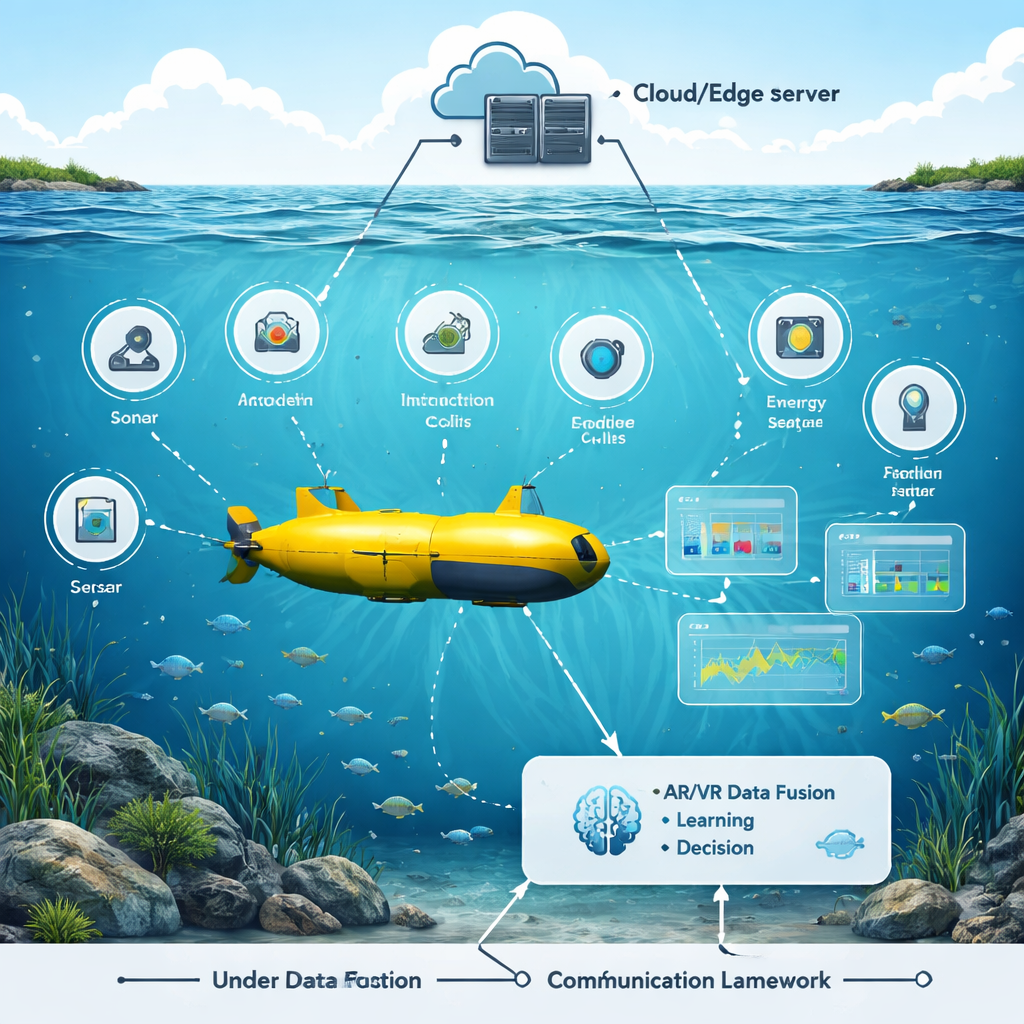
På havsbotten fungerar autonoma undervattensfarkoster som våra ögon och öron för klimatforskning, inspektion av infrastruktur och sök‑ och räddningsuppdrag. Dessa robotubåtar brottas dock med ett grundläggande problem: att kommunicera och resonera klart i en hård miljö där signaler är långsamma, brusiga och energiresurserna knappa. Denna artikel presenterar ett nytt sätt att hjälpa undervattensrobotar kommunicera, upptäcka föremål och hålla sig säkra genom att kombinera förstärkt och virtuell verklighet med en gren av artificiell intelligens som kallas förstärkningsinlärning.
