Clear Sky Science · sv
Att överbrygga prestationsklyftan: systematisk optimering av lokala LLM för japansk medicinsk PHI-extraktion
Varför detta är viktigt för patientsekretessen
Sjukhus förfogar över stora samlingar medicinska anteckningar som kan förbättra vård och forskning, men dessa journaler innehåller ofta känsliga uppgifter som namn, adresser och datum. Kraftfulla molnbaserade AI-system är mycket bra på att dölja sådan information, men många sjukhus har inte tillåtelse att skicka rå patientdata till externa servrar. Denna studie visar att med noggrann fininställning kan mindre AI‑modeller som körs helt lokalt på sjukhuset komma förvånansvärt nära prestandan hos ledande molnsystem — vilket ger ett sätt att använda AI samtidigt som patientdata hålls säkra på plats.
Dilemmat: sekretess kontra framsteg
Moderna stora språkmodeller kan pålitligt identifiera och ta bort skyddad hälsoinformation (PHI) från medicinsk text, ofta med över 90 procents noggrannhet. Att skicka oredigerade patientanteckningar till molntjänster väcker dock juridiska och etiska frågor under regler som HIPAA, GDPR och Japans APPI. Många institutioner insisterar på full ”datastyrning”, vilket betyder att information aldrig lämnar deras egna system. Hittills har lokala modeller som kan köras på intern hårdvara ofta missat betydligt fler identifierare, vilket tvingat sjukhus till ett val: kraftfull analys i molnet eller striktare sekretess med svagare verktyg. Författarna ville undersöka om denna klyfta kunde stängas tillräckligt för verklig klinisk användning.
En etappvis plan för smartare lokal AI
