Clear Sky Science · sv
Benchmarking av handlingsigenkänningsmodeller för upptäckt av självskada i studi- och verklighetsdataset
Vaccinerande blickar över patienter med digitala ögon
I psykiatriska sjukhus arbetar sjuksköterskor outtröttligt för att hålla patienterna säkra, särskilt dem som riskerar att skada sig själva. Ändå kan inte ens den mest engagerade personalen övervaka varje rum, varje sekund. Denna studie undersöker om artificiell intelligens (AI) kan hjälpa genom att automatiskt skanna video från avdelningskameror för att upptäcka tidiga tecken på självskada—och därigenom erbjuda ett extra skyddsskikt utan att ersätta den mänskliga vården.
Varför självskada är så svårt att fånga
Självskada—alla avsiktliga skador som människor åsamkar sig själva—sker ofta i korta, dolda ögonblick: en snabb rispa under en filt eller ett litet verktyg som används ur sikte. Psykiatriska avdelningar förlitar sig på regelbundna kontroller och kamerabevakning, men döda vinklar, personalutmattning och begränsad bemanning nattetid eller under helger gör ständig vaksamhet omöjlig. Samtidigt väcker inspelning och delning av verkligt patientmaterial allvarliga integritets- och etiska frågor. Följaktligen har forskare haft mycket lite realistiskt videomaterial att träna AI-system på som skulle kunna upptäcka farligt beteende i realtid.
Bygga säkrare testmiljöer för AI
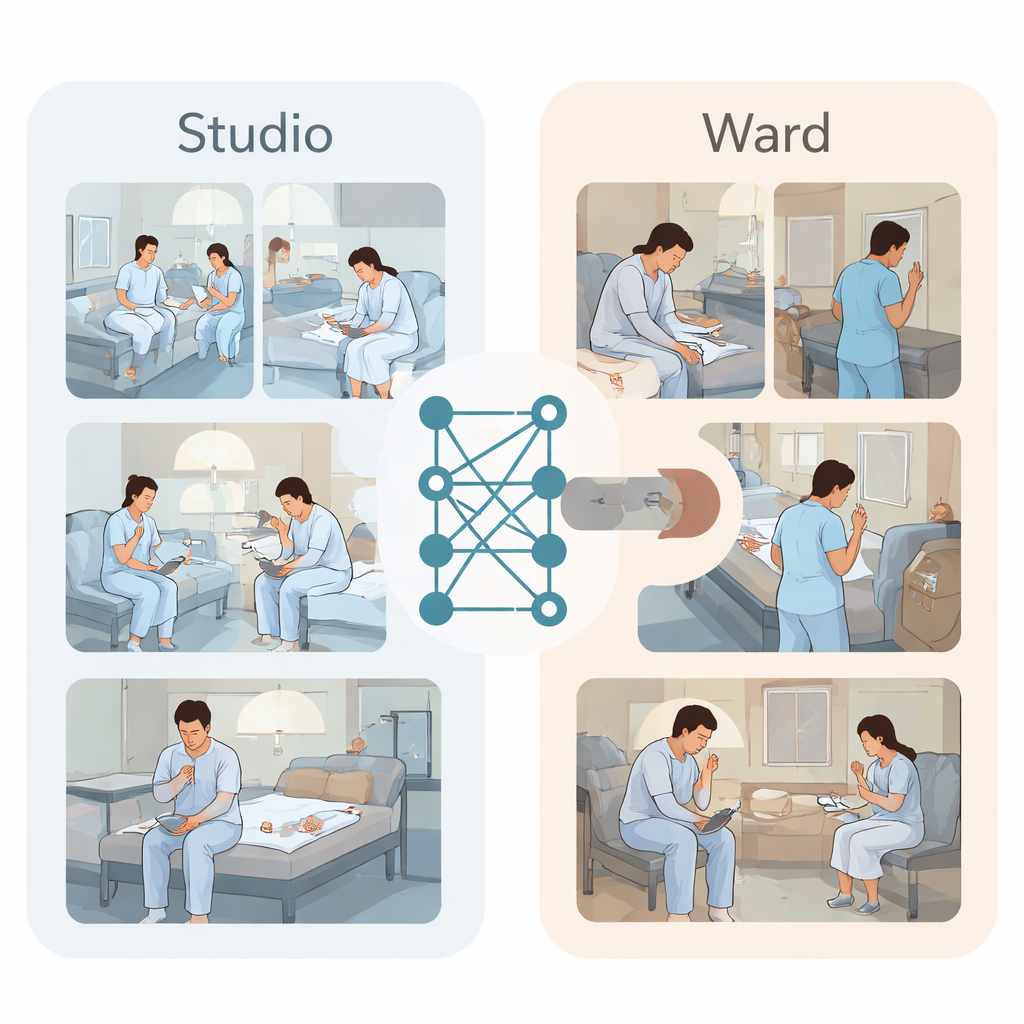
För att bryta denna återvändsgränd skapade forskarna två typer av videodatamängder. Först, i en studio utformad som ett fyrabäddsrum på en psykiatrisk avdelning, utförde sju unga skådespelare i patientkläder noggrant planerade scener. De letade efter vardagsföremål som plastkorkar, läppbalsamtuber eller små spikar och iscensatte korta sekvenser av självskadande rörelser på handleden, underarmen eller låret, medan övervakningskameror filmade från alla hörn. Experter märkte upp varje videosegment som antingen normalt beteende eller självskada och byggde därmed en ren, balanserad samling på 1120 klipp. Sedan samlade teamet verkliga övervakningsfilmer från slutna psykiatriska avdelningar under tio månader. Kliniker sökte i journalanteckningar efter beteenden som rispning, pillande eller skärande och lokaliserade sedan motsvarande videoklipp. Efter att ha gjort ansikten oigenkännliga och tagit bort identifierande detaljer satte de samman 59 klipp som visade verklig självskada och 59 normala klipp för jämförelse.
Sätta dagens bästa video-AI på prov
