Clear Sky Science · sv
Maskininlärningsbaserad variansuppskattning vid tvåstegsurval med data från hälso- och utbildningssektorn
Varför smartare medelvärden spelar roll för verkliga beslut
När läkare studerar blodtryck eller pedagoger följer elevers betyg handlar det inte bara om medelvärdet; de behöver också veta hur stor spridningen kring det medelvärdet är. Denna spridning, kallad variabilitet, styr hur många patienter som behövs i en studie, hur omfattande ett handledningsprogram bör vara eller hur säkra vi kan vara i policybeslut. Artikeln bakom denna sammanfattning presenterar ett nytt, statistiskt välgrundat sätt att mäta den variabiliteten mer precist genom att kombinera klassiska urvalsidéer med modern maskininlärning, testat på data från hälso- och utbildningssektorn.
Mäta spridning när informationen är ofullständig
I en ideal värld skulle forskare känna till ytterligare uppgifter om varje person i en population innan de genomför en undersökning: ålder, studievanor, medicinsk historia med mera. I verkligheten är sådan information ofta bristfällig eller kostsam att samla in. Författarna arbetar inom en design som kallas tvåstegsurval för att hantera detta. I första steget tar de ett stort, relativt billigt stickprov och registrerar enkla bakgrundsuppgifter, såsom ålder eller om någon har internetåtkomst. I andra steget drar de ett mindre delurval och mäter ett dyrare eller mer tidskrävande utfall, till exempel systoliskt blodtryck eller slutbetyg. Utmaningen är att använda dessa två informationsnivåer för att uppskatta hur variabelt utfallet verkligen är i hela populationen.
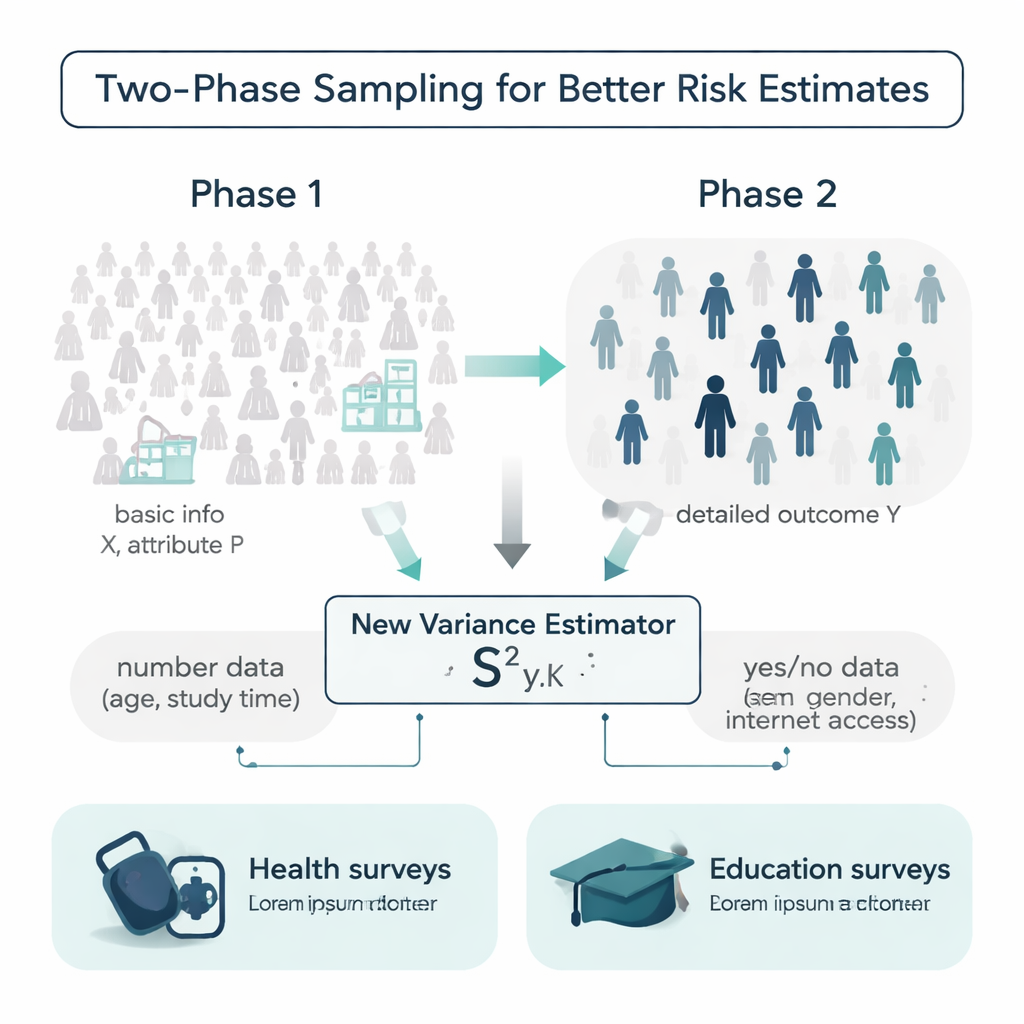
En ny estimator som använder både numeriska och ja/nej-egenskaper
