Clear Sky Science · sv
Förbättrad motståndskraft mot angrepp i semantisk cache för säkra system med retrieval-augmented generation
Varför smartare AI-minne spelar roll
När chattbotar och AI-assistenter tar plats på arbetsplatser, i klassrum och till och med på sjukhus förlitar de sig i allt större utsträckning på ett knep som kallas att “komma ihåg” tidigare frågor för att kunna besvara liknande frågor snabbare och billigare. Detta minne, känt som en semantisk cache, kan dramatiskt minska kostnader och fördröjningar — men det kan också öppna en bakdörr för angripare att lura system att läcka hemligheter eller ge felaktiga svar. Denna artikel utforskar dessa dolda risker och presenterar en ny design, SAFE-CACHE, som syftar till att behålla AI:s snabba minne samtidigt som det blir mycket svårare att missbruka.
Hur dagens AI-assistenter återanvänder tidigare svar
Moderna stora språkmodeller (LLM) arbetar ofta i en arkitektur som kallas retrieval-augmented generation (RAG). När du ställer en fråga söker systemet först upp relevanta dokument och låter sedan LLM skapa ett svar utifrån det materialet. Eftersom många människor ställer i stort sett samma fråga med olika ord, lägger företag nu till en semantisk cache: en lagringsplats för gamla frågor och svar, samt matematiska fingeravtryck av deras betydelser. När en ny fråga kommer in kontrollerar systemet om dess fingeravtryck är “tillräckligt nära” ett som redan finns i cachen; i så fall återanvänder det helt enkelt det gamla svaret istället för att köra hela sök- och genereringsprocessen igen. Denna idé, som används i verktyg som GPTCache och i molnplattformar från Microsoft och Google, sparar pengar och snabbar upp svar för kundtjänstbotar, företagschattverktyg och andra AI-tjänster med hög trafik. 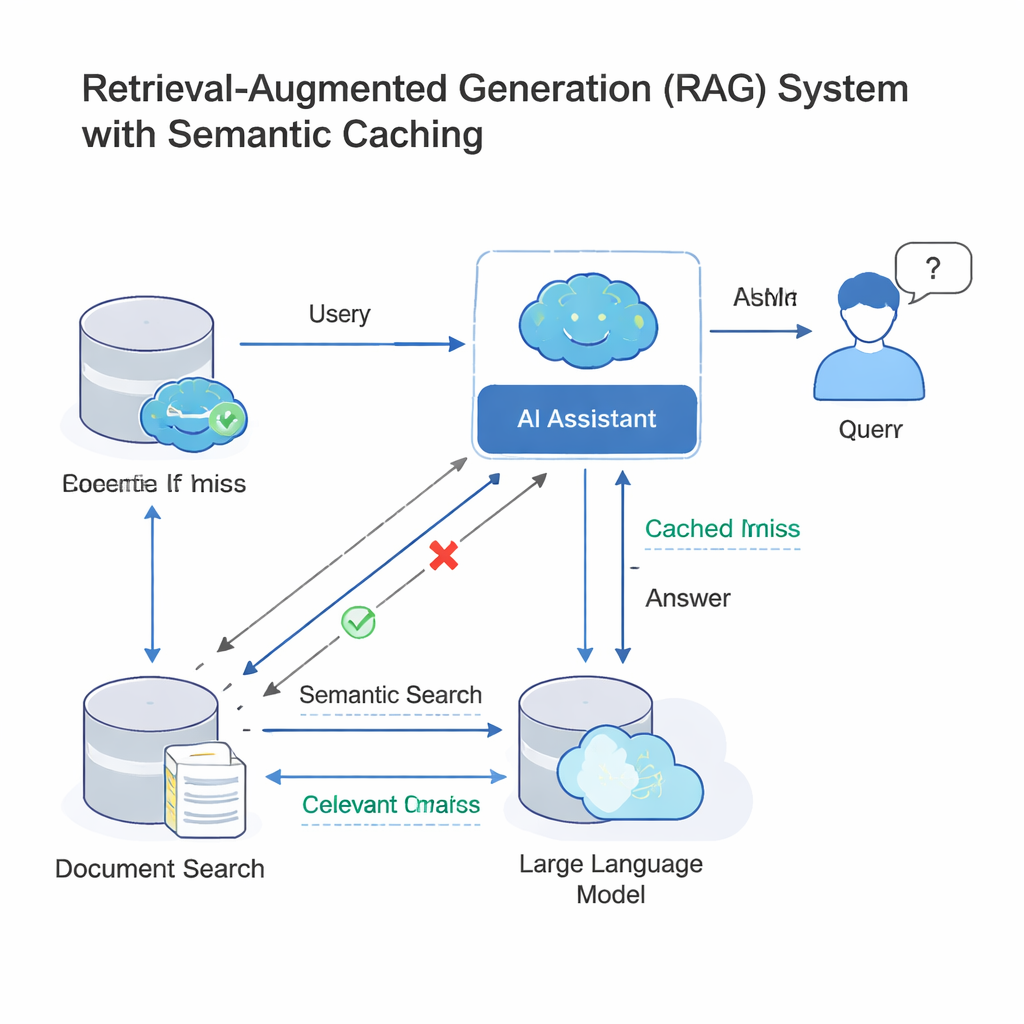
När skicklig formuleringskonst blir ett säkerhetshål
