Clear Sky Science · sv
Kernel mean matching förbättrar riskuppskattning vid rumsliga förskjutningar i distribution
Varför det spelar roll att modellera risk när kartorna förändras
Maskininlärningsmodeller används i allt större utsträckning för att förutsäga var arter kommer att finnas, hur tumörer är organiserade i vävnad eller hur föroreningar sprider sig. Men de data som används för att träna dessa modeller samlas ofta in på mycket specifika platser—täta provtagningar nära städer, sjukhus eller lättillgängliga fältlokaler—medan modellerna appliceras över mycket större, andra områden. Denna mismatch mellan var data kommer från och var förutsägelser görs kan få modeller att framstå som säkrare och mer precisa än de verkligen är. Artikeln "Kernel mean matching enhances risk estimation under spatial distribution shifts" ställer en till synes enkel fråga: när världen ser annorlunda ut än dina träningsdata, hur fel kan din modell bli, och hur kan du avgöra det?
När träning och test lever i olika världar
I statistik är en modells "risk" dess förväntade fel på nya, osedda data. Vanliga utvärderingstrick—som korsvalidering eller att hålla ut ett slumpmässigt testset—antar tyst att tränings- och testdata är dragna från samma distribution. Rumsliga data bryter mot detta antagande. Miljögradienter, klustrad provtagning och förändrade klimat gör att förhållandena där vi tränar en modell kan skilja sig kraftigt från där vi använder den. Till exempel koncentreras artobservationer ofta nära vägar, medan bevarandebeslut gäller avlägsna områden; tumörprover kan tas från en del av en vävnad men förutsägelser behövs på andra ställen. I sådana fall tenderar konventionella riskuppskattningar att vara överoptimistiska och dölja hur illa en modell kan misslyckas på nya platser.
Gamla verktyg har svårt med rumslig bias
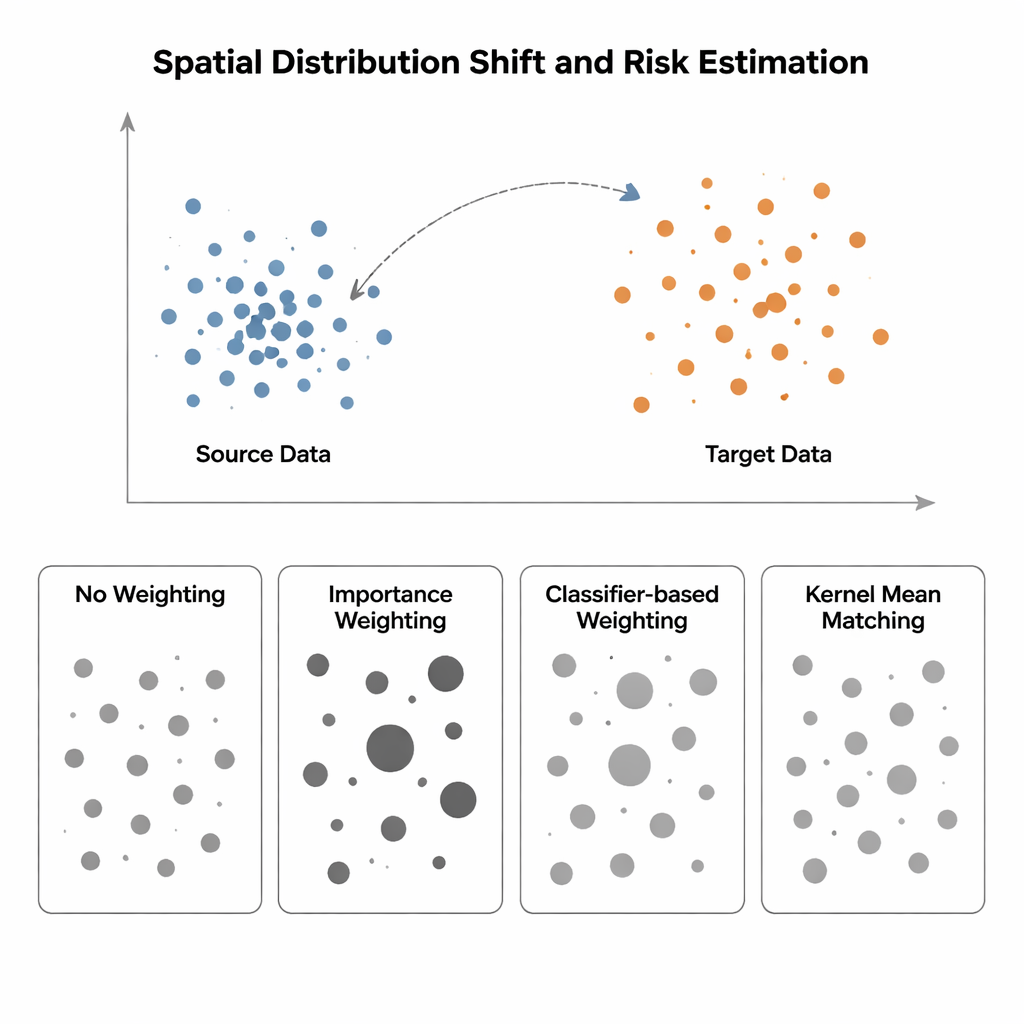
Studien jämför fyra sätt att uppskatta modellrisk när indatafördelningen skiftar från en "källa" (där etiketter är kända) till ett "mål" (där etiketter är sällsynta eller saknas). Den enklaste metoden, kallad No Weighting, mäter bara genomsnittligt fel på tillgängliga data och antar att källa och mål är likartade—ett antagande som faller samman vid rumslig bias. Importance Weighting