Clear Sky Science · sv
Maskininlärningsanvändning för att förutsäga behandlingsutfall vid koloncancer
Varför det är viktigt att förutsäga utfall vid koloncancer
Koloncancer är en av de vanligaste cancerformerna i världen, och många patienter och deras anhöriga vill veta något enkelt men brådskande: ”Vilka är mina chanser, och vad kan göras för att förbättra dem?” Denna studie från Iran undersöker hur moderna datormetoder, kända som maskininlärning, kan gå igenom detaljerade sjukjournaler för att bättre förutsäga vilka patienter som löper högre risk efter operation. Genom att skärpa dessa prognoser kan läkare i högre grad skräddarsy behandling och uppföljning, vilket kan ge sårbara patienter en bättre möjlighet till långsiktig överlevnad.
Att omvandla journaler till användbara mönster
Forskarna använde tio års data från 764 personer som genomgick operation för koloncancer vid ett stort center i Shiraz, Iran. För varje patient samlades 44 uppgifter in, inklusive ålder, blodprover, tumörstorlek, cancerskede, symtom och detaljer om operationen och behandlingar som cytostatika. Dessa journaler rensades och kontrollerades noggrant: omöjliga laboratorievärden rättades, patienter som inte kunde följas upp togs bort och saknade svar fylldes i med rimliga uppskattningar. Teamet delade sedan upp data så att största delen användes för att träna dator modellerna, medan en separat del hölls tillbaka för att testa hur väl dessa modeller kunde förutsäga vem som var vid liv eller hade avlidit vid uppföljning.
Hur intelligenta algoritmer lär från patienter
I stället för att förlita sig enbart på traditionell statistik jämförde studien flera moderna datorbaserade metoder sida vid sida. Dessa inkluderade olika ”forest”- och ”boosting”-metoder, som kombinerar många enkla beslutsregler, samt neurala nätverk som löst efterliknar hur hjärnceller kopplar sig. Målet för varje metod var detsamma: använda patienternas uppgifter för att gissa om varje person skulle överleva, och sedan jämföra dessa gissningar med vad som faktiskt hände. Modellerna bedömdes utifrån hur ofta de hade rätt totalt, hur bra de var på att fånga upp patienter som avled och hur väl de undvek falska larm för dem som överlevde. De bäst presterande metoderna nådde omkring 80 % total noggrannhet, ett starkt resultat med tanke på komplexiteten i cancerutfall.
Vilka modeller och faktorer som betydde mest
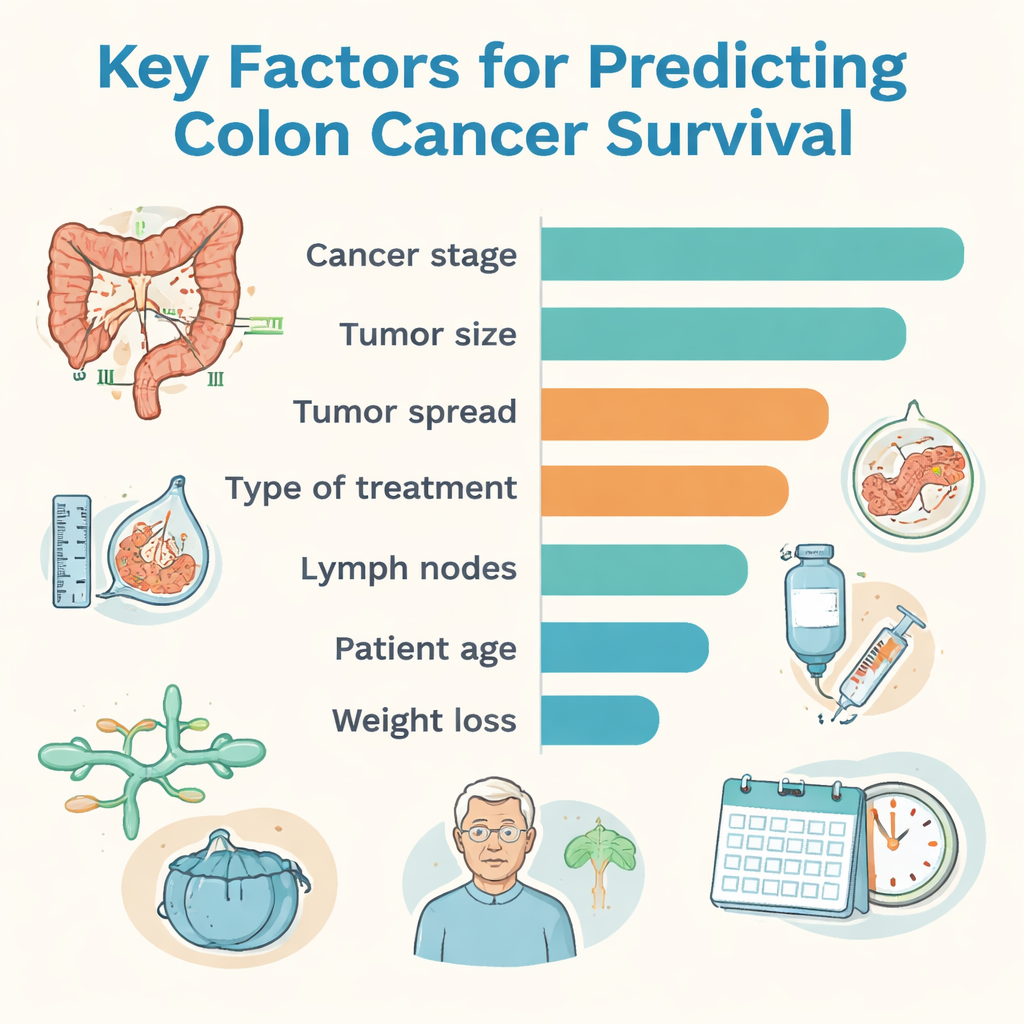