De flesta traditionella verktyg för att mäta variabilitet förlitar sig endast på utfallet självt eller på en enda hjälpparameter, och de antar ofta att data följer bekväma klockformade mönster. Författarna föreslår en ny variansestimator som använder två typer av extra information samtidigt: en numerisk hjälpparameter (till exempel ålder eller veckovis studietid) och en ja/nej-attribut (såsom kön eller internetåtkomst). De visar matematiskt hur denna kombinerade ”blandnings”-estimator beter sig, och härleder formler för dess bias och medelkvadrerade fel — två nyckelmått på noggrannhet. Under rimliga villkor är estimatorn i praktiken obiaserad och dess förväntade fel är mindre än för många använda konkurrerande formler, vilket innebär att den bör ge skarpare osäkerhetsuppskattningar med samma mängd data.
Testa prestanda över många datavärldar
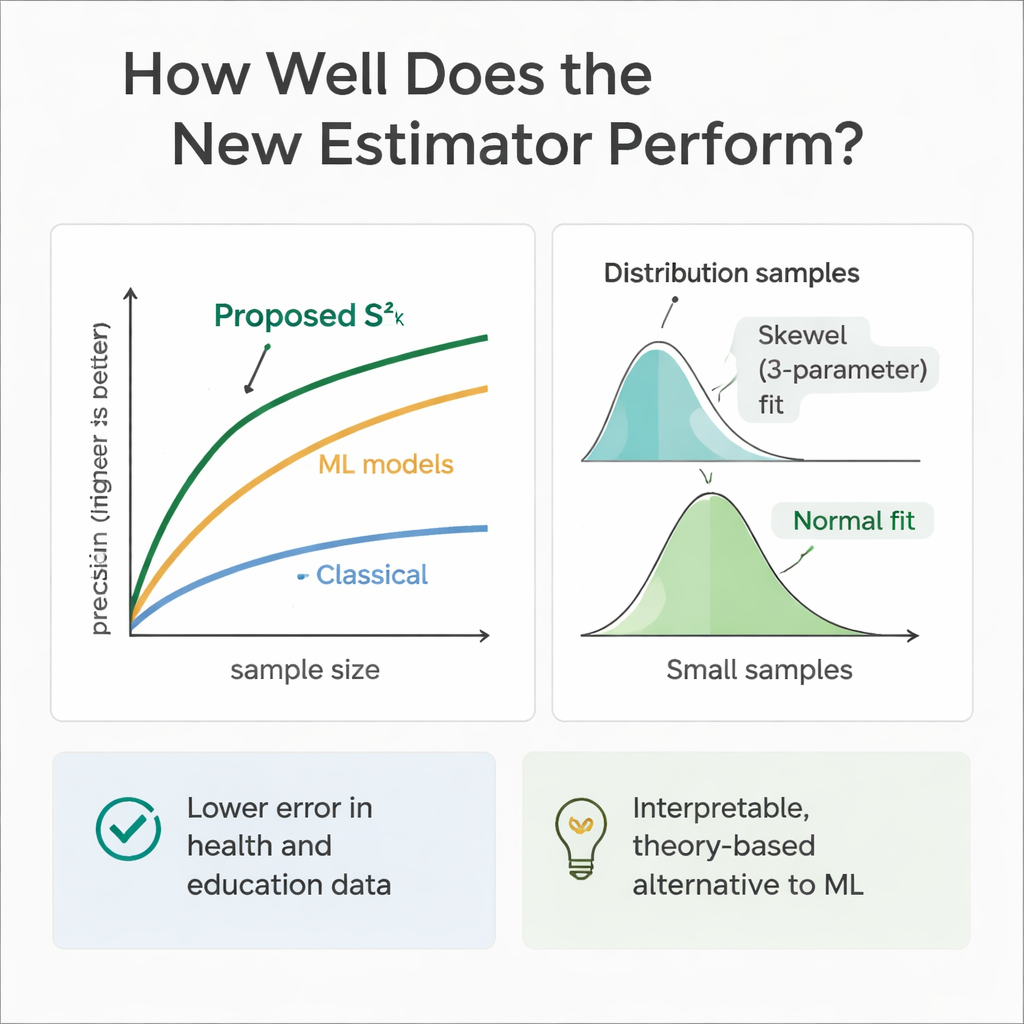
För att kontrollera om teorin stämmer med praktiken körde teamet omfattande datorexperiment. De simulerade populationer där hjälpparametrarna och utfallet följde en rad fördelningar, från symmetriska (Normal och Uniform) till snedfördelade (Gamma och Weibull). Genom upprepade stickprov jämförde de nya estimatorns fel med flera etablerade metoder över olika stickprovsstorlekar. I nästan alla inställningar, och särskilt när stickprovsstorlekar ökade, visade den nya metoden mycket högre relativ effektivitet — ofta med felreduktion på 30 till 70 procent jämfört med klassisk variansestimator. Författarna undersökte även hur estimatorns egen stickprovsfördelning ser ut och fann att en flexibel treparametrig Weibull-kurva beskriver den bäst för måttliga stickprov, medan den tenderar mot en normalfördelning när stickproven blir stora.
Verkliga data från kliniker och klassrum
Metoden tillämpades sedan på två verkliga fallstudier. I en hälsodatamängd var utfallet systoliskt blodtryck, med ålder som den numeriska hjälpparametern och kön som ja/nej-attribut. I en utbildningsdatamängd var utfallet slutbetyg, hjälpen var veckovis studietid och attributet var om studenten hade internetåtkomst. I båda fallen gav den föreslagna estimatorn det lägsta medelkvadrerade felet bland alla testade statistiska konkurrenter, och den drog avsevärt ihop den uppskattade variabiliteten kring både medelblodtrycket och medelstudentprestationen. Denna förbättring översätts till mer precisa konfidensintervall och mer tillförlitliga jämförelser mellan grupper eller interventioner.