Samma genväg som ökar hastigheten kan också vändas mot systemet. Angripare kan skapa frågor som ser lika ut i struktur men betyder något annat — ändra ett datum, byta ut en person eller plats, eller vända innebörden i en fråga. Eftersom dagens cacher till stor del litar på numerisk likhet i embeddingar (de där betydelsefingeravtrycken), kan en illasinnad fråga “krocka” med en ofarlig i detta vektorrum, även om avsikten har förändrats. Denna kollision kan få cachen att returnera fel svar, potentiellt exponerande konfidentiell information eller låta skadliga data lagras för senare återanvändning. Tidigare arbete har redan visat att vektordatabaser och semantiska cacher kan förgiftas på detta sätt, särskilt när många användare delar samma underliggande cache i multitenant-system.
Att förvandla spridda frågor till stabila avsiktskluster
Författarna menar att grundproblemet är att behandla varje fråga isolerat. Deras lösning, SAFE-CACHE, grupperar tidigare fråga–svar-par i kluster som representerar underliggande avsikter — som “vem vann senatsvalet i Arizona 2022?” eller “vad är priset för Teslas Full Self-Driving-program?” Istället för att matcha nya frågor direkt mot enskilda gamla, jämför SAFE-CACHE dem med centrumet, eller centroiden, för varje kluster. För att bygga dessa kluster embedderar systemet först varje fullständigt fråga-plus-svar (inte bara frågan) så att skillnader i svar — till exempel ett vägran att avslöja känslig data — också påverkar grupperingarna. Därefter används en community-detekteringsalgoritm för att hitta naturliga kluster och statistiska tester för att flagga brusiga grupper som kan blanda olika avsikter eller innehålla adversariella inlägg. Dessa misstänkta kluster rengörs och delas upp med hjälp av en specialtränad bi-encoder som lärt sig att föra ihop ärliga exempel och skilja bort förgiftade sådana.