Bland alla tillvägagångssätt gav en metod kallad CatBoost högst total noggrannhet, medan en random forest-modell visade bäst balans mellan att korrekt flagga högriskpatienter och att inte överanmäla risk hos dem som klarade sig väl. För att göra resultaten mer förståeliga för läkare använde teamet ett förklaringsverktyg som rankar vilka uppgifter som mest påverkade datorns beslut. Cancerskede — en sammanfattning av hur stor tumören är, om den nått lymfkörtlar och om den spridit sig — var den enskilt starkaste faktorn. Tumörstorlek, hur djupt tumören invaderade tarmväggen, närvaro av spridning till andra organ, typ av behandling, tumörgrad (hur avvikande cellerna såg ut), involvering av lymf- och blodkärl, patientens ålder och viktnedgång spelade också viktiga roller för att forma överlevnadsprognoserna.
Från siffror till vård vid sängen
Dessa fynd tyder på att en omsorgsfullt tränad datoriserad modell, matad med rutinmässig klinisk information, kan hjälpa läkare att upptäcka patienter som diskret löper hög risk efter operation för koloncancer. I vardaglig praxis skulle ett sådant verktyg kunna ligga inbäddat i en elektronisk journal och omedelbart kombinera detaljer om patientens tumör och allmänna hälsa till en enkel riskuppskattning. Det numret skulle inte ersätta läkarens omdöme, men det kan styra val som hur ofta en patient bör kontrolleras, om ytterligare behandlingar är värda biverkningarna eller när en second opinion behövs. Eftersom de viktigaste faktorerna som identifierats av datorn stämmer överens med vad cancerspecialister redan anser vara avgörande, blir systemet lättare att lita på och att förklara för patienter.
Vad detta betyder för patienter och framtiden
För patienter och familjer är huvudbudskapet att datorer nu kan använda vanliga medicinska data för att stödja mer personanpassad vård vid koloncancer. Studien utfördes vid ett enda center i Iran och behöver fortfarande testas i andra sjukhus och med rikare data, såsom genetisk och bilddiagnostisk information, men den visar att maskininlärning kan peka ut vem som behöver extra uppmärksamhet och varför. Med tiden, när fler data läggs till och modellerna förfinas, kan dessa verktyg hjälpa läkare världen över att ge behandling som inte bara är evidensbaserad utan också fint anpassad till varje persons specifika cancer och omständigheter.
Citering: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Nyckelord: koloncancer, maskininlärning, behandlingsutfall, riskbedömning, kliniska data