Teamet utformade ett femstegsoptimeringsramverk för att successivt förbättra prestandan hos lokala språkmodeller vid borttagning av PHI i japanska röntgenrapporter. De började med 14 olika modeller i skilda storlekar, alla körda på en isolerad, internetfri dator avsedd att efterlikna sjukhusets säkerhet. Med hjälp av 160 noggrant utformade syntetiska rapporter — realistiska men helt fiktiva — mätte de hur väl varje modell fann och separerade åtta typer av identifierare, från namn och id‑nummer till datum och avdelningar. Efter ett initialt baslinjetest skapade de mer hjälpsamma allmänna prompts, skräddarsydde instruktioner efter varje modells egenheter, lade till en automatiserad ”självkontroll och korrigering”-loop och testade slutligen de bästa kandidaterna på en reserverad uppsättning rapporter. 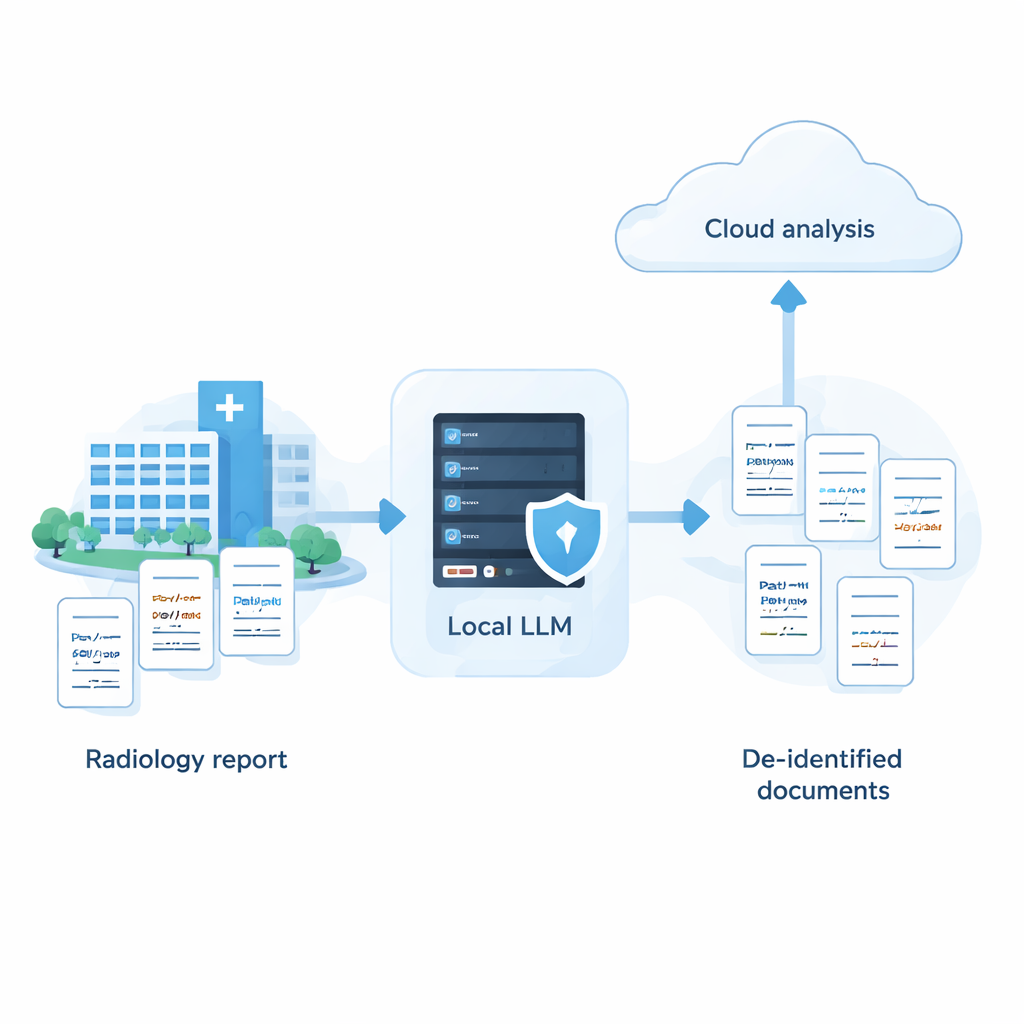
Närmar sig molnprestanda
Genom denna etappvis process fann forskarna att rå modellstorlek inte var avgörande; vissa mycket stora system presterade fortfarande dåligt. Istället var de mest lovande modellerna de som svarade väl på noggrant utformade instruktioner och felanalys. Ett mellanstort system, Mistral-Small-3.2, blev klar segrare efter anpassade prompts och ett självförbättringssteg där modellen granskade och selektivt korrigerade sin egen output. På de avslutande 60 testfallen uppnådde denna optimerade lokala uppsättning 91,54 av 100 — ungefär 97,8 procent av den ledande molnmodellens 93,56 poäng — samtidigt som formatreglerna följdes perfekt. I praktiska termer bedömdes den återstående skillnaden som kliniskt marginell. Den största kostnaden var hastigheten: lokal bearbetning tog omkring 25 sekunder per typisk rapport, jämfört med under 2 sekunder i molnet, men detta ansågs acceptabelt för rutinmässigt, icke-akut batcharbete. 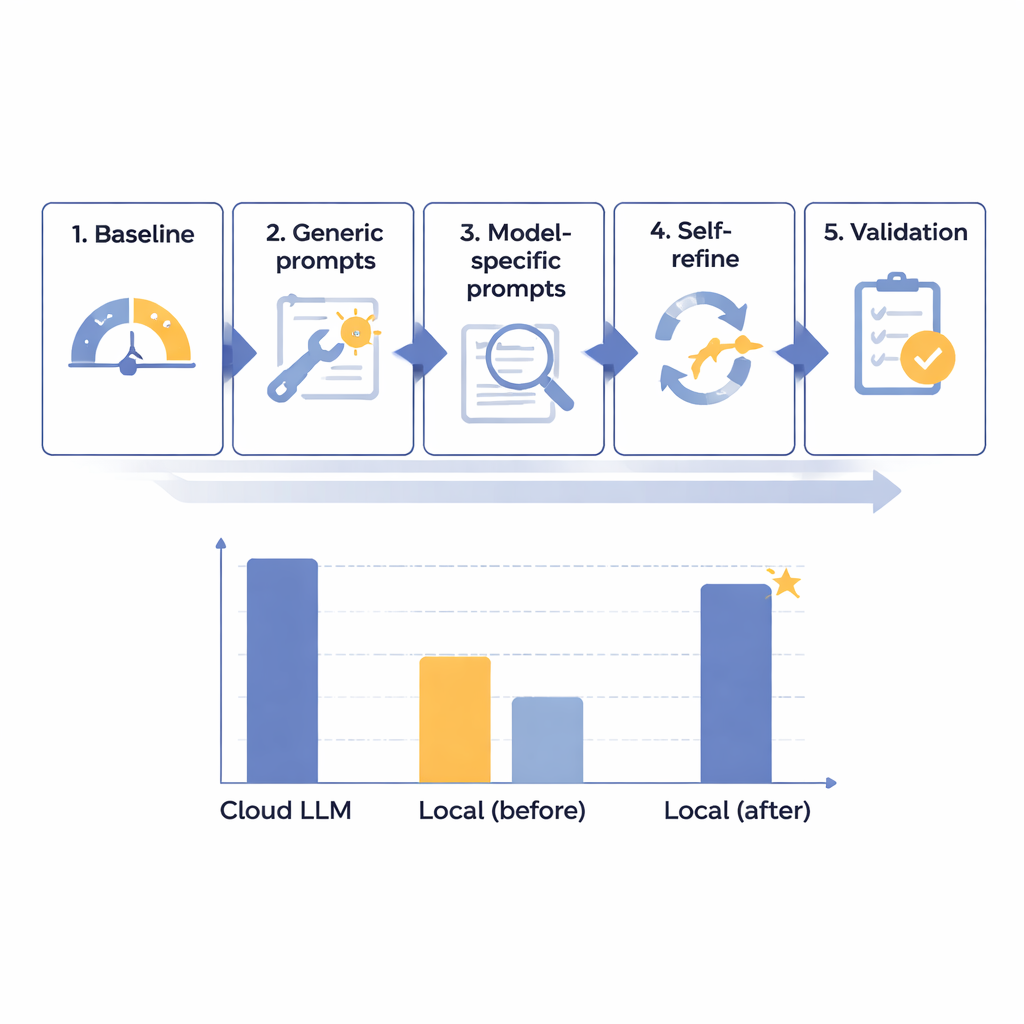
En överraskande tröskel för självkorrigering
