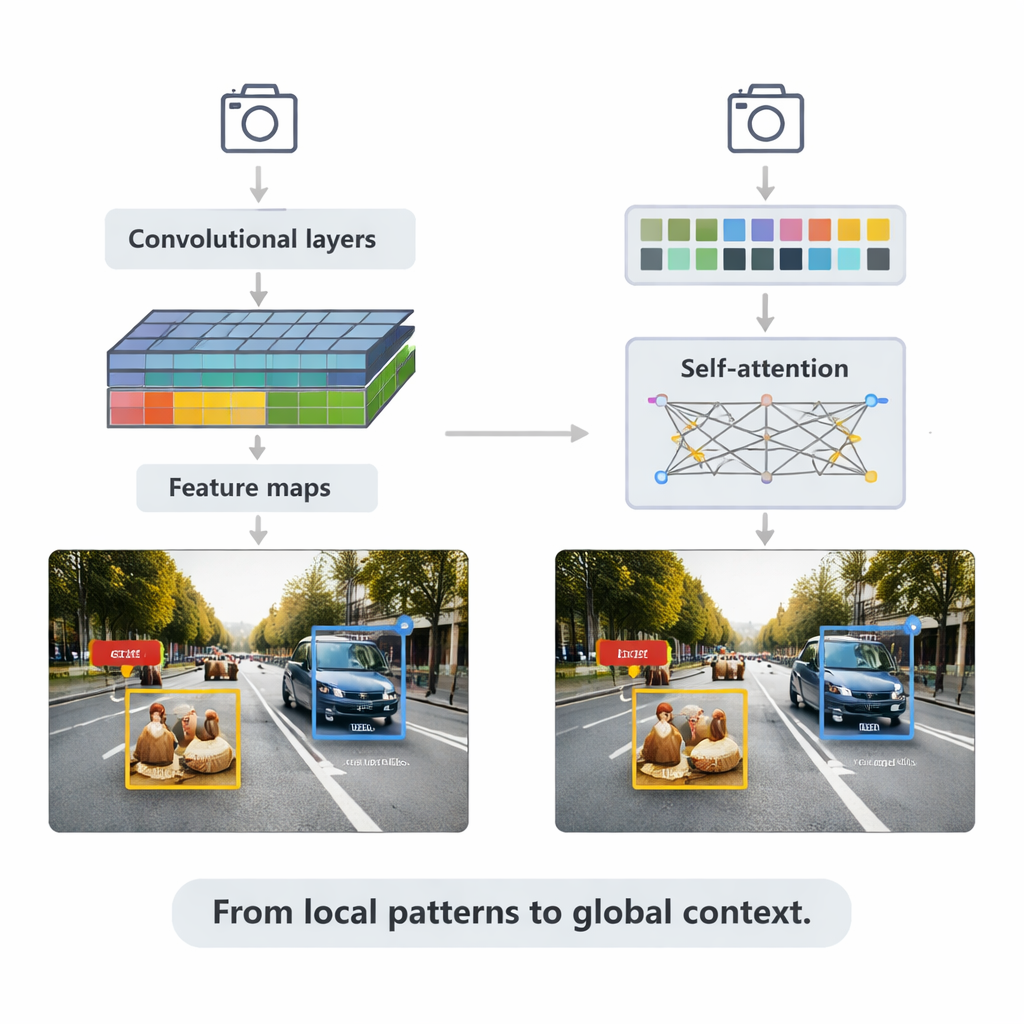
Transformatorer och kontextens kraft
Artikeln vänder sig sedan till transformatorer, en nyare arkitektur lånad från språkmodeller. Istället för att bara fokusera på lokala omgivningar använder transformatorer "self-attention" för att jämföra varje bildplätt med varje annan plätt, och lär sig vilka regioner som är mest relevanta för varje beslut. Detection Transformer (DETR) och dess efterföljare tar bort många handdesignade trick med målet att skapa renare, end-to-end-pipelines. Varianter som Deformable DETR och RT-DETR minskar beräkningen och förbättrar träningshastigheten, vilket gör att transformatorer kan köras i realtid samtidigt som de uppnår några av de högsta noggrannhetspoängen på det vida använda COCO-benchmarket. Dessa modeller lyser särskilt i komplexa scener med överlappande objekt och förvirrande bakgrunder, där global kontext hjälper att skilja till exempel en fotgängare som delvis döljs bakom en bil.