Att lära en liten modell stärka AI:s minne
Vissa avsikter förekommer bara ett fåtal gånger i den verkliga trafiken, vilket gör deras kluster sköra. För att stabilisera dem använder SAFE-CACHE en finkalibrerad lättvikts språkmodell (en 1-miljard-parameter-version av Gemma-3) för att generera parafraser som behåller samma avsikt samtidigt som formuleringen varierar. Dessa extra exempel gör klustren tätare och deras centroid mer pålitliga, utan att behöva att människor märker tusentals varianter. Vid körning embedderas varje ny fråga och jämförs med dessa centroider. Om likheten med den bäst matchande centroiden överstiger en noggrant inställd tröskel returneras det cachade svaret; annars faller systemet tillbaka på hela RAG-pipelinen och beslutar senare hur det nya paret ska klustras. I experiment med starka angreppsmetoder baserade på metamorf omskrivning och GPT‑4.1 minskade SAFE-CACHE antalet lyckade förgiftningsförsök med ungefär två tredjedelar till tre fjärdedelar jämfört med en GPTCache-liknande design, samtidigt som svarstiden i huvudsak förblev oförändrad. 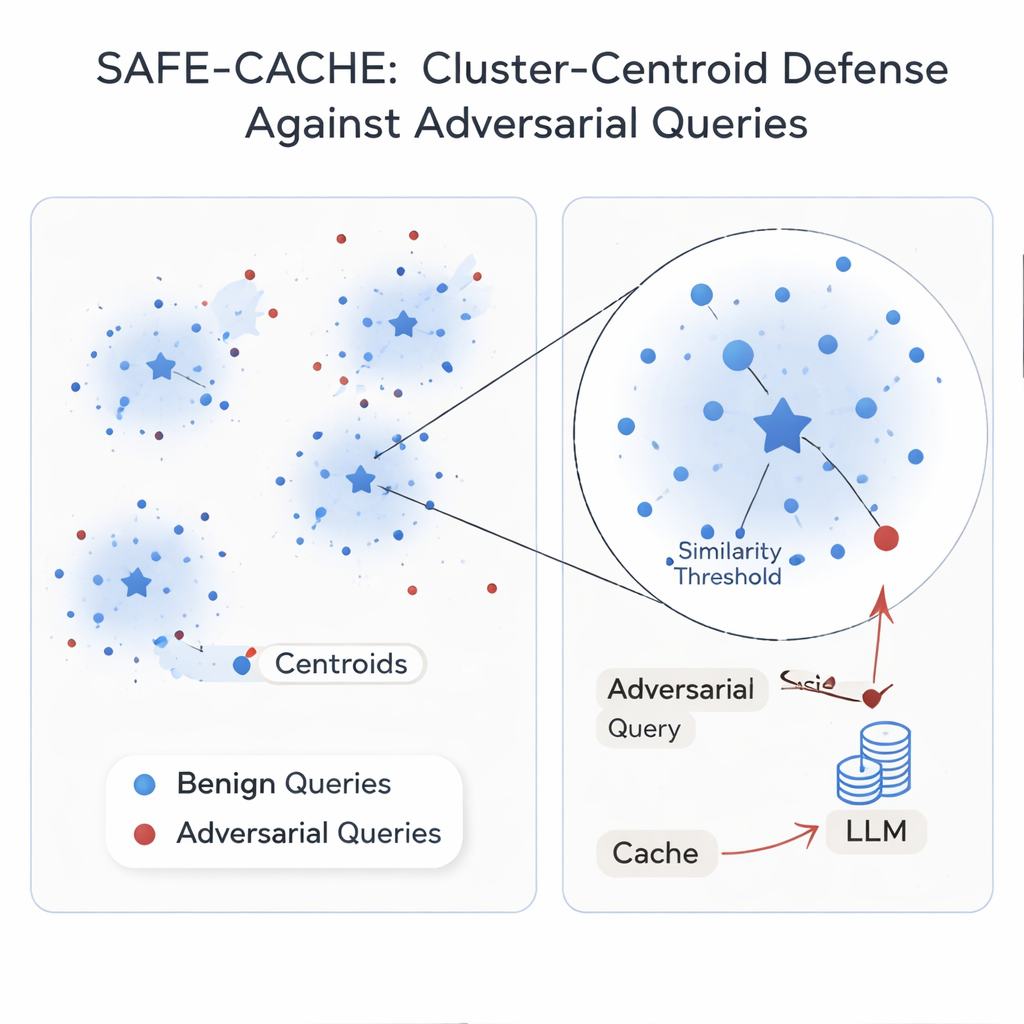
Vad detta betyder för vanliga AI-användare
För icke-specialister är slutsatsen att att ge AI-system “minne” inte är gratis: naiva designer kan läcka hemligheter eller luras att sprida felaktiga svar. SAFE-CACHE visar att genom att organisera minnet kring djupare, avsiktsnivåmönster och förstärka dessa mönster med riktade parafraser, är det möjligt att behålla hastighets- och kostnadsfördelarna med semantisk caching samtidigt som risken för angrepp kraftigt minskas. När AI-assistenter blir en entrédörr till känsliga data — från företagsregister till personlig information — kommer tillvägagångssätt som SAFE-CACHE att vara avgörande för att säkerställa att det AI minns inte enkelt kan vändas mot oss.
Citering: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Nyckelord: semantisk cache, retrieval-augmented generation, fiendtliga angrepp, klusterbaserat försvar, LLM-säkerhet