En av de mest intressanta fynden var en slags brytpunkt runt 87–88 poäng på författarnas 100‑gradiga skala. Modeller som vid baslinjen låg under denna nivå — som Mistral-Small-3.2 — gynnades kraftigt av självförbättringsloopen och ökade nästan sju poäng genom att rätta en liten andel av sina egna misstag. Modeller som redan startade över denna tröskel visade nästan ingen förbättring och slösade ibland effort på att försöka ”korrigera” korrekta svar. Detta tyder på att avancerade optimeringsverktyg bör reserveras för modeller som är bra men inte ännu utmärkta, vilket ger sjukhus ett sätt att fokusera beräkningsresurser och personalinsats där det ger mest effekt. Författarna varnar att denna tröskel bygger på bara två modeller och behöver bekräftas, men den erbjuder en tidig tumregel för driftsplanering.
Vad detta betyder för sjukhus och patienter
Studien hävdar att sjukhus inte behöver välja mellan stark sekretess och kraftfull AI. Med ett systematiskt förhållningssätt — granska många modeller, anpassa prompts efter deras styrkor och svagheter och lägga till ett intelligent självrevisionssteg — är det möjligt för ett fullständigt lokalt system att närma sig noggrannheten hos ledande molntjänster vid borttagning av känslig information ur medicinsk text. I praktiken öppnar detta dörren för en hybridstrategi: PHI tas säkert bort på sjukhusägda maskiner och endast anonymiserade rapporter, med namn och andra identifierare borttagna, skickas till molnet för mer avancerad analys. Trots att arbetet hittills bygger på syntetiska japanska röntgenrapporter och måste testas på verkliga data och andra språk, erbjuder det en handlingsbar färdplan för institutioner som vill utnyttja AI samtidigt som patienternas förtroende och integritet står i centrum.
Citering: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Nyckelord: medicinsk avidentifiering, patientsekretess, lokala språkmodeller, AI inom vården, röntgenrapporter