försöker åtgärda detta genom att skala varje källprov efter hur vanligt den typen av punkt är i målet i förhållande till källan. I teorin återställer detta korrekt risk, men i praktiken kräver det uppskattning av högdimensionella tätheter. När källdata är tätt klustrade och måldata mer utspridda—en typisk situation inom rumslig ekologi eller medicinsk avbildning—blir dessa täthetsuppskattningar opålitliga, och några prov får enorma vikter vilket gör riskuppskattningen mycket instabil. Klassificerbaserade tillvägagångssätt, som tränar en klassificerare för att skilja käll- från målpunkt och omvandlar dess sannolikheter till vikter, undviker explicit täthetsuppskattning men ger ofta felkalibrerade risker eftersom de optimerar klassificeringsnoggrannhet, inte fördelningsanpassning.
En annan väg: matcha fördelningar direkt
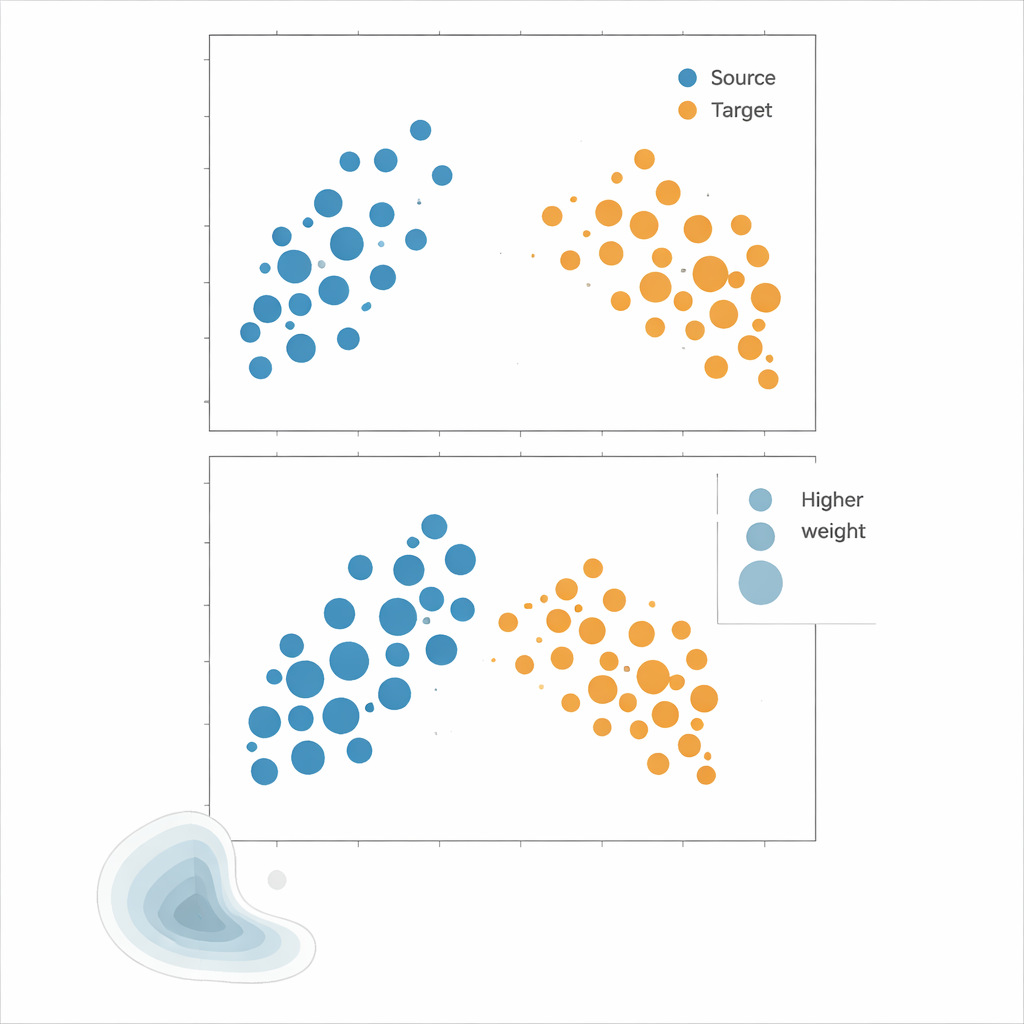
Författarna förespråkar Kernel Mean Matching (KMM), ett angreppssätt som kringgår täthetsuppskattning helt. Istället för att försöka beräkna hur sannolik varje punkt är under källa- och målfördelningar, söker KMM efter vikter på källproven som får deras genomsnittliga "signatur" i ett flexibelt, kerneldefinierat funktionsrum att matcha den hos målproven. Intuitivt drar eller skjuter det på inflytandet av varje källpunkt så att den vägda källmolnet tillsammans liknar målmolnet. När dessa vikter hittats uppskattas risken som ett viktat medel av källans fel. Ett kompletterande verktyg, den lokala korrelationsfunktionen, kvantifierar hur klustrade data är i rummet; den fungerar som en diagnos för att avgöra när förskjutningar i fördelningen är tillräckligt starka för att omviktning sannolikt ska hjälpa.
Sätta metoderna på prov
För att se vilken strategi som fungerar bäst kör författarna omfattande experiment på både syntetiska och verkliga data. Syntetiska "landskap" byggs av blandningar av Gaussiska kluster vars utbredning, form och domäntäckning kan kontrolleras exakt, vilket möjliggör strukturerade tester som att beskära delar av domänen, ändra korrelationsmönster mellan funktioner eller växla mellan tätt klustrade och nästan uniforma punktmönster. Verkliga dataset inkluderar nordiska växtarters förekomster, beskrivna av klimat och plats, samt rumsliga fördelningar av immunceller inom tumörer. I dessa scenarier tränas modeller på klustrade källdata och utvärderas på mindre klustrade måldata, vilket efterliknar vanliga provtagningsbiaser. Prestanda bedöms med flera felmått, med fokus på hur väl varje metods uppskattade risk följer det sanna felet på målet.