Att blanda kameror, laser och språk
Verkliga förhållanden—dimma, mörker, bländning, rörighet—överlistar ofta sensorsystem som bara har en källa. En stor fokuspunkt i översikten är multimodal fusion: att kombinera data från vanliga kameror (RGB), depthsensorer som LiDAR, termiska kameror och till och med textbeskrivningar. Författarna introducerar en tydlig taxonomi för hur denna sammansmältning kan ske: tidig fusion blandar rådata i början, mellanfusion slår ihop inlärda features inne i nätverket, och sen fusion kombinerar separat detektorsutdata i slutet. Moderna ”fusion-transformatorer” använder attention-mekanismer för att alignera dessa strömmar, så att skarpa avståndsmätningar från LiDAR, rik utseendeinformation från RGB-bilder och semantiska ledtrådar från språk stärker varandra. Detta tillvägagångssätt förbättrar detektionen i självkörande fordon, medicinsk bildbehandling, videoförståelse och texttunga scener.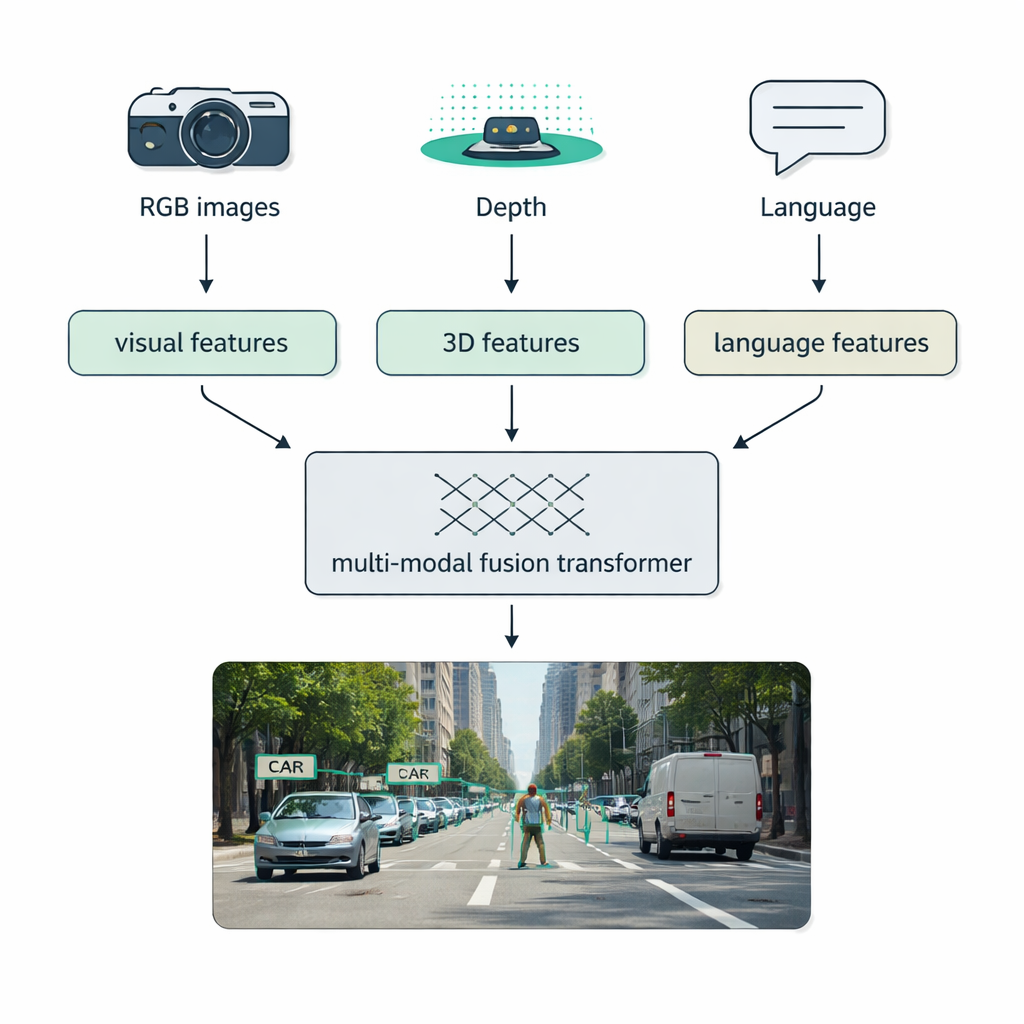
Benchmarks, begränsningar och vad som kommer härnäst
Över standardtester som MS COCO jämför översikten CNN- och transformatorbaserade detektorer både vad gäller noggrannhet och hastighet. Klassiska tvåstegs-CNN:er förblir starka men är långsammare, YOLO-liknande modeller dominerar på lättviktig hårdvara, och transformatorbaserade system leder nu i noggrannhet samtidigt som de stänger hastighetsgapet. Specialiserade infraröda metoder uppnår mycket höga poäng i låg-synlighetssituationer. Ändå kvarstår svåra problem: mycket små eller extremt stora objekt, kraftig ocklusion, skiftande väder och belysning, samt behovet av att köra pålitligt på små enheter. Framöver lyfter författarna fram trender mot enhetliga perceptionsmodeller som hanterar detektion, segmentering och bildtextning tillsammans, och ”foundation models” som förenar syn och språk för att känna igen objekt som beskrivs i klartext, även om de aldrig var märkta i träningsdata.
Varför detta spelar roll i vardagen
För icke-specialister är huvudbudskapet att objektdetektion rör sig från snäva, handanpassade system mot flexibla, allmänna visionsmotorer som kan anpassa sig till nya uppgifter, nya miljöer och nya sensorer. CNN:er ger snabb, effektiv mönsterigenkänning; transformatorer tillför en mer global, kontextmedveten förståelse; och multimodal fusion knyter in extra ledtrådar från djup, temperatur och språk. Tillsammans lovar dessa framsteg fordon som bättre förutser faror, verktyg som hjälper läkare med större säkerhet och hemheter som interagerar säkrare och smartare med sin omgivning—vilket för maskinperception närmare det rikade i mänskligt seende.
Citering: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Nyckelord: objektdetektion, datorseende, djuplärande, transformatormodeller, multimodal fusion