Hur den står sig mot maskininlärning
Då maskininlärningsmodeller excellerar i prediktion tränade författarna även regressions-träd, random forests och support vector regression på samma simulerade hälso- och utbildningsscenarier. Dessa modeller, matade med samma hjälpparametrar, matchade ofta eller överträffade något den nya estimatorn i ren prediktiv noggrannhet. De uppträder dock som svarta lådor: det är svårt att spåra exakt hur de kombinerar information och de saknar de tydliga formlerna som krävs för traditionell urvalsinferens. Den föreslagna estimatorn, däremot, är transparent och rotad i urvalsteori, vilket gör den lättare att motivera i regulatoriska, kliniska eller politiska sammanhang där förklarbarhet är lika viktig som rå prestanda.
Vad detta betyder för undersökningar i praktiken
Enkelt uttryckt visar detta arbete att forskare kan få mer tillförlitliga mått på spridning utan att dramatiskt öka stickprovsstorlekar, helt enkelt genom att disciplinerat utnyttja även minimal extra information som de redan samlar in. Genom att blanda en numerisk faktor (som ålder eller studietid) med ett enkelt ja/nej-attribut (som kön eller internetåtkomst) i en tvåstegsplan ger den nya estimatorn skarpare, mer stabila variansuppskattningar än långvariga metoder. Samtidigt som avancerade maskininlärningsverktyg förblir användbara som referenspunkter, erbjuder detta tillvägagångssätt en praktisk och tolkbar mellanväg som hjälper analytiker inom hälsa och utbildning att dra starkare slutsatser från begränsade data.
Citering: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Nyckelord: urvalsundersökning, variansuppskattning, maskininlärning, hälsoinformation, utbildningsforskning