Clear Sky Science · sv
Taxonomisk modellering och klassificering i rapportering av fel på rymdhårdvara
Att hitta mönster i rymdflygningenas störningar
Varje rymduppdrag bygger på att otaliga hårdvarukomponenter fungerar felfritt, från bultar och kablar till livsuppehållande system. När något går fel skriver ingenjörerna detaljerade avviksrapporter, men NASA har nu mer än 54 000 sådana poster—alltför många för att personer ska kunna läsa dem en och en. Denna studie visar hur moderna verktyg för språkbehandling och maskininlärning kan förvandla detta textberg till organiserad kunskap, så att ingenjörer kan upptäcka mönster i fel, förbättra konstruktioner och göra astronauterna säkrare.
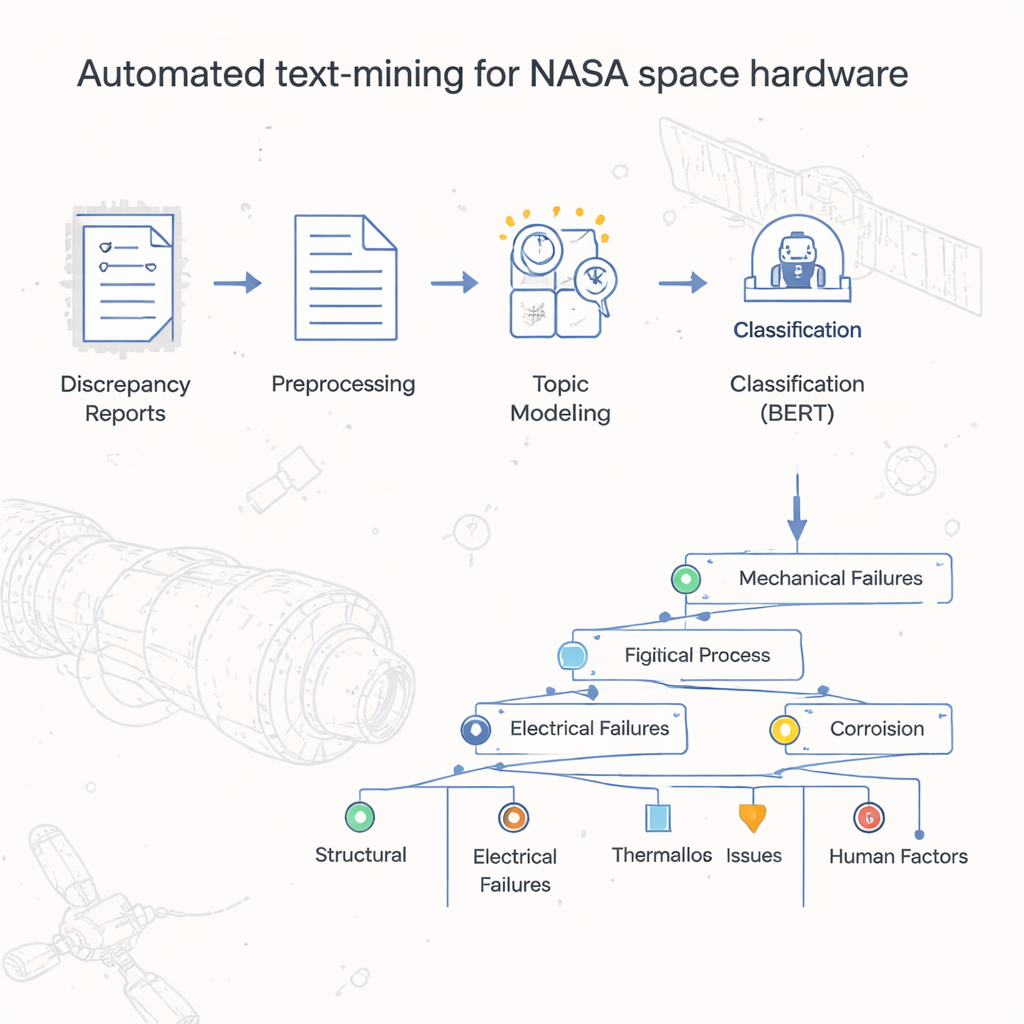
Från högar av rapporter till organiserad insikt
I årtionden har NASAs Johnson Space Center lagrat rapporter om hårdvarufel och avvikelser som digitala dokument, mycket likt skannade versioner av gamla pappersformulär. Enkla kalkylbladsräkningar visade vilka officiella felkoder som förekom oftast, men den verkliga berättelsen—de specifika orsakerna, stegen och villkoren som ledde till problemen—var begravd i fria textfält. Att läsa och kategorisera mer än 54 000 poster för hand skulle vara orimligt tidskrävande. Författarna gav sig i kast med att bygga ett automatiserat sätt att klassificera och gruppera dessa rapporter och skapa en slags "karta" eller taxonomi som fångar hur rymdhårdvara faktiskt fallerar i det dagliga arbetet.
Att lära datorer läsa ingenjörsspråk
Teamet rengjorde först texten i varje rapport så att datorer kunde arbeta med den effektivt. De tog bort lösa symboler och siffror som gav brus, bröt upp meningar i enskilda ord och konverterade dem till en enklare grundform (till exempel att omvandla "läckte" och "läckande" till "läcka"). Vanliga ord som bär liten betydelse, som "och" eller "den", filtrerades bort. När texten var standardiserad omvandlade forskarna den till siffror som maskininlärningsalgoritmer kan hantera, med etablerade tekniker som fångar hur ofta ord förekommer och hur starkt de karakteriserar ett dokument. Detta grundarbete gjorde det möjligt att applicera kraftfulla verktyg som ursprungligen utvecklats för allmänna språkuppgifter på den högspecialiserade världen av rapporter om rymdhårdvara.
Att bygga ett träd av feltyper
I projektets kärna finns en tvåstegsmodell som författarna kallar LDA-BERT. Det första steget, Latent Dirichlet Allocation (LDA), upptäcker automatiskt teman—kallade ämnen—genom att leta efter mönster av ord som ofta förekommer tillsammans över tusentals rapporter. En enskild rapport kan blanda flera ämnen, vilket speglar verkligheten där ett hårdvaruproblem kan ha flera bidragande orsaker. Andra steget använder BERT, en modern språkmodell, för att kontrollera och förfina hur väl dessa ämnen skiljer rapporterna åt. Genom att behandla LDA-ämnena som provisoriska etiketter och träna BERT att förutsäga dem kunde forskarna identifiera det antal och de kombinationer av ämnen som gav stabila, korrekta klassificeringar. De delade sedan ytterligare upp varje ämne i underämnen, med hjälp av klustring och statistiska kontroller, för att konstruera en grenad taxonomi som organiserar felrapporter från breda felkoder ner till detaljerade processnivåetiketter.
Att omvandla taxonomier till handlingsbara trender
När taxonomin var på plats visualiserade teamet den med instrumentpaneler och interaktiva verktyg. Varje gren och undergren i trädet kunde kopplas till annan information i rapporterna: när ett problem först noterades, hur lång tid det tog att åtgärda, vilken organisation som var ansvarig och vilket slutgiltigt beslut som fattades. Tidsseriediagram visade om vissa typer av problem—såsom inspektionsmissar eller toleransdatarelaterade problem—blev vanligare eller mer sällsynta över åren. Ordkartor gav en snabb känsla för språket som användes i varje kluster utan att läsa varje rapport. Dessa vyer hjälper chefer att fokusera på processfel med hög trend och stor påverkan, vilket vägleder utbildning, procedurändringar eller konstruktionsuppdateringar där de gör mest nytta.
Begränsningar i automatisk rotorsaksanalys
Forskarna undersökte också verktyg som försöker gå längre än märkning och trendidentifiering för att härleda direkta orsak-verkan-relationer från text. De testade system som INDRA-Eidos och skräddarsydda regelsatser byggda med språkverktyget spaCy. Även om dessa verktyg kunde extrahera vissa orsak–verkanspar och visualisera dem som interaktiva nätverk var många av de föreslagna länkarna för vaga eller förvirrande för att vara användbara. I praktiken hade modellerna svårt eftersom de ursprungliga rapporterna ofta inte uttryckte rotorsaker tydligt; ingenjörer antydde dem eller lämnade dem för senare utredning. Studien drar slutsatsen att att automatisera rotorsaksupptäckt på ett tillförlitligt sätt skulle kräva både rikare datainmatning—såsom explicita fält för sannolik orsak—och dyrare, mycket skräddarsydd modellträning än vad som är motiverat för denna engångsanalys.
Varför detta spelar roll för framtida uppdrag
Genom att omvandla ett stort, ostrukturerat arkiv av felrapporter till en tydlig, flerskiktad taxonomi ger detta arbete NASA ett praktiskt sätt att övervaka hur och varför hårdvaruproblem uppstår över tid. Även om metoderna ännu inte kan ersätta mänskligt omdöme för djup rotorsaksanalys är de mycket bra på att skanna stora mängder text för att lyfta fram var problem klustrar sig och vilka typer av processer som tenderar att vara involverade. Den typen av tidig varning och strukturerad insikt kan hjälpa ingenjörsteam att rikta uppmärksamhet, förfina rutiner och utforma mer robusta system—konkreta steg mot säkrare, mer pålitliga uppdrag till månen, Mars och längre bort.
Citering: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Nyckelord: fel på rymdhårdvara, bearbetning av naturligt språk, ämnesmodellering, riskanalys inom teknik, NASA-avviksrapporter