Clear Sky Science · sv
Förbättrad långdistansdjupuppskattning via heterogen CNN-transformer-kodning och tvärdimensionell semantisk fusion
Se djup med ett enda öga
Moderna robotar, självkörande bilar och drönare förlitar sig ofta på dyra 3D-sensorer för att avgöra hur långt bort saker befinner sig. Denna studie visar hur vanliga färgkameror, som de i smartphones, kan utnyttjas mycket mer: författarna utformar ett nytt sätt för en dator att härleda djup ur bara en bild, med fokus på den svåraste delen av scenen att få rätt—de stora avstånden, där hinder är små, suddiga och lätta att misstolka.
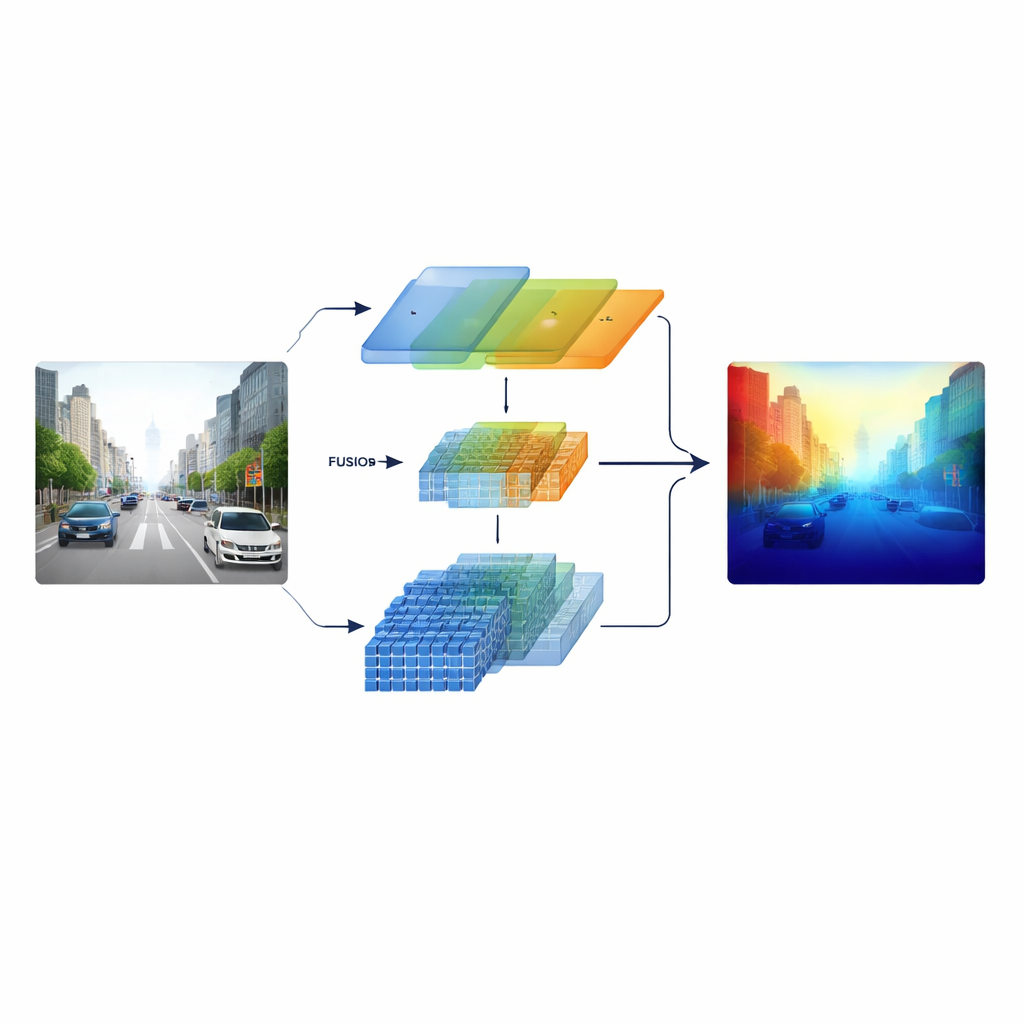
Varför avlägsna objekt är så svåra att bedöma
Djup från en enda bild, kallat monokulär djupuppskattning, är en form av visuell illusion. Närliggande objekt täcker många pixlar och har skarpa texturer, så dagens neurala nätverk presterar redan bra på korta och medellånga avstånd. Längre bort krymper däremot bilar till några få pixlar och vägmarkeringar tonar bort i dis. Standard convolutional neural networks är bra på att upptäcka fina lokala detaljer men har svårt att få in helheten av en hel gata. Nyare transformer-modeller fångar global kontext väl, men är mindre känsliga för små kanter och texturer. Som följd snubblar båda metodfamiljerna ofta precis där säker navigation mest behöver tillförlitliga uppskattningar: på långa avstånd.
