Clear Sky Science · sv
En referensram för att utvärdera effektiviteten i diagnostiska frågor från LLM i patientkonversationer
Varför smartare medicinska frågor spelar roll
När du besöker en läkare kommer den första diagnosen sällan från ett enda symtom du nämner. Istället ställer läkare en serie följdfrågor — om tidpunkt, intensitet, relaterade problem — för att gradvis begränsa vad som kan vara fel. Trots hur kraftfulla dagens AI‑system är testas de flesta fortfarande som om de skrev flervalsprov, inte som om de pratade med verkliga människor. Denna artikel presenterar Q4Dx, ett nytt sätt att bedöma hur väl stora språkmodeller (LLM) kan spela den ”nyfikna läkaren”: välja rätt frågor, i rätt ordning, för att effektivt nå rätt diagnos.
Från tentafrågor till verkliga samtal
De flesta befintliga medicinska AI‑tester ger modeller prydliga, fullt specificerade fall — som ett läroboksexempel — och ber dem välja en diagnos. Det visar vad systemet ”vet”, men inte hur det skulle bete sig i ett rörigt, verkligt samtal med en patient som glömmer detaljer eller beskriver symtom i vardagligt språk. Författarna menar att detta är en allvarlig blind fläck. På kliniker kommer information långsamt och ofta ofullständigt; en skicklig klinikers förmåga ligger lika mycket i vad de frågar som i vad de redan kan. Q4Dx är utformat för att stänga denna lucka genom att flytta fokus från statiska frågesvar till strategin att ställa frågor över tid.
Att bygga livlika patientberättelser
För att skapa denna nya testmiljö utgår forskarna från en kurerad medicinsk resurs som kopplar specifika sjukdomar till karakteristiska symtomuppsättningar. De väljer slumpmässigt 100 sådana sjukdom‑symtompar och använder sedan en AI‑modell för att förvandla sterila symtomlistor till naturligt klingande patientsjälvbeskrivningar — berättelser som en person faktiskt skulle kunna säga i en klinik. Från varje fullständigt fall genererar de kortare versioner där endast omkring 80 procent eller 50 procent av nyckelsymtomen nämns. Denna kontrollerade ”gömning” av information låter dem studera hur väl olika modeller anpassar sig när viktiga ledtrådar saknas eller bara antyds. Kontroller av symtomöverlap bekräftar att de kortare versionerna faktiskt innehåller mindre användbar information, inte bara färre ord.
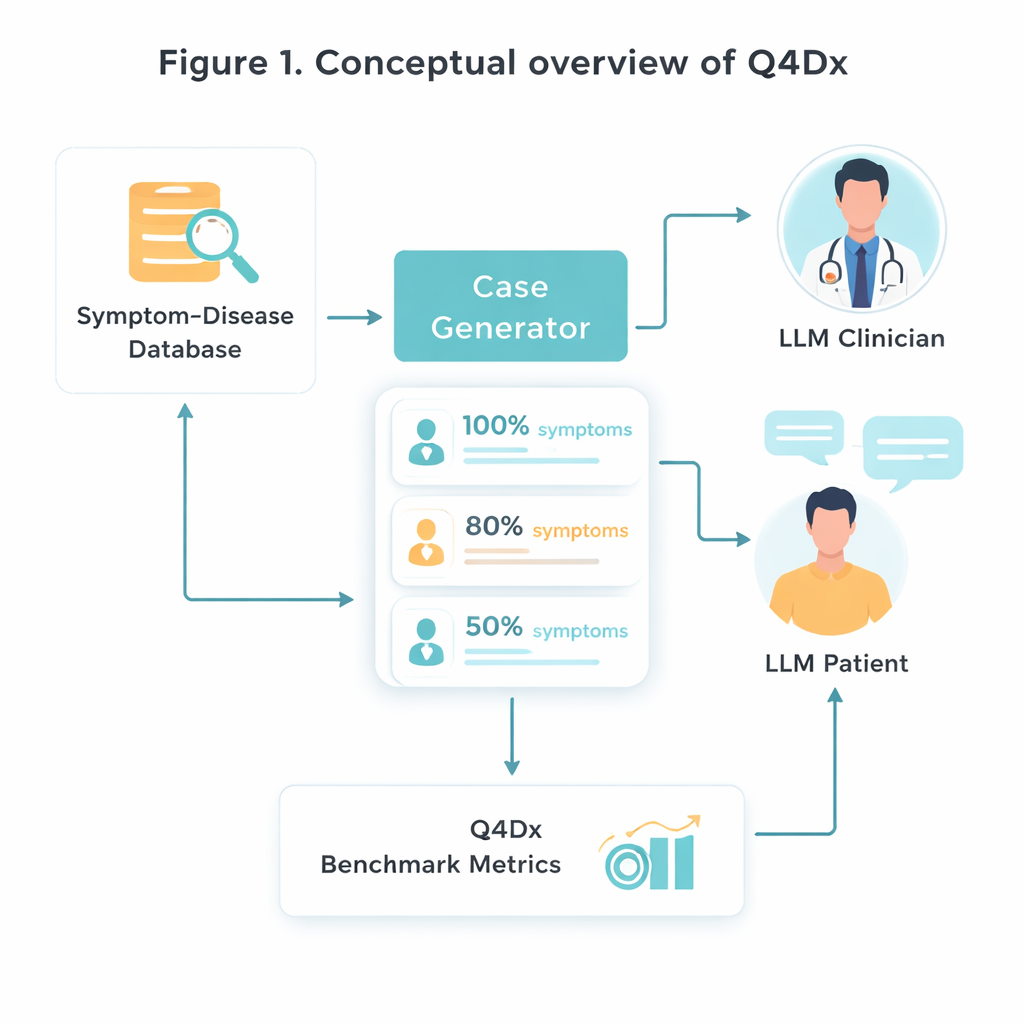
Simulerade läkare–patient‑dialoger
