Clear Sky Science · sv
Verifiering av urdu-nyheters äkthet med djupinlärning genom sammanfogade BERT- och GloVe-embedding
Varför det är viktigt att upptäcka falska nyheter på urdu
I Pakistan och runt om i världen får fler människor nu sina nyheter från webbplatser och sociala medier än från tidningar eller television. Denna förskjutning har gjort det lättare än någonsin för falska berättelser att spridas snabbt, särskilt på nationella språk som urdu där digitala verktyg är begränsade. Denna studie tar itu med en enkel men brådskande fråga: kan modern artificiell intelligens automatiskt skilja verkliga urdu-nyheter från falska, och på så sätt hjälpa vanliga läsare, journalister och plattformar att försvara sig mot vilseledande information?
Den växande utmaningen med desinformation online
Författarna inleder med att beskriva hur fabricerade rubriker och förvanskade berättelser kan forma allmänhetens åsikter, driva politiska spänningar och till och med skada människors hälsa och ekonomi. Medan många faktakontrollsajter och forskningsprojekt koncentrerar sig på engelska, hamnar regionala språk som urdu ofta på efterkälken. Befintliga urdu-resurser innehåller bara några tusen nyhetsobjekt, många översatta från engelska och fokuserade på smala ämnesområden som politik. Det gör det svårt att träna pålitliga datorsystem att känna igen misstänkt innehåll på det språk som de flesta pakistanier faktiskt läser.
Att bygga en stor samling urdu-nyheter
För att överbrygga detta gap satte forskarna ihop vad de beskriver som den mest omfattande urdu-datamängden för falska nyheter hittills, med 14 178 nyhetsartiklar insamlade mellan 2017 och 2023 från ansedda pakistanska nyhetssajter och onlineplattformar. Berättelserna spänner över femton områden i vardagslivet, inklusive politik, hälsa, utbildning, affärer, brott, sport och miljö. Med hjälp av faktakontrollkällor som PolitiFact, FactCheck och specialiserade nyhets-API:er märktes varje artikel som riktig eller falsk; delvis sanna artiklar grupperades med riktiga nyheter för att återspegla mer nyanserad rapportering. Teamet rensade sedan texten genom att ta bort dubbletter, webbadresser och extra interpunktion, dela upp meningar i ord och plocka bort mycket vanliga fyllnadsord.
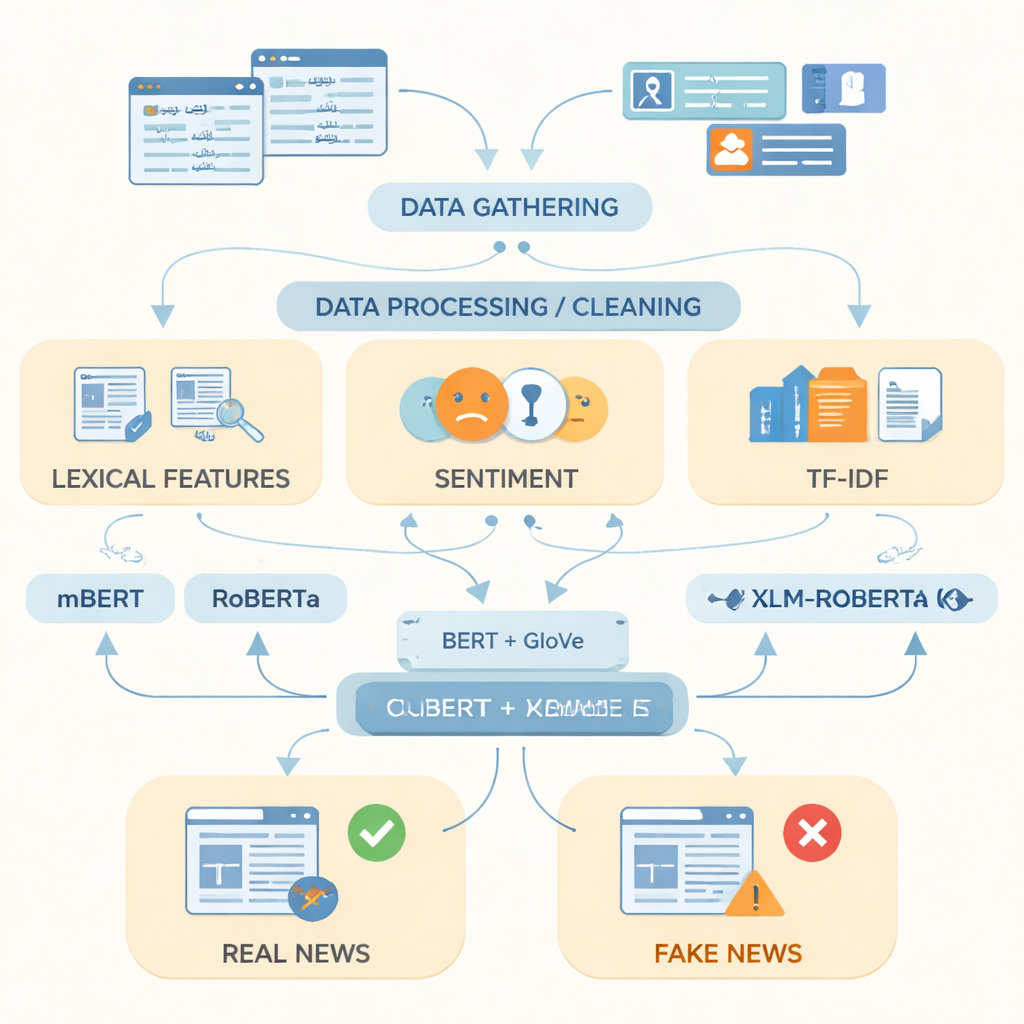
Att lära datorer hur falska nyheter ser ut
Efter att ha förberett data fokuserade författarna på hur man bäst representerar urdu-text för en dator. De kombinerade enkla indikatorer som frekvent använda ord, språkets känslomässiga ton och termfrekvenspoäng med två kraftfulla ordrepresentationsmetoder. Den ena, kallad GloVe, behandlar varje ord som en fast numerisk vektor baserad på hur ofta det förekommer tillsammans med andra ord i hela samlingen. Den andra, baserad på BERT-liknande modeller, ser på varje ord i dess sats och tilldelar det en kontextkänslig betydelse. Genom att förena dessa två språkperspektiv till en enda, rikare representation kan systemet fånga både övergripande mönster och subtila skiftningar i ordval som ofta skiljer falska från verkliga berättelser.
Att testa avancerade språkmodeller
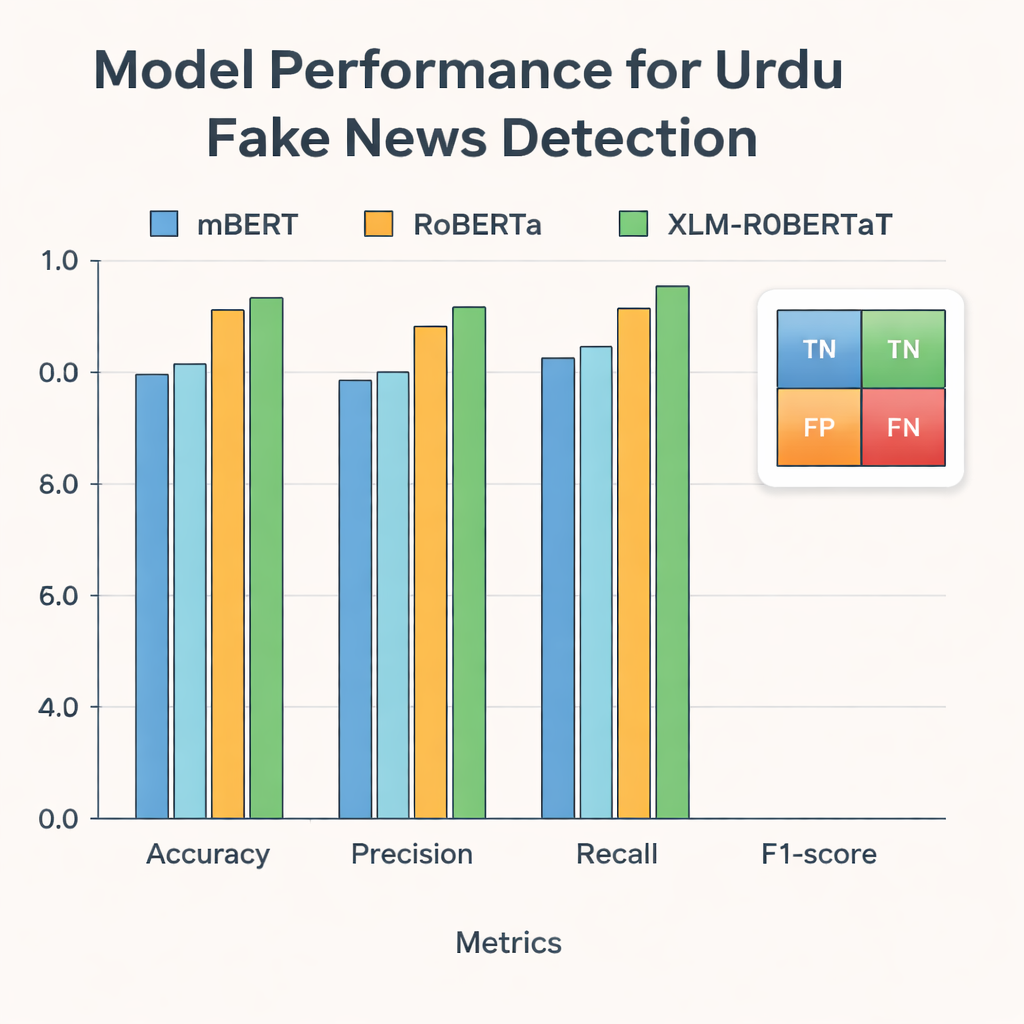
Forskarna matade sedan dessa representationer till tre moderna djupinlärningsmodeller som har tränats på text från många språk: mBERT, RoBERTa och XLM-RoBERTa. Alla tre finjusterades på urdu-datamängden för att förutsäga om varje artikel var riktig eller falsk. Deras prestanda bedömdes med standardmått: noggrannhet (hur ofta de hade rätt), precision (hur ofta flaggade falska faktiskt var falska), recall (hur många av alla falska berättelser de fångade) och F1-poäng, som balanserar precision och recall. Medan alla modeller presterade väl, var XLM-RoBERTa i kombination med den sammansatta BERT- och GloVe-representationen bäst och klassificerade rätt ungefär 96 procent av testartiklarna och nådde en F1-poäng på 0,956—bättre än tidigare urdu-system för falska nyheter som använde mindre datamängder eller enklare metoder.
Vad detta innebär för vardagliga läsare
För icke-specialister är budskapet enkelt: med tillräckligt högkvalitativ urdu-nyhetsdata och rätt typ av AI är det nu möjligt att bygga verktyg som automatiskt markerar sannolika falska berättelser med hög tillförlitlighet. Studien visar att rikare språkrepresentationer och flerspråkiga modeller ger datorer en mycket bättre förståelse för hur urdu faktiskt skrivs i olika regioner och ämnen. Även om det nuvarande arbetet fokuserar enbart på text och ännu inte analyserar bilder eller socialt beteende, lägger det en stark grund för framtida system som kan fungera över språk och medietyper. I praktiska termer förflyttar denna forskning Pakistan ett steg närmare webbläsartillägg, redaktionspaneler eller sociala mediefilter som hjälper människor att skilja fakta från fiktion på det språk de använder varje dag.
Citering: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Nyckelord: upptäckt av falska nyheter, urdu-språk, djupinlärning, BERT och GloVe, desinformation online