Varför undervattenskommunikation är så svårt
Att skicka data under vatten är mycket svårare än att skicka dem genom luften. Radiovågor, som driver Wi‑Fi och 5G, absorberas snabbt av havsvatten. Akustiska (ljudbaserade) signaler når längre men erbjuder mycket låga datahastigheter och kan fördröjas, ge eko eller bli förvrängda. Magnetisk induktion fungerar bara över tiotals meter. Befintliga styrsystem för undervattensrobotar behandlar ofta dessa kanaler separat och använder fasta regler för navigering och sensordata. Det gör dem långsamma att anpassa sig när förhållandena ändras, slösar batteri och lämnar kommunikationslänkar sårbara för avlyssning eller attacker.
Ett virtuellt hav för att träna bättre instinkter Figure 1.
Författarna byggde en testbädd med förstärkt och virtuell verklighet som återskapar en livlig undervattensmiljö: rörliga fiskar, stenar, båtar och bojar, tillsammans med realistiskt brus och signalförluster i vattnet. Ett simulerat undervattensfordon färdas genom denna miljö med många sensorer—sonar, kameror, akustiska modem, energimätare och positionsspårare. I den virtuella scenen kan forskare dra reglage för att ändra objektpositioner, vattenförhållanden och sensorinställningar och omedelbart se hur roboten reagerar. Detta AR/VR‑lager är inte bara ögongodis; det sammanfogar råa sensorflöden till en enhetlig 3D‑bild som är lättare för ett AI‑system att förstå och agera utifrån.
Att lära roboten genom erfarenhet
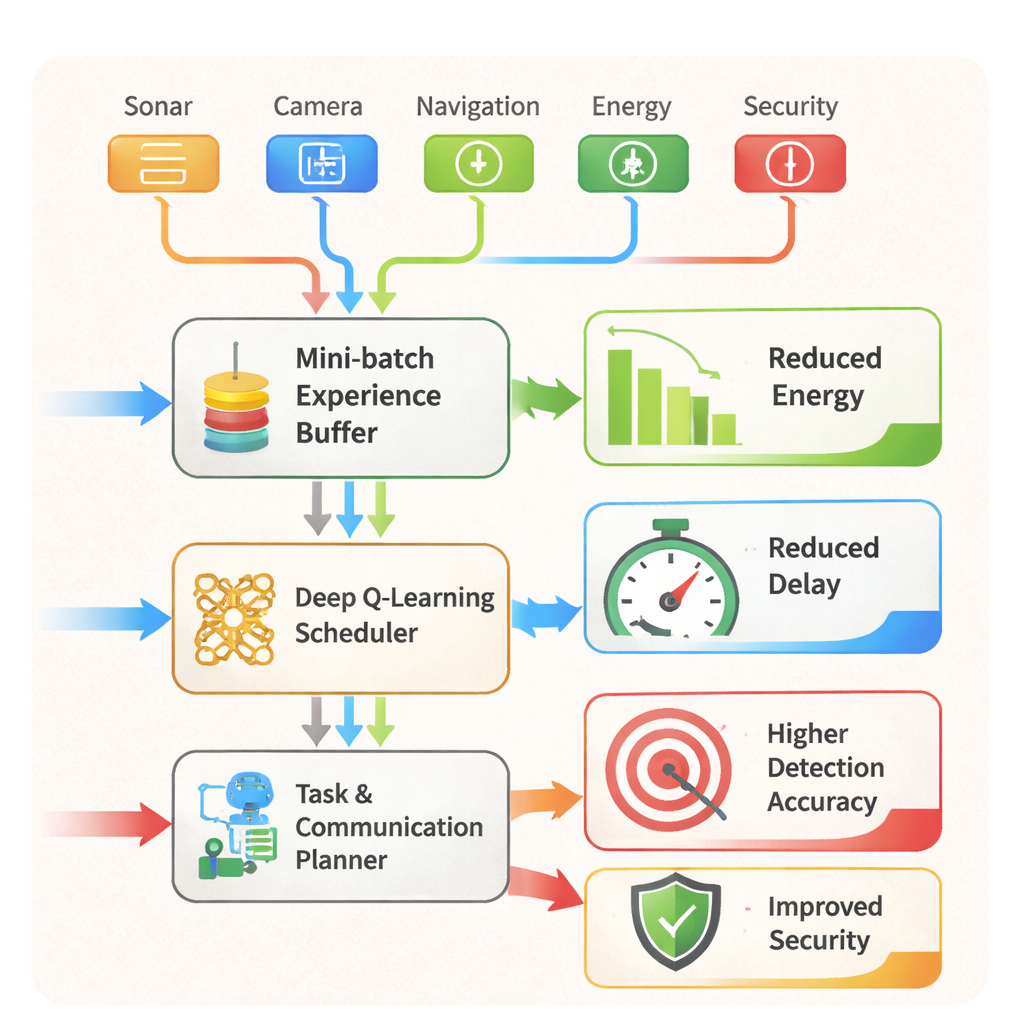
I kärnan av ramen ligger en AI‑strategi som författarna kallar Adaptive Augmented Reality and Reinforcement Learning Scheduling Strategy (AARLSS). Istället för att följa ett fast manus lär sig roboten genom försök och misstag i det virtuella havet. Varje ögonblick observerar den sitt sammansmälta sensorläge, väljer en åtgärd (såsom att ändra kurs, justera sensorsamplingsfrekvensen eller växla mellan kort- och långdistanskommunikation) och får en belöning. Den belöningen balanserar fyra mål: spara energi, minska fördröjning, sänka säkerhetsrisken och använda färre beräknings‑ och nätverksresurser. Ett djupt Q‑inlärningsnätverk lagrar och uppdaterar det förväntade värdet av olika beslut, med mini‑batcher av tidigare upplevelser i ett uppspelningsminne så att roboten kan lära sig både från nyliga och äldre situationer.