Kärnan i Q4Dx är en stor samling simulerade konversationer mellan två AI‑agenten. Den ena spelar patientrollen, med full tillgång till den underliggande sjukdomen och dess kompletta symtomuppsättning. Den andra agerar läkare: den ser endast en partiell, möjligen vag fallbeskrivning i början och måste bestämma vad den ska fråga härnäst. Efter varje patientsvar gör läkaren en preliminär diagnos och skapar en steg‑för‑stegspårning av hur dess resonemang utvecklas. Genom att spela in alla frågor, svar och mellanliggande gissningar fångar benchmarket inte bara om modellen har rätt, utan hur den kommer fram dit. Dessa AI‑genererade frågesekvenser används som referensstrategier — inte som perfekt medicinsk sanning, utan som ett konsekvent mått mot vilket framtida modeller och till och med mänskliga praktikanter kan jämföras.
Mäta bra frågor, inte bara rätt svar
För att bedöma prestanda utformar författarna tre enkla men kompletterande mått. Zero‑Shot Diagnostic Accuracy (ZDA) frågar: om du ger modellen hela fallet direkt, kan den omedelbart namnge rätt sjukdom? Mean Questions to Correct Diagnosis (MQD) speglar effektivitet: i genomsnitt hur många patientfrågor behöver modellen innan den först landar på rätt diagnos, med en gräns på fem? Slutligen undersöker Interrogation Sequence Efficiency (ISE) kvaliteten på själva frågestigen — hur lika modellens valda frågor är i betydelse jämfört med referenssekvensen. Med dessa mått visar teamet att en stark allmänmodell (GPT‑4.1) diagnostiserar korrekt ungefär hälften av gångerna med fullständig information, men att dess noggrannhet sjunker när symtom döljs. Samtidigt lyckas dess interaktiva sessioner vanligen efter bara några välvalda frågor, och dess frågor blir mer i linje med expertlika strategier över påföljande omgångar.

Vad detta betyder för framtidens medicinska AI
För icke‑specialister är budskapet enkelt: i medicin är det lika viktigt att ställa smarta frågor som att ha rätt svar, och AI behöver utvärderas på båda. Q4Dx erbjuder en återanvändbar, offentligt tillgänglig ram för just detta. Genom att tillhandahålla realistiska patientberättelser med varierande mängd saknad information, detaljerade samtalsspår och tydliga mått på både noggrannhet och effektivitet, låter benchmarket forskare jämföra olika AI‑system och till och med ställa dem mot mänskliga kliniker under kontrollerade förhållanden. Med tiden kan verktyg som Q4Dx hjälpa till att träna säkrare, mer pålitliga kliniska assistenter och förbättra hur läkare och studenter lär sig diagnostisk intervju teknik — i slutändan stödja bättre vård för verkliga patienter.
Citering: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Nyckelord: medicinsk AI, diagnostiskt resonerande, klinisk dialog, stora språkmodeller, frågestrategi