Med dessa dataset i hand utvärderade teamet ledande handlingsigenkänningssystem—datorprogram designade för att förstå vad människor gör i en video. Vissa byggde på äldre konvolutionsnätverk som analyserar korta bildsekvenser, medan nyare transformerbaserade modeller använder uppmärksamhetsmekanismer för att koppla mönster över rum och tid. Alla modeller tränades enbart på studiovideorna för att avgöra om ett klipp visade självskada eller normalt beteende. Viktigt är att forskarna använde en strikt testupplägg: i varje omgång hölls alla klipp från en skådespelare ut som helt ny testdata, vilket säkerställde att algoritmerna inte bara kunde memorera enskilda personer.
När rena studiovideor möter rörig verklighet
På det prydliga studiomaterialet utmärkte sig den mest avancerade transformermodellen, kallad VideoMAEv2. Den balanserade bättre mellan missade upptäckter och falsklarm än de andra och nådde ett F1-värde (en samlad måttstock för precision och återkallning) på omkring 0,65, medan enklare metoder låg nära slumpvisa gissningar. Visuella förklaringar visade att denna modell fokuserade tätt på där ett verktyg mötte huden, snarare än att distraheras av rörelse i bakgrunden. Men när samma tränade system släpptes fria på de verkliga avdelningsinspelningarna—utan någon omträning—sjönk deras prestanda. VideoMAEv2 presterade fortfarande bättre än slumpen, med ett F1 runt 0,61, men hade särskilt svårt med subtila beteenden som pillande och rispning som aldrig förekommit i scenariot, samt med patienter som var små, långt från kameran eller delvis dolda.
Vad detta betyder för patientsäkerhet
Sammantaget visar resultaten på en tydlig "simulation-till-verklighet"-klyfta. AI-system som verkar lovande på noggrant iscensatta videor kan svikta när de konfronteras med röran, konstiga vinklar och varierande beteenden i verkligt sjukhusliv. Studiens huvudsakliga bidrag är inte en färdig säkerhetsprodukt utan en startpunkt: ett offentligt, välannoterat studiodataset, ett noggrant insamlat verklighetstestset och ett transparent benchmark som visar var dagens metoder brister. För icke-specialister är budskapet enkelt: AI kan redan hjälpa till att framhäva misstänkta ögonblick i avdelningsvideoströmmar, men kan ännu inte litas på som en fristående väktare. Att stänga denna klyfta kommer att kräva rikare, mer varierade träningsdata och smartare modeller, utvecklade med integritet, rättvisa och klinisk bedömning i främsta rummet.
Citering: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
Nyckelord: upptäckt av självskada, psykiatriska avdelningar, videoaktionsigenkänning, artificiell intelligens inom vården, patientsäkerhet