Clear Sky Science · sv
MQADet: ett plug-and-play-paradigm för att förbättra öppen-vokabulär objektigenkänning via multimodal fråge-svar
Varför smartare objektfinnare spelar roll
Telefoner, bilar, hemrobotar och sökmotorer förlitar sig i allt högre grad på mjukvara som kan hitta objekt i bilder: ett barn som korsar gatan, dina förlorade nycklar på ett bord eller en specifik produkt i en hylla. Men de flesta av dagens system förstår bara korta, enkla etiketter som ”hund” eller ”bil”. När du ber om ”den lilla hunden med ett rött halsband som ligger bakom soffkudden” blir de ofta förvirrade. Denna artikel presenterar MQADet, ett sätt att uppgradera befintliga objektfinnarsystem så att de kan förstå sådana rika, detaljerade beskrivningar utan att träna om de underliggande modellerna.
Från fasta listor till öppet slutet förståelse
Traditionella objektdetektorer tränas på fasta listor av kategorier, till exempel de 80 vardagsföremål som ingår i det populära COCO-datasetet. De fungerar bra så länge objektet tillhör en av dessa kategorier och förfrågan är kort och tydlig. Verkligheten är dock rörigare. Människor refererar till saker med långa fraser, subtila attribut och relationer som ”mannen i den gula västen som står bakom lastbilen”. Nyare ”öppen-vokabulär”-detektorer försöker bryta sig loss från fasta listor genom att koppla bilder till text, men de har fortfarande svårt med komplex formulering och med sällsynta, långsvansade kategorier som dyker upp sparsamt i träningsdata. De kräver dessutom mycket beräkningskraft och data för att förbättras.
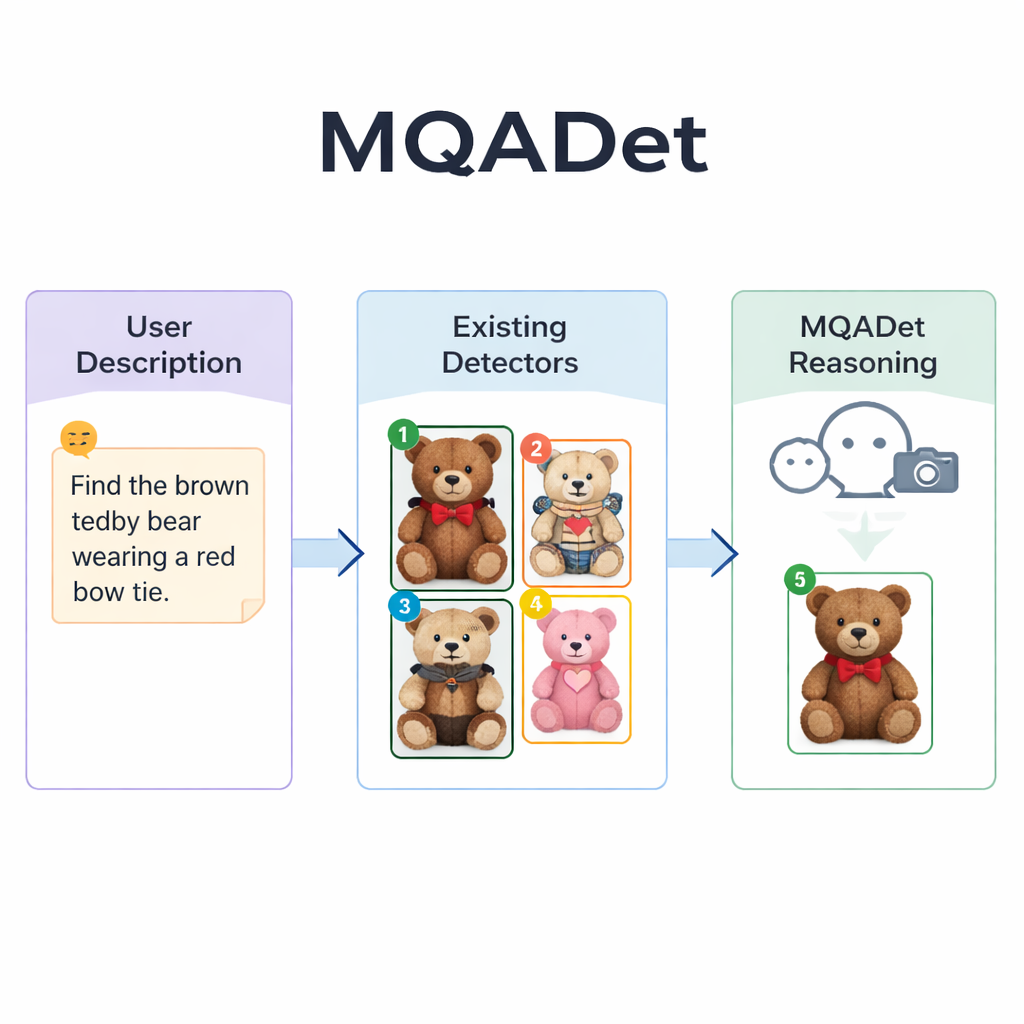
Låta språkmodeller styra sökandet
MQADet tar itu med dessa problem genom att placera en multimodal stor språkmodell—ett system som både kan se på bilder och läsa text—ovanpå befintliga detektorer i en trestegs fråge‑och‑svar-process. Först läser ett steg kallat Text‑Aware Subject Extraction användarens hela mening och plockar ut de verkliga målen, till exempel ”paraply” och ”fotgängare” från en lång beskrivning. Detta speglar hur en människa snabbt kan identifiera huvudsubstantiven i en mening innan hen skannar en scen. Avgörande är att detta steg utnyttjar språkmodellens starka förståelse av naturligt språk, så att den kan hantera långa, beskrivande fraser istället för bara enstaka ord.
Markera kandidatobjekt i bilden