Att blanda två sätt att se
Forskarna angriper detta genom att bygga en ”heterogen” encoder som kör två olika typer av visuell bearbetning parallellt. En gren bygger på ett klassiskt ResNet-liknande konvolutionsnät som specialiserar sig på krispiga lokala mönster såsom körfältsmarkeringar, stolpar och objektskanter. Den andra grenen använder en Swin Transformer, designad för att fånga långdistanskopplingar över bilden, såsom layouten av en vägkorridor eller silhuetten av avlägsna byggnader. Istället för att kombinera dessa två vyer endast i slutet behåller systemet flerskaliga funktioner från båda grenarna och för dem in i ett noggrant utformat fusionssteg, så att fin struktur och bred kontext påverkar varandra genom hela processen.
Korsa kanaler, rum och skala
I modellens kärna finns en Cross-dimensional Semantic Fusion-modul som fungerar som ett intelligent mötesrum för de två informationsströmmarna. Först avgör den vilka kanaler—olika typer av inlärda visuella mönster—som förtjänar mer uppmärksamhet och balanserar signaler från detaljerade texturer och högre nivåers scenledtrådar. Därefter undersöker den separat horisontella och vertikala riktningar, vilka är särskilt meningsfulla i scener fulla av vägar, byggnader och träd, för att framhäva viktiga strukturer som sträcker sig över bilden. Slutligen blandar den grunda, detaljrika funktioner med djupare, mer abstrakta över flera skalor. Ett lärbart viktsteg låter nätverket avgöra hur mycket det ska lita på varje gren för varje region, så att små, avlägsna objekt inte sopas under mattan av närliggande miljö.
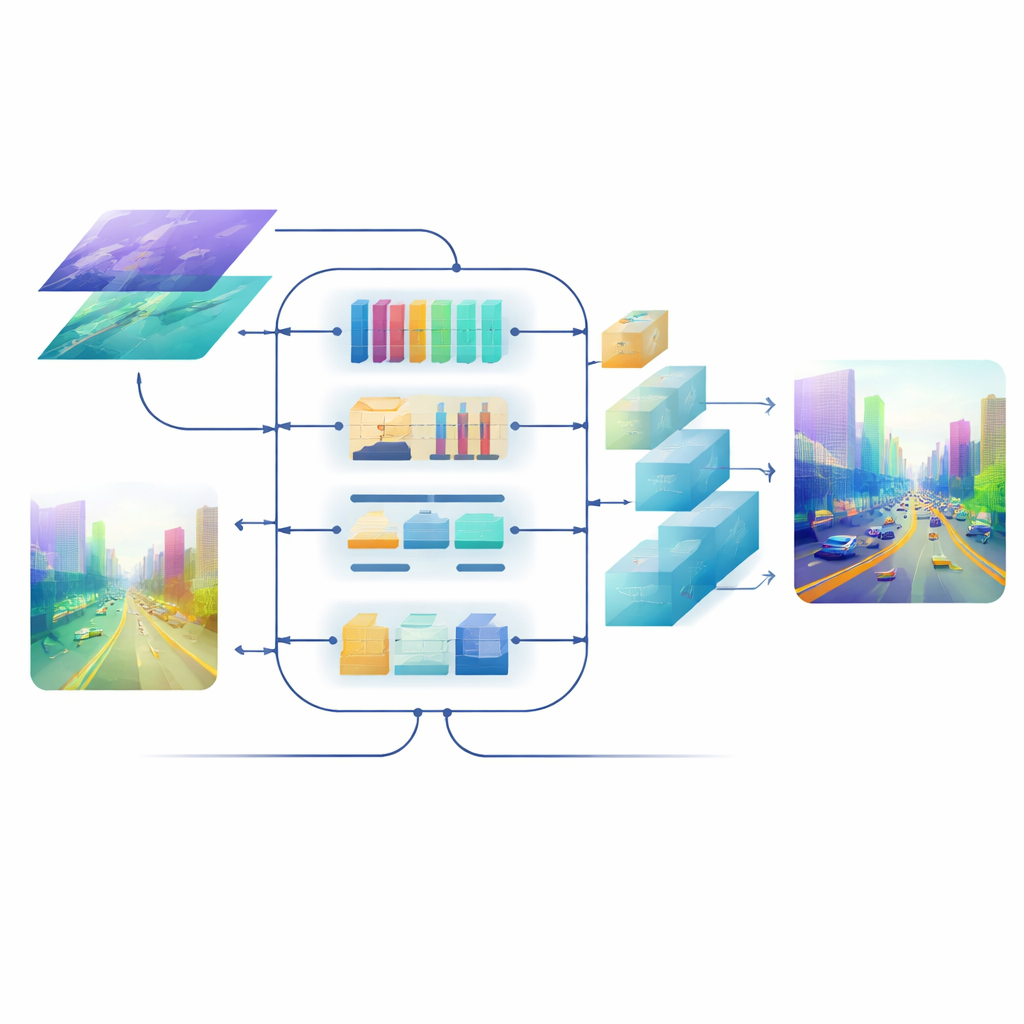
Skärpa upp slutbilden
Även med väl fuserade funktioner kan omvandlingen tillbaka till en fullupplöst djupkarta sudda ut kanter och tvätta bort tunna strukturer. För att undvika detta utformar teamet en uppmärksamhetsstyrd decoder. Dess uppsamplingsblock använder lättviktiga depth-wise-konvolutioner för att förstora kartan utan