Clear Sky Science · sv
Utvärdering av tre artificiella intelligens-chatbottar för att generera flervalsfrågor i klinisk hematologi för läkarstudenter
Smartare provfrågor för morgondagens läkare
Flervalsprov låter kanske inte spännande, men de formar tyst framtida läkares färdigheter. Varje fråga i ett prov kan styra hur studenter tänker kring verkliga patienter. Denna studie ställer en aktuell fråga: kan moderna artificiella intelligens-chatbotar hjälpa upptagna medicinlärare att snabbare skriva bra provfrågor om blodsjukdomar, utan att offra kvalitet eller säkerhet?
Hur AI hjälpte till att skapa provfrågor
Forskarna koncentrerade sig på tre vidt använda AI-chatbotar, alla utformade för att generera text. De bad varje system att skriva 50 flervalsfrågor i hematologi, området som studerar blodsjukdomar som anemi och leukemi. Frågorna skulle täcka fem vanliga ämnen som förekommer i medicinska prov och klinisk praxis: pancytopeni (låga nivåer av alla blodceller), anemi, trombocytopeni (låga trombocyter) samt två grupper av blodcancer som kallas myelo- respektive lymfoproliferativa syndrom. Totalt skapade chatbotarna 150 frågor på mindre än en halv minut per system—en enorm tidsbesparing jämfört med att skriva dem för hand. 
Sätter AI-skrivna frågor under mikroskopet
Hastighet ensam är meningslös om frågorna är felaktiga, förvirrande eller orättvisa. För att kontrollera kvaliteten graderade tre erfarna lärare i hematologi—som inte visste vilken chatbot som skrivit vilken fråga—varje objekt med hjälp av en detaljerad checklista. De bedömde vetenskaplig noggrannhet, klinisk relevans, formuleringens klarhet, realism hos felaktiga svarsalternativ och total kvalitet på en femgradig skala. De bedömde också om varje fråga hade rätt svårighetsgrad för läkarstudenter och om den kunde skilja starka studenter från svagare. Frågor som nådde minst 15 av 25 poäng ansågs acceptabla för användning; andra behövde revidering eller avvisades.
Vilken chatbot klarade sig bäst?
Alla tre systemen producerade mestadels stabila frågor, men en modell utmärkte sig. I experternas omdömen fick denna chatbot högst poäng för noggrannhet, klinisk relevans och trovärdiga felaktiga svar. Samtliga av dess 50 frågor nådde acceptanströskeln och behövde inga förändringar. De andra två modellerna presterade fortfarande väl: mer än nio av tio av deras frågor var tillräckligt bra men krävde små justeringar, ofta eftersom ett felaktigt alternativ var alltför uppenbart fel eller en detalj kunde vara tydligare. Sammantaget var experterna överens om att alla tre verktyg snabbt kan generera provmaterial som i hög grad är nära att vara redo för undervisningsbruk. 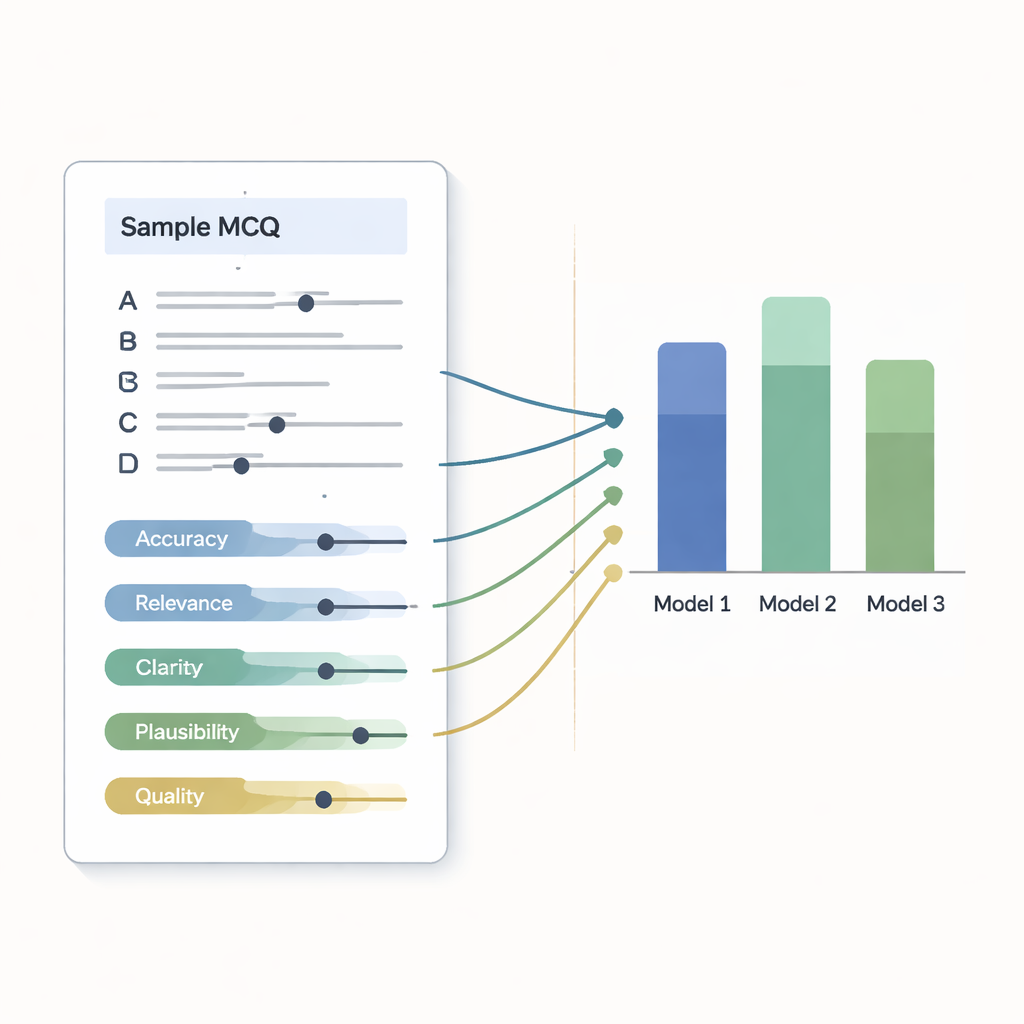
Tänkande färdigheter, inte bara memorering