I det andra steget, Text‑Guided Multimodal Object Positioning, skickar MQADet de extraherade ämnena tillsammans med bilden till en befintlig öppen‑vokabulär detektor—såsom Grounding DINO, YOLO‑World eller OmDet‑Turbo. Detektorn föreslår flera möjliga positioner i bilden där varje subjekt kan finnas, ritar en ruta runt varje kandidat och placerar ett enkelt nummer i rutan. Resultatet är en ”markerad bild” som visar alla rimliga alternativ. Viktigt är att MQADet inte tränar om dessa detektorer; det använder dem som de är. Det gör tillvägagångssättet plug‑and‑play: när en bättre detektor dyker upp kan den bytas in i pipelinen utan extra data eller finjustering.

Resonerar sig fram till bästa träffen
Det tredje steget, kallat MLLMs‑Driven Optimal Object Selection, förvandlar det slutliga valet till en flervalsfråga för språkmodellen: givet den ursprungliga beskrivningen och den markerade bilden med numrerade rutor, vilket nummer matchar texten bäst? Eftersom modellen ser både den detaljerade formuleringen och den visuella layouten kan den väga in finstämda ledtrådar—mönster, färger, spatiala relationer som ”till vänster” och interaktioner mellan objekt. Författarna visar att borttagandet av detta resonemangssteg kraftigt minskar noggrannheten, vilket understryker dess betydelse. Med denna trestegsdesign förbättrade MQADet noggrannheten över fyra krävande benchmarkset med långa, naturliga meningar, ofta med en ökning av prestanda för befintliga detektorer med 10–40 procentenheter utan att deras interna vikter ändrades.
Vad detta betyder för vardagsteknik
För en icke‑specialist är huvudbudskapet att vi inte längre behöver bygga om objektdetektorer från grunden för att göra dem smartare. MQADet fungerar som en intelligent assistent ovanpå nuvarande system, hjälper dem att tolka rika mänskliga beskrivningar och välja rätt objekt i komplexa scener. Det kan göra visuell sökning, hjälpmedel och autonoma maskiner mer pålitliga när de hanterar hur människor naturligt talar—fullt av detaljer, nyanser och kontext—och bana väg för mer intuitiva, språkdrivna interaktioner med den visuella världen.
Citering: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Nyckelord: öppen-vokabulär objektigenkänning, multimodala stora språkmodeller, visuell fråge-svar, datorseende, bildförståelse