Från smart schemaläggning till säkrare uppdrag Figure 2.
AARLSS fungerar också som en realtidsschemaläggare. Den avgör vilka uppgifter—navigering, objektdetektion, kommunikation eller säkerhetskontroller—som ska köras var och när, och om data ska bearbetas på roboten, avlastas till en kantserver eller fördröjas. Utöver detta skannar ett inbyggt intrångsdetekteringssystem kontinuerligt mönster i sensor‑ och nätverksdata för att flagga anomalier som kan signalera en attack eller funktionsfel, och kan utlösa skyddsåtgärder som att blockera riskfyllda länkar eller tvinga lokal bearbetning. I tester inom AR/VR‑simulatorn överträffade ramen flera etablerade förstärkningsinlärningsmetoder. Den minskade undervattensfordonets energiförbrukning med cirka 20 %, reducerade kommunikations‑ och uppgiftsfördröjningar med omkring 18–20 %, och pressade objektdetekteringsnoggrannheten till ungefär 97–98 %, även under komplexa manövrar och i röriga scener.
Vad detta betyder för verkliga hav
För icke‑specialister är budskapet att denna forskning pekar mot undervattensrobotar som är mer självständiga, effektiva och pålitliga. Genom att träna i ett rikt virtuellt hav och lära sig att jonglera energi, tid, noggrannhet och säkerhet samtidigt, tillåter AARLSS ett fordon att välja när det ska tala, när det ska lyssna och när det ska vara tyst för att spara energi—samtidigt som det håller noggrann uppsikt över omgivningen och skyddar sina data. Även om dessa resultat kommer från en avancerad simulator snarare än öppet vatten, antyder de att framtida flottor av undervattensrobotar kan hantera längre, säkrare och mer dataintensiva uppdrag med mindre mänsklig tillsyn, vilket förbättrar allt från marinvetenskap till inspektioner inom offshore‑industrin.
Citering: Lakhan, A., Mohammed, M.A., Ghani, M.K.A. et al. A novel augmented reality and reinforcement learning empowered communication framework for underwater unmanned autonomous vehicle.
Sci Rep16, 6241 (2026). https://doi.org/10.1038/s41598-026-36647-3
Nyckelord: undervattensrobotik, autonoma undervattensfarkoster, förstärkningsinlärning, förstärkt verklighet, undervattenskommunikation