Teamet undersökte också vilken typ av tänkande dessa AI-skrivna frågor krävde av studenterna. Med hjälp av Blooms taxonomi—en ram verktygslärare använder för att klassificera mentala färdigheter—grupperade de frågor i enkel kunskap och förståelse kontra högre ordningens färdigheter som att tillämpa fakta, analysera situationer och utvärdera alternativ. Överraskande nog producerade chatbotarna mestadels frågor på högre nivå. För en modell krävde över 90 % av objekten att studenterna resonerade kring kliniska scenarier snarare än enbart återgav fakta. Grundläggande återgivningsfrågor var relativt sällsynta över alla tre systemen. Detta mönster tyder på att stora språkmodeller, tränade på stora mängder sammanhängande text, naturligt tenderar mot kontextrika, problemlösande scenarier snarare än enkla flashcard-liknande uppmaningar.
Löften, begränsningar och behovet av mänskliga partner
Trots dessa styrkor upptäckte studien viktiga brister. Ingen av chatbotarna föreslog spontant bildbaserade frågor, vilka är avgörande inom hematologi där läkare måste tolka mikroskopbilder och laboratoriegrafik. När de blev direkt tillfrågade om bildbaserade objekt medgav två system att de inte kunde tillhandahålla dem, och en producerade ett lågkvalitativt försök. Studien förlitade sig också på expertbedömningar snarare än verkliga provdata från studenter, så den kan inte fullt ut bevisa hur väl dessa frågor skulle fungera i liveprov. Författarna betonar att lärare fortfarande måste kontrollera fakta, finslipa formuleringar och säkerställa att centrala grundläggande begrepp täcks tillräckligt.
Vad detta betyder för framtidens medicinska utbildning
För den icke-specialistiska läsaren är slutsatsen att AI inte ersätter medicinlärare, men att det blir en kraftfull assistent. I denna studie genererade chatbotar snabbt mestadels korrekta, kliniskt realistiska frågor som hjälper studenter att öva beslutsfattande vid blodsjukdomar. En modell i synnerhet producerade frågor av så hög kvalitet att experter skulle använda dem med liten eller ingen ändring. Ändå förbisedde maskinerna enklare kunskapskontroller och kunde inte hantera visuellt material på egen hand. Författarna drar slutsatsen att den bästa metoden är ett partnerskap: AI gör det tunga arbetet med att utarbeta varierade frågor, medan mänskliga experter styr uppmaningarna, fyller i saknade grundläggande delar, verifierar innehållet och håller jämna steg med förändrade medicinska riktlinjer.
Citering: Boufrikha, W., Sallem, A., Laabidi, B. et al. Evaluation of three artificial intelligence chatbots for generating clinical hematology multiple choice questions for medical students. Sci Rep 16, 5802 (2026). https://doi.org/10.1038/s41598-026-36839-x
Nyckelord: medicinsk utbildning, artificiell intelligens, hematologi, flervalsfrågor, chatbotar