Clear Sky Science · sv
Semantisk medveten självövervakad inlärning med progressiv subaktionsregression för bedömning av actionkvalitet
Att se prestationer genom en ny lins
När vi ser olympiska hoppares eller andra elitidrottare uppfattar vi intuitivt vem som presterade bättre, men att omvandla den känslan till objektiva siffror är svårt. Dagens automatiserade videosystem kan tilldela en övergripande ”poäng” åt en handling, men förklarar sällan varför ett hopp var bra eller dåligt, eller vilken del som behöver förbättras. Denna artikel presenterar ett nytt sätt för datorer att betrakta komplexa handlingar i video, dela upp dem i begripliga delar och poängsätta varje del separat—vilket ger återkoppling närmare det en mänsklig tränare skulle ge.

Att dela upp ett komplext moment i hanterbara delar
Många nuvarande verktyg för bedömning av actionkvalitet behandlar ett helt hopp eller rörelsemönster som en enda enhet och ger bara en sammanlagd poäng. Det döljer avgörande detaljer: en hoppare kan få en perfekt avstamp men en dålig vattenkontakt, och en enskild siffra kan inte avslöja detta. Författarna tar sig an detta genom att lära systemet att dela varje video i meningsfulla stadier, eller subaktioner, såsom start, avstamp, flygning och vatteningång. Viktigt är att denna uppdelning görs automatiskt, utan mänsklig märkning av var ett stadium slutar och nästa börjar. En osuperviserad klustringsmetod grupperar närliggande bildrutor som ”beter sig” likartat över tid och ger systemet en grov men tillförlitlig storyboard av prestationen.
Låta systemet lära sig vad som är viktigt
När videon har delats upp i stadier behöver systemet förstå hur varje stadium ser ut när det utförs bra respektive dåligt. Istället för att förlita sig på täta, handgjorda etiketter använder författarna självövervakad inlärning: modellen visas många varianter av samma subaktion där segment av bildrutor avsiktligt tas bort eller ”maskas”. Systemet måste ändå producera liknande interna beskrivningar för både de kompletta och de delvis saknade klippen. Genom att lära sig att bortse från dessa artificiella luckor blir det robust mot verkliga problem som korta ocklusioner, förlorade bildrutor eller något osäkra stadiegränser, samtidigt som det lär sig fokusera på de väsentliga rörelse- och hållningsmönster som definierar kvalitet.
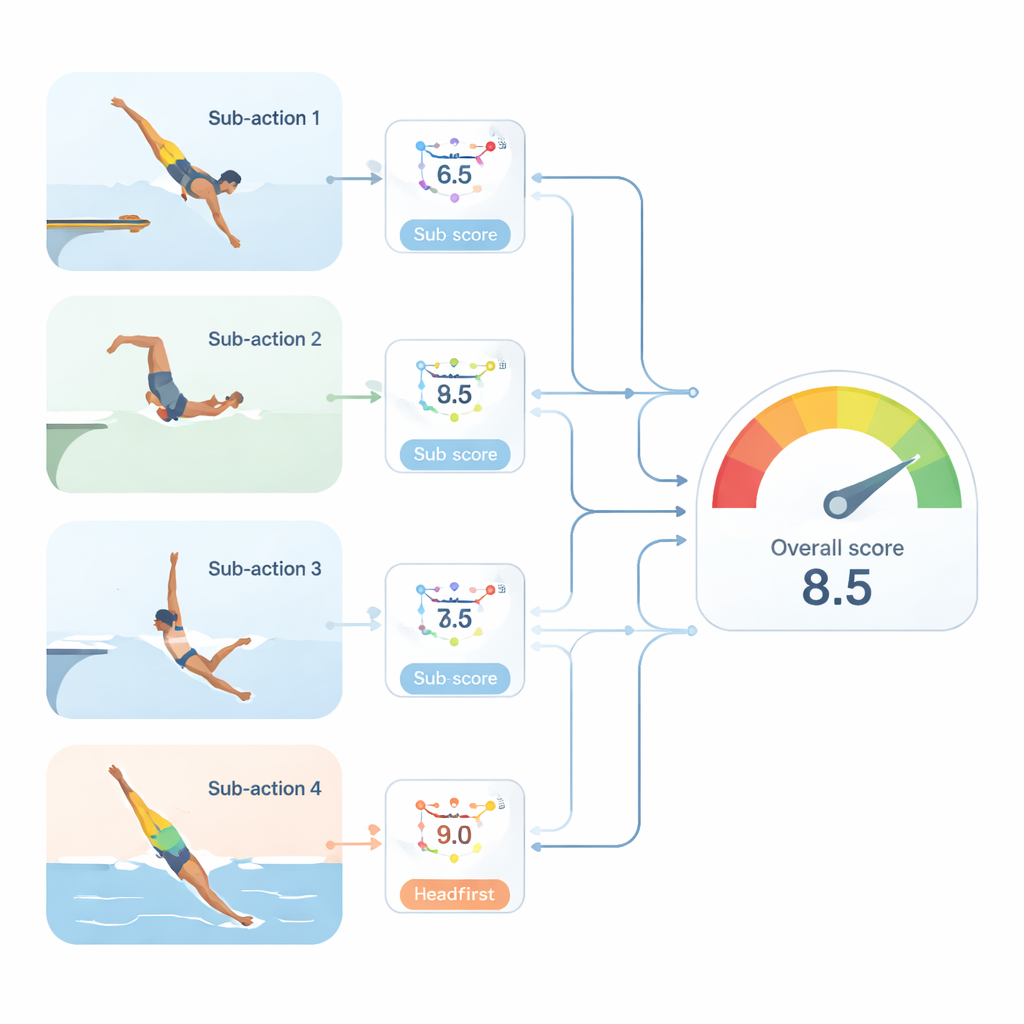
Från en totalpoäng till många användbara delpoäng