Mer tillförlitlig risk i stökiga, högdimensionella rum
I nästan alla syntetiska uppsättningar och verkliga dataset ger KMM de mest precisa och stabila riskuppskattningarna. Den minskar medelfelprocenten (mean absolute percentage error) med ungefär 12 till 87 procent jämfört med alternativen och undviker kritiskt den "viktexplosion" som plågar importance weighting i höga dimensioner. I utmanande tumöruppställningar kan importance weighting till exempel ge fel som överstiger flera tusen procent, medan KMM håller sig inom hanterbara gränser. Klassificerbaserad omviktning förbättrar vanligen jämfört med naiva metoder men hänger fortfarande efter KMM, vilket speglar dess fokus på diskriminering snarare än trogen fördelningsmatchning. Dessa resultat tyder på att för rumsliga tillämpningar—där data är klustrade, skeva och högdimensionella—erbjuder KMM ett principfast sätt att uppskatta hur mycket förtroende man kan lägga i en modells förutsägelser.
Vad detta betyder för beslut i verkliga världen
För icke-specialister som använder maskininlärning inom ekologi, miljövetenskap eller biomedicin är budskapet enkelt: standardtestpoäng kan vara farligt vilseledande när ditt användningsområde skiljer sig från var dina data kom ifrån. Kernel Mean Matching ger ett sätt att korrigera för detta genom att ombalansera inflytandet från träningsprover så att de statistiskt liknar de platser eller vävnader du bryr dig om. Studien visar att detta tillvägagångssätt konsekvent ger ärligare uppskattningar av modellfel, även under svår rumslig bias och med många ingående variabler. I praktiken innebär det mer tillförlitlig vägledning vid val mellan modeller och en tydligare bild av var förutsägelser är pålitliga—och var försiktighet bör iakttas.
Citering: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Nyckelord: distributionsförskjutning, rumslig modellering, kernel mean matching, modellriskuppskattning, ekologiska och biomedicinska data