Clear Sky Science · sv
Generaliserbarhet och överförbarhet hos maskininlärningsmodeller som använder hyperspektral reflektansdata för majskaraktäristika
Varför skanning av växtblad spelar roll för vår framtida mat
Att föda en växande befolkning under ett förändrat klimat kräver grödor som klarar värme, torka och andra påfrestningar. Förädlare vill veta vilka växter som har rätt kombination av bladstruktur, kemi och fotosyntetisk prestanda—men att mäta dessa egenskaper direkt på tusentals plantor är långsamt och destruktivt. Denna studie undersöker om enkel skanning av majsblad med en hyperspektralsensor tillsammans med maskininlärning på ett tillförlitligt sätt kan ersätta mödosamma laboratoriemätningar, även när plantor odlas under olika år och skiftande fältförhållanden.
Ljusavtryck från majsblad
Varje blad reflekterar ljus i ett mönster som beror på dess pigment, vatteninnehåll och interna struktur. Hyperspektrala sensorer fångar detta mönster över hundratals våglängder från synligt ljus till kortvågigt infrarött och skapar ett detaljerat "fingeravtryck" för varje blad. Forskarna samlade sådana fingeravtryck från en mångsidig majsbefolkning odlad under tre på varandra följande fältsäsonger, tillsammans med 25 egenskaper som beskriver bladanatomi (som specifik bladarea och kol–kvävebalans), gasutbyte (hur blad tar upp CO2 och förlorar vatten) och klorofyllfluorescens (en inblick i fotosyntesens effektivitet och reglering). Denna rika datamängd gjorde det möjligt att testa hur väl olika statistiska modeller kunde omvandla ljusspektran till skattningar av egenskaper.
Lära maskiner att läsa blad
Teamet fokuserade på två vitt använda, relativt enkla maskininlärningsmetoder: partial least squares regression (PLSR) och linjär support vector regression (SVR). Båda metoderna komprimerar de högt detaljerade spektren till en mindre uppsättning informativa funktioner innan de kopplas till uppmätta egenskaper. Forskarna jämförde noggrant sätt att ställa in modellerna, särskilt hur många komponenter PLSR bör använda och hur man undviker överanpassning. De undersökte också om det är bättre att mata modeller med individuella bladmätningar, medelvärden från en enskild försöksruta eller medelvärden över alla plantor av samma genotyp. Ett strikt, nästlat korsvalideringsramverk—i praktiken upprepade tränings–test-cykler—användes för att kontrollera prestanda och osäkerhet.
Vilka egenskaper som är lättast att förutsäga
Vissa bladegenskaper visade sig vara mycket mer "läsbara" från ljusspektran än andra. Strukturella och biokemiska egenskaper, såsom specifik bladarea och kväveinnehåll, förutspåddes med hög noggrannhet, särskilt när data medelvärdesbildades på genotypnivå för att minska mätbrus. Vissa fotosyntetiska kapacitetsegenskaper och vissa indikatorer från klorofyllfluorescens som beskriver hur fotosystem II beter sig under ljus visade också måttlig förutsägbarhet. Däremot fångades egenskaper kopplade till snabba, kortlivade processer—som hastigheten vid vilken blad ökar eller slappnar av skyddande energidissipation—dåligt. För dessa är den spektrala signalen antingen svag eller lätt överröst av miljövariation vid mättillfället.
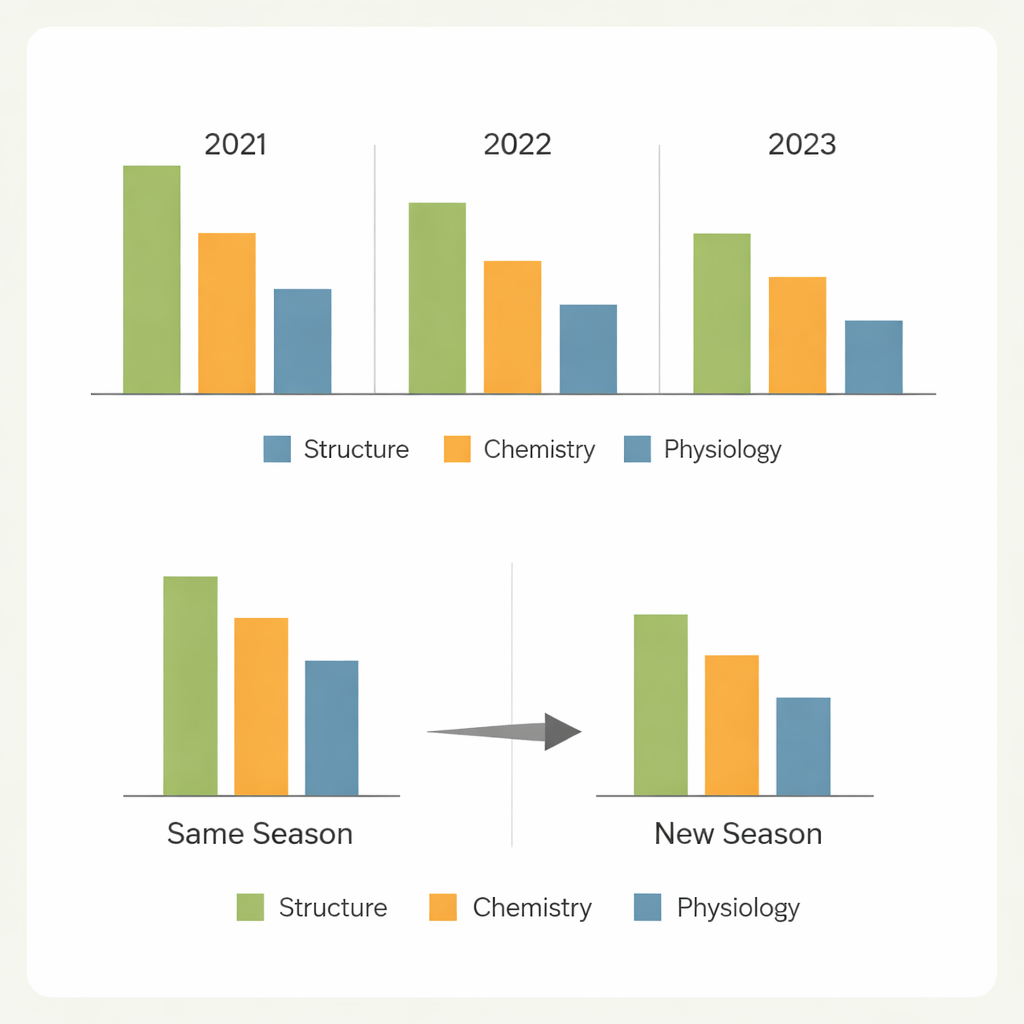
Från en säsong till nästa
En viktig fråga för verklig förädling är om en modell tränad under ett visst villkor kan litas på under ett annat. När modellerna förutsade slumpmässiga plantor inom samma säsong var prestandan i allmänhet stark för de enklare egenskaperna. Att förutsäga helt nya genotyper odlade samma säsong ledde till endast måttliga försämringar för strukturella och kväverelaterade egenskaper, men mycket kraftigare nedgångar för gasutbytegenskaper. Det mest krävande testet—att förutsäga nya genotyper under ett annat år—visade stora förluster i noggrannhet, särskilt för egenskaper starkt påverkade av miljön. Skillnader i väder, fältförhållanden och genotypmix skiftade de spektrala mönstren tillräckligt mycket för att begränsa överförbarheten, där en säsong framstod som särskilt svår att förutsäga från de andra.
Vad detta betyder för förädling och fjärranalys
För förädlare och grödforskare erbjuder studien både uppmuntran och försiktighet. Hyperspektral skanning i kombination med relativt enkel maskininlärning är redan ett kraftfullt verktyg för höggenomströmninguppskattning av stabila, integrerande egenskaper som bladstruktur och kvävestatus, och kan generalisera över genotyper och år relativt väl för dessa mål. Däremot är samma tillvägagångssätt mycket mindre tillförlitligt för snabba, miljökänsliga fysiologiska egenskaper när modellerna appliceras utanför de förhållanden de tränats på. Författarna drar slutsatsen att hyperspektrala metoder är redo att stödja storskalig screening av några nyckel-egenskaper hos majs, men att förutsägelse av dynamiskt fysiologiskt beteende över miljöer kommer att kräva rikare träningsdata, mer avancerad modellering och möjligen ytterligare typer av mätningar.
Citering: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Nyckelord: hyperspektral reflektans, majs, maskininlärning, växtfenotypering, fotosyntes