Verkliga dataset innehåller vanligtvis bara en enda totalpoäng för varje hopp, inte separata betyg för varje stadium. För att övervinna detta introducerar författarna en progressiv strategi med ”pseudo-delpoäng”. Först slår de ihop totalpoängen med de nyinlärda funktionerna för varje subaktion och tränar små nätverk för att gissa en preliminär poäng för varje stadium. Sedan förfinar de dessa gissningar genom att tillåta informationsflöde längs sekvensen: varje stadies representation uppdateras med hjälp av tidigare stadiers poäng, vilket fångar hur ett litet fel vid avstamp kan slå igenom i flygning och vatteningång. I en andra variant får varje stadium tillgång till alla tidigare stadiepoäng, vilket modellerar långsiktiga orsak-och-verkan-effekter i handlingen. Slutligen kombinerar ett kompakt regressionsnätverk de förfinade stadiepoängen till en övergripande prediktion, nu utan att behöva se den faktiska totalpoängen som input.
Testat på riktiga simhoppstävlingar
Forskarna utvärderade sitt ramverk på två krävande hoppset inspelade från stora internationella tävlingar. Dessa samlingar innehåller totalpoäng från mänskliga domare och i vissa fall grova tidpunkter för stadier, men inga kvalitetsetiketter på stadienivå. Den nya metoden uppnådde bästa-i-klassen rangordningskorrelation, vilket innebär att dess ordning av idrottare ligger nära expertdomarnas, samtidigt som numeriska fel i de förutsagda poängen minskade. Noggranna ”ablation”-tester visade att båda huvudidéerna—självövervakad funktionsförfining och progressiv pseudo-delpoängsmodellering—bidrar med betydande förbättringar. Anmärkningsvärt är att användning av automatiska stadiegränser presterade nästan lika bra som noggranna mänskliga annoteringar, vilket indikerar att systemet är tåligt mot ofullständig segmentering.
Att omvandla siffror till insiktsfulla träningsråd
Utöver noggrannhet gör detta tillvägagångssätt automatiserad poängsättning mer tolkbar. Genom att tilldela en separat poäng till varje stadium i ett hopp kan systemet till exempel belysa att två hoppare har liknande avstamp och flygfas men skiljer sig kraftigt vid vatteningången, där den ena skapar en stor stänk. Analys av många prov bekräftar att dessa stadiepoäng följer samma prioriteringar som mänskliga domare, där vatteningången ofta bär mest vikt. I praktiska termer kan metoden peka ut exakt vilken del av en prestation som behöver förbättras, samtidigt som den kan tränas på relativt enkla dataset. Även om den demonstrerats på simhopp är konceptet tillräckligt flexibelt för att utsträckas till andra flerstegsuppgifter—från kirurgiska ingrepp till rehabiliteringsövningar—där förståelsen för hur varje segment bidrar till helhetskvaliteten är avgörande.
Citering: Mazruei, M., Fazl-Ersi, E., Vahedian, A. et al. Semantic-aware self-supervised learning using progressive sub-action regression for action quality assessment. Sci Rep 16, 6670 (2026). https://doi.org/10.1038/s41598-026-36668-y
Nyckelord: bedömning av actionkvalitet, analys av sportvideo, självövervakad inlärning, bedömning av mänsklig rörelse, djupinlärning för coaching