att förlora kontext, och en flerskalig självuppmärksamhetsmekanism grupperar funktionskanaler så att uppmärksamheten kan beräknas effektivt. Detta steg förfinar djupprediktioner vid varje skala samtidigt som beräkningen hålls i schack. Resultatet är ett jämnt, sammanhängande djupfält där objektgränser—som silhuetten av en avlägsen cyklist eller stegen på en våningssäng—förblir skarpa.
Hur bra fungerar det i verkligheten
Metoden testas på flera standarddatasätt. På KITTI, en stor samling körscener, uppnår modellen toppresultat på de flesta vanliga mätvärden och producerar, vilket är avgörande, den lägsta felet i angivna långdistansregioner. Den ger också renare djupgränser runt objekt än konkurrerande system. På NYU Depth V2, som innehåller inomhusscener, och på SUN RGB-D-benchmarken generaliserar samma modell framgångsrikt och rekonstruerar möbler och rumsindelningar i övertygande 3D-punktmoln. Ablationsstudier—systematiska tester som tar bort eller byter komponenter—visar att varje föreslaget element, från den hybrida encodern till fusionsmodulen och decoderns uppmärksamhetsblock, mätbart förbättrar prestanda, särskilt för avlägsna områden med låg textur.
Vad detta betyder för vardagsteknik
Kort sagt lär detta arbete ett neuralt nätverk att använda både ett förstoringsglas och ett vidvinkelobjektiv samtidigt, och att kombinera dem klokt. Genom att bättre balansera lokala detaljer med global scenförståelse förbättrar det föreslagna ramverket avsevärt hur väl en enda kamera kan bedöma djup långt fram på vägen eller i ett rum. Det gör det mer praktiskt att utrusta robotar, fordon och drönare med billigare sensorer samtidigt som de får en rik 3D-uppfattning av världen—ett viktigt steg mot säkrare, mer kapabla och mer prisvärda autonoma system.
Citering: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Nyckelord: monokulär djupuppskattning, datorseende, transformer- och CNN-fusion, självkörande fordon, 3D